《遍历》专题
-
Kafka如何保证消费者不会将一条信息读两遍?
Kafka如何保证消费者不会将一条信息读两遍? 或者上述情况是否可能?同一条信息可以被单个消费者或多个消费者阅读两次吗?
-
Java的PriorityQueue的内置迭代器不会以任何特定顺序遍历数据结构。为什么?
问题内容: 因此,基本上,PriorityQueue可以正常工作,但是使用其自己的内置toString()方法将其打印到屏幕上,使我看到了这种异常,并想知道是否有人可以解释为什么迭代器提供了(并使用了内部)是否不以其自然顺序遍历PriorityQueue? 问题答案: 因为基础数据结构不支持它。二进制堆仅部分排序,最小的元素位于根。当您删除它时,堆将重新排序,以便下一个最小的元素位于根。没有有效的
-
算法题:二叉树层序遍历,进一步提问:要求每层打印出一个换行符?
本文向大家介绍算法题:二叉树层序遍历,进一步提问:要求每层打印出一个换行符?相关面试题,主要包含被问及算法题:二叉树层序遍历,进一步提问:要求每层打印出一个换行符?时的应答技巧和注意事项,需要的朋友参考一下 考察点:二叉树
-
在流行的硬币变化动态编程问题中,遍历状态的正确顺序是什么?
我在Hackerrank上解决了这个(https://www.hackerrank.com/challenges/coin-change/copy-from/188149763)问题,可以总结如下: 找到与给定的硬币面额集合交换某个值的总方法。 这是我被接受的代码: 这里n是我们应该得到的总值,c是硬币的数组。我的问题是,如果我颠倒循环的顺序,也就是做类似的事情 为什么答案会改变?
-
如何在不遍历优先级队列的情况下获取该队列的最后一个元素
我有以下优先级队列: 现在为了得到最后一个元素,我必须pop()队列中的所有元素。是否有某种方法可以检索这个优先级队列的最后一个元素。 我知道可以颠倒“CompareTime”中的顺序,使最后一个元素成为第一个元素。我不想这样做,因为我想按“CompareTime”确定的顺序从优先级队列中弹出()元素。但同时我还需要优先级队列的最后一个元素。。不弹出优先级队列中的所有元素。是否可以确定优先级队列的
-
循环遍历集合中的jQuery对象,而无需为每次迭代初始化新的jQuery对象
我发现自己一直在这样做: 在每次迭代中初始化一个新的jQuery对象是一个巨大的性能损失。 所以我想改做这个(功劳也归于decx@freenode): 但是我修复了一个JSPerf测试,这个代码片段的性能与第一个代码片段完全相同!:( 两者都非常慢!对于非常大的集合,您甚至可以注意到页面冻结。 所以我想知道在集合中迭代jQuery对象的快速方法是什么。 方式也应尽量方便使用。这: 会比古代的(无能
-
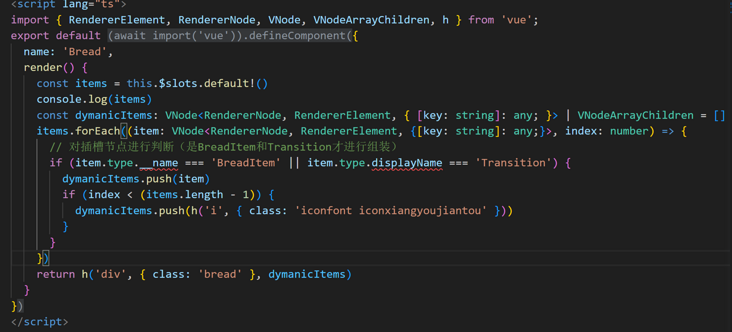 前端 - Vue3+TS项目中,遍历字节点type属性类型在编辑器中报错的问题?
前端 - Vue3+TS项目中,遍历字节点type属性类型在编辑器中报错的问题?遍历子节点数组时,控制台打印显示有对应属性,而且组件也可以正常展示,但是编辑器里面报错不存在对应类型,难道要该源码添加对应的类型吗? 如果给item声明any,打包的时候也会报错,这种需要怎么解决,希望大佬可以指点指点。
-
嵌套JSON。JS try/catch未捕获解析错误和JS对象遍历错误,导致服务器崩溃
我在Express中有这个POST路由处理程序。我担心的是,使用一个大的try/cat块不能正确地捕获其中发生的所有错误。 在下面唯一的try/cat块中,我尝试访问嵌套的本机JS属性-即parsed.template.list.push(listItem); 所以我试图将一个对象推送到嵌套属性的数组上。如果模板不存在,它将导致运行时错误,但这并不被try/catch所捕获,服务器只是完全停止,并
-
为什么在对不带分隔符的split()进行遍历时,数组的第0个索引中出现“”?
