
为什么解析树可视化和我的访问者/侦听器遍历之间有这么大的区别?

我使用IntelliJ中的ANTLR4插件创建了这个示例语法,当我使用它的工具链为一些无效内容(在本例中是一个空字符串)生成一个可视化表示时,这个表示似乎与我在使用相同输入的示例访问者/侦听器实现进行实际解析树遍历时所能得到的不同。
这是语法:
grammar TestParser;
THIS : 'this';
Identifier
: [a-zA-Z0-9]+
;
WS : [ \t\r\n\u000C]+ -> skip;
parseExpression:
expression EOF
;
expression
: expression bop='.' (Identifier | THIS ) #DottedExpression
| primary #PrimaryExpression
;
primary
: THIS #This
| Identifier #PrimaryIdentifier
;
对于空字符串,我得到以下树:
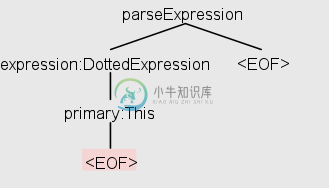
此树表明解析器构建了一个包含“DottedExpress”和“main: This”的解析树(假设它使用自己的访问者/侦听器实现来执行此操作)。然而,当我使用以下代码尝试相同的操作时:
package org.example.so;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTreeWalker;
public class TestParser {
public static void main(String[] args) {
String input = "";
TestParserLexer lexer = new TestParserLexer(CharStreams.fromString(input));
CommonTokenStream tokenStream = new CommonTokenStream(lexer);
TestParserParser parser = new TestParserParser(tokenStream);
TestParserParser.ParseExpressionContext parseExpressionContext = parser.parseExpression();
MyVisitor visitor = new MyVisitor();
visitor.visit(parseExpressionContext);
System.out.println("----------------");
ParseTreeWalker walker = new ParseTreeWalker();
walker.walk(new MyListener(), parseExpressionContext);
System.out.println("----------------");
}
private static class MyVisitor extends TestParserBaseVisitor {
@Override
public Object visitParseExpression(TestParserParser.ParseExpressionContext ctx) {
System.out.println(TestParserParser.ruleNames[ctx.getRuleIndex