《中邮消费金融》专题
-
如果处理失败,如何将STOMP消息重新传递给消费者?
高层体系结构 JMS(生产者/消费者)<---->Artemis(STOMP)<---->Websocket-Broker-Relay-Service<---->STOMP-over-Websocket-client(生产者/消费者)
-
如何在一段时间间隔后从Kafka消费者处读取消息
在我的Spring启动应用程序中,我有kafka消费者类,每当主题中有可用消息时,它会频繁读取消息。我想限制消费者每隔2小时消费一次消息。就像阅读完一条消息后,消费者将暂停2小时,然后再消费另一条消息。这是我的消费者配置方法:- 然后我创建了这个容器方法,在其中我设置了kafka配置的其余部分 使用此代码分区每2小时重新平衡一次,但它根本没有读取消息。我的kafka消费者方法:-
-
外行的Java 8供应商和消费者说明
问题内容: 作为学习Java的非Java程序员,我现在正在阅读和接口。而且我无法理解它们的用法和含义。什么时候以及为什么要使用这些接口?有人可以给我一个简单的外行例子吗?我发现Doc例子不够简洁,无法理解。 问题答案: 这是供应商: 这是消费者: 因此,用通俗易懂的术语来说,供应商是一种返回一些值(如返回值)的方法。而使用者是一种消耗一些值(如在方法参数中)并对其执行一些操作的方法。 这些将转变为
-
Java使用队列的生产者/消费者线程
问题内容: 我想创建某种线程应用程序。但是我不确定在两者之间实现队列的最佳方法是什么。 因此,我提出了两个想法(这两个想法可能都是完全错误的)。我想知道哪种更好,如果它们都烂了,那么实现队列的最佳方法是什么。我关心的主要是这些示例中队列的实现。我正在扩展一个内部类的Queue类,它是线程安全的。下面是两个示例,每个示例有4个类。 主班 消费阶层 生产者类别 队列类 要么 主班 消费阶层 生产者类别
-
python kafka 多线程消费者&手动提交实例
本文向大家介绍python kafka 多线程消费者&手动提交实例,包括了python kafka 多线程消费者&手动提交实例的使用技巧和注意事项,需要的朋友参考一下 官方文档:https://kafka-python.readthedocs.io/en/master/apidoc/KafkaConsumer.html 以上这篇python kafka 多线程消费者&手动提交实例就是小编分享给大家
-
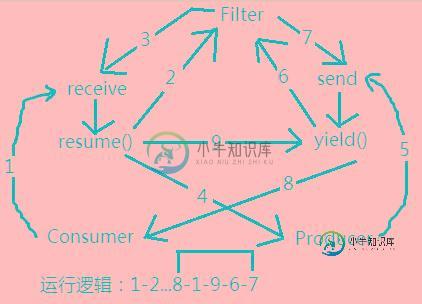 Lua编程示例(八):生产者-消费者问题
Lua编程示例(八):生产者-消费者问题本文向大家介绍Lua编程示例(八):生产者-消费者问题,包括了Lua编程示例(八):生产者-消费者问题的使用技巧和注意事项,需要的朋友参考一下 这个问题是比较经典的啦,基本所有语言的多线程都会涉及到,但是没想到Lua的这个这么复杂 抓狂 看了好长时间才算看明白,先上个逻辑图: 开始时调用消费者,当消费者需要值时,再调用生产者生产值,生产者生产值后停止,直到消费者再次请求。设计为消费者驱动
-
Springboot Kafka @Listener消费者暂停/恢复不起作用
我有一个Spring靴Kafka消费者 为了避免重新平衡,我尝试在KafkaContainer上调用pause()和resume(),但消费者总是在运行 我错过了什么吗?有人能指导我如何正确地达到要求的行为吗?
-
AMQP&OpenWire-ActiveMQ代理和2个不同的消费者
我有一个支持amqp和OpenWire的activeMQ代理。openwire(tcp,端口61616)的生产者有可能生产到一个队列,该队列的消费者使用amqp协议吗? 或者我只限于相同的协议消费者和生产者?
-
redis在消费者群体内进行有序处理
我将python(aioredis)与redis streams一起使用。 我有一个一个生产者-多个(分组)消费者的场景,并希望确保消费者以有序的方式处理发送到流的(批量)消息,这意味着:当第一条消息完成时,处理流中的下一条消息,依此类推。这也意味着消费者组中的消费者在某一时间正在处理,而其他消费者将等待。 我还希望依赖于第二、第三等消费群体中的有序处理——所有这些都依赖于发送到一个流的相同消息。
-
使用ThreadPoolExecutor的同步任务生产者/消费者
我试图找到一种在以下场景中使用ThreadPoolExecutor的方法: 我有一个单独的线程在线程池中生成和提交任务 为了提供更多的上下文,我目前只需一次提交所有任务,并取消ExecutorService返回的所有未来。在最长生成时间到期后提交。我忽略所有产生的取消异常,因为它们是预期的。问题是未来的行为。cancel(false)很奇怪,不适合我的用例: 它可以防止任何未启动的任务运行(良好)
-
Weblogic到JBoss JNDI-JMS队列消费者和发布者
我正在研究一个示例,其中JMS队列托管在JBoss EAP 6实例上(一个用于请求,另一个用于响应)。我还有一个在Weblogic托管服务器上运行的应用程序。 我想设置一种机制,允许运行在Weblogic上的应用程序能够使用添加到JBoss上的请求队列上的消息。此外,应用程序应该能够将消息发布到请求队列(也托管在JBoss上) 我在Oracle文档中读到了关于外国JNDI提供程序的信息,我找到的大
-
使用信号量的生产者消费者问题
本文向大家介绍使用信号量的生产者消费者问题,包括了使用信号量的生产者消费者问题的使用技巧和注意事项,需要的朋友参考一下 生产者消费者问题是同步问题。有一个固定大小的缓冲区,生产者生产商品并将其输入缓冲区。消费者从缓冲区中删除项目并消费它们。 当消费者从缓冲区中消费商品时,生产者不应将商品生产到缓冲区中,反之亦然。因此,缓冲区只能一次由生产者或使用者访问。 生产者消费者问题可以使用信号量解决。生产者
-
跨多个节点的Kafka消费者水平扩容
我正在数据库中为主题外部化kafka消费者元数据,包括消费者组和组中消费者的数量。 Consumer\u info表具有 主题名称,消费者组名称,组中的消费者数量消费者类名称 在app server启动时,我正在读取表并根据表中设置的数字创建使用者(线程)。如果使用者组计数设置为3,我将创建3个使用者线程。这基于给定主题的分区数 现在,如果我需要横向扩展,我如何将属于同一组的消费者分布在多个应用服
-
扩展AWS Kinesis流并提高消费端的性能
Kinesis流用于从调用应用程序馈送消息,我们从Kinesis流中获取消息并进行处理。KPL(本地)用于将数据生成(馈送)到Kinesis中,KCL(@AWS EC2)用于消费者端KPL正在以良好的速度生成消息,但由于流转时长问题1,消费者需要更多时间
-
一个Kafka话题能搞定多少消费群体?
假设我有一个Kafka主题,大约有10个分区,我知道每个消费群体应该有10个消费者在任何给定的时间阅读该主题,以实现最大的平行性。 然而,我想知道,对于一个主题在任何给定时间点可以处理的消费者群体的数量,是否也有任何直接规则。(我最近在一次采访中被问及这一点)。据我所知,这取决于代理的配置,以便在任何给定的时间点可以处理多少个连接。 然而,我只是想知道在给定的时间点可以扩展多少个最大消费群体(每个