《遍历》专题
-
VBS脚本实现遍历批量替换多目录多文件内容的代码
本文向大家介绍VBS脚本实现遍历批量替换多目录多文件内容的代码,包括了VBS脚本实现遍历批量替换多目录多文件内容的代码的使用技巧和注意事项,需要的朋友参考一下 有时候我们需要将一个目录与子目录中的多个htm网页文件实现批量替换,这里就为大家分享一下 将以下代码复制到一个文本文档中,并将文本文档的后缀修改为.vbs,直接运行即可 cmd /c dir /s/b *.htm > list.htm就是将
-
“太多的价值无法解包”,遍历一个字典。键=>字符串,值=>列表
问题内容: 我得到了错误。知道我该如何解决吗? 问题答案: Python 2 您需要使用。 请参阅此答案,以获取有关遍历字典的更多信息,例如跨python版本使用using 。 Python 3 由于 Python 3的 是不再支持。使用代替。
-
Django原始SQL查询-遍历结果,它为每次迭代执行一个查询
问题内容: 在注意到Django的某些内置查询效率低下之后,一直在编写一些原始SQL查询。我试图遍历结果并将其分组(我知道模板标签,这对我不起作用- 我需要能够独立访问单独的组)。这是我的代码: 这给了我我想要的东西(例如,我可以访问的列表),但是它为每次迭代运行一个数据库查询以获取字段。我尝试在循环之前添加,没有效果。 有人可以帮我从这里出去吗?这似乎应该很简单。 谢谢,马特 问题答案: 编辑:
-
python实现在遍历列表时,直接对dict元素增加字段的方法
本文向大家介绍python实现在遍历列表时,直接对dict元素增加字段的方法,包括了python实现在遍历列表时,直接对dict元素增加字段的方法的使用技巧和注意事项,需要的朋友参考一下 example: 这个功能实在太强大了,python好棒。 以上这篇python实现在遍历列表时,直接对dict元素增加字段的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
hazelcast-有没有一种方法可以遍历要查询的映射键和/或值
我有一个类,它的一个字段是map。在Hazelcast中,有没有一种方法可以使用谓词查询映射中的键具有我要查找的值的对象?
-
Python遍历zip文件输出名称时出现乱码问题的解决方法
本文向大家介绍Python遍历zip文件输出名称时出现乱码问题的解决方法,包括了Python遍历zip文件输出名称时出现乱码问题的解决方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python遍历zip文件输出名称时出现乱码问题的解决方法。分享给大家供大家参考。具体如下: windows中使用python2.7遍历zip文件之后输出文件名等信息,console打印的中文及一些标点出现
-
jQuery 获取遍历获取table中每一个tr中的第一个td的方法
本文向大家介绍jQuery 获取遍历获取table中每一个tr中的第一个td的方法,包括了jQuery 获取遍历获取table中每一个tr中的第一个td的方法的使用技巧和注意事项,需要的朋友参考一下 如下所示: 以上就是小编为大家带来的jQuery 获取遍历获取table中每一个tr中的第一个td的方法全部内容了,希望大家多多支持呐喊教程~
-
如何遍历整个mongo数据库,因为它太大而无法加载?[重复]
我必须为我公司的一位客户做一些数据处理。他们有一个大约4.7GB数据的数据库。我需要为每个文档添加一个字段,该字段使用mongo文档的两个属性和一个外部引用进行计算。 我的问题是,我不能收集。find()是因为节点。js内存不足。迭代整个集合的最佳方式是什么?集合太大,无法通过单个调用加载,无法查找?
-
我有一个Scala列表,我怎样才能得到一个可遍历的列表?
从Scala列表开始。 如何将其转换为可遍历一次?
-
循环遍历传递到方法中的数组。是否显示数组中的值?
我是Java的新手,我正在为学校做一个项目。我对数组有基本的了解,但被一个说明弄糊涂了,可以使用一些指导。以下是作业开始的说明: 1)在名为ArrayPrinter的类中启动程序。暂时忽略main方法。 2.)在类中,创建一个名为printArray的静态方法,其中有一个int[]类型的参数名为arr。在该方法中,执行以下操作。 使用System.out.print()将所有输出保持在一行上,直到
-
使用前一条边属性值过滤后一条边的小精灵图遍历
在图遍历中,我只想考虑具有与在遍历的前一步中访问的一条边的属性相等的属性的边。 我找到了http://tinkerpop.apache.org/docs/current/recipes/#traversal-induced-values但这似乎只适用于单个对象,在我的例子中,我需要在遍历时更改值。例如,从具有出站边(E1、E2、E3...)的V1开始,我想遍历E1到V2,然后沿着V2的任何边遍历,
-
以编程方式遍历多个顶点时,使用顶点属性值创建边
我发现,当从DB或任何格式将数据导入到图中时,我需要使用这些键创建边,这些键已经是顶点中的属性。 我如何通过使用这些我已经摄入到图中的FK遍历所有顶点来创建边? 我需要这是可编程的,因为我有很多需要这一步的数据。目前我正在使用Gremlin。Net,因为我使用的大部分代码已经是C# 示例:假设我吞下了一些客户 g.add客户,c_id,product_id 和一些产品 g、 addV(“产品”)。
-
如何构建一个方法来遍历WebElements并返回使用Selenium显示的WebElements
因此,页面中充满了许多类似的属性,如下面的两个元素。例子: 我使用PageObject和PageFactory获取元素,并将它们放入如下数组: 问题是:我需要单击其中一个类似的按钮,而不使用索引(因为结果是很难维护)。我想到了一种方法,我可以收集列表中的所有WebElement并返回屏幕上显示的单个WebElement(我乐于接受新想法),因此以下是我尝试过但未成功的两种方法: 我找了很多东西,没
-
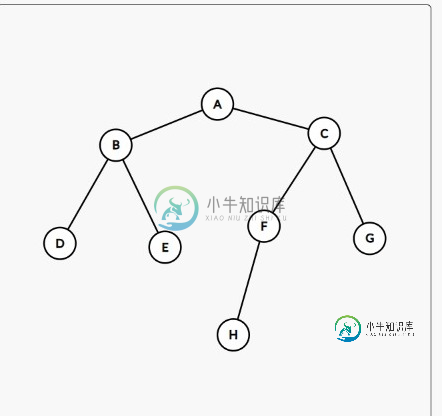 如何在执行 BFS/DFS 算法时从遍历路径中找到最终路径
如何在执行 BFS/DFS 算法时从遍历路径中找到最终路径我正在尝试解决一个问题,在一棵树上应用广度优先搜索算法和深度优先搜索算法,并找出这两种算法找到的遍历和最终路径。 我实际上感到困惑的是我如何计算这两种不同的路径?它们真的不同吗? 例如,考虑下面的树, 假设,我们的起始节点是A,目标节点是H 对于这两种算法,这就是我所感觉的穿越路径和最终路径 对于BFS 遍历路径:A B C D E F G H 最终路径:A C F H 如果这就是它的工作方式,那
-
如何使用增强的for循环遍历另一个方法中的哈希集?
对于我的任务,我被要求提供以下内容: 创建