问题内容: 在执行时,为什么在数组的第0个索引中得到一个? 问题答案: 为什么我在str2数组的第0个索引中得到“”? 因为您使用的定界符已在此处匹配: 由于收集到的零件在进入字符串时会“走过去”,因此这里收集了空字符串。 还要注意,由于定界符为空,为了避免无限循环,在下一次迭代时,将转发一个字符,然后再次开始搜索。
-
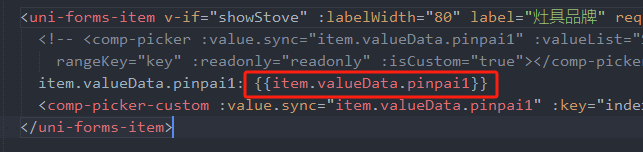 前端 - vue的节点数组遍历取数组的某项对象里的值赋值没有响应式?
前端 - vue的节点数组遍历取数组的某项对象里的值赋值没有响应式?以下是我的一个demo,想问问还有没有大神有其他实现方案 我这个对象是一个数组遍历的item的对象 这个对象里的pinpai1没有响应式,该怎么做?
-
详解Jquery EasyUI tree 的异步加载(遍历指定文件夹,根据文件夹内的文件生成tree)
本文向大家介绍详解Jquery EasyUI tree 的异步加载(遍历指定文件夹,根据文件夹内的文件生成tree),包括了详解Jquery EasyUI tree 的异步加载(遍历指定文件夹,根据文件夹内的文件生成tree)的使用技巧和注意事项,需要的朋友参考一下 Jquery EasyUI tree 的异步加载(遍历指定文件夹,根据文件夹内的文件生成tree)具体代码如下: 前台 以上就是本文
-
python中dict字典的查询键值对 遍历 排序 创建 访问 更新 删除基础操作方法
本文向大家介绍python中dict字典的查询键值对 遍历 排序 创建 访问 更新 删除基础操作方法,包括了python中dict字典的查询键值对 遍历 排序 创建 访问 更新 删除基础操作方法的使用技巧和注意事项,需要的朋友参考一下 字典是另一种可变容器模型,且可存储任意类型对象。 字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})
-
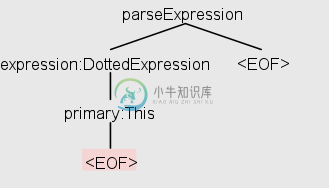 为什么解析树可视化和我的访问者/侦听器遍历之间有这么大的区别?
为什么解析树可视化和我的访问者/侦听器遍历之间有这么大的区别?我使用IntelliJ中的ANTLR4插件创建了这个示例语法,当我使用它的工具链为一些无效内容(在本例中是一个空字符串)生成一个可视化表示时,这个表示似乎与我在使用相同输入的示例访问者/侦听器实现进行实际解析树遍历时所能得到的不同。 这是语法: 对于空字符串,我得到以下树: 此树表明解析器构建了一个包含“DottedExpress”和“main: This”的解析树(假设它使用自己的访问者/侦听器
-
可以使用Jenkins和Groovy循环遍历构建列表(每个构建都有参数)并启动它们吗?
可以使用Jenkins和Groovy循环浏览Visual Build Pro构建列表(每个构建具有不同的参数)并启动指定的构建作业吗?每个构建需要2个不同的VBP脚本,一个用于标记,另一个用于构建。 没有必要让这些构建并行运行,让它们按顺序运行就可以了。每个构建作业都将在处理如下所示的输入文件时启动,每个构建作业都被赋予正确的Visual Build Pro bld脚本名称,以及所有其他所需的参数
-
使用检查玛克斯工具在代码扫描期间获取检查马克思路径遍历问题
在执行 HttpWeb 请求时获取检查火星路径遍历问题, checkmarx的错误消息:从headers元素获取动态数据。然后,这个元素的值流经代码,最终用于本地磁盘访问的文件路径。 我在标头中传递的唯一输入是用于访问 API 的令牌。有没有办法克服这个问题? 下面是代码,我从cookie中获取令牌,并将其与httpRequest一起传递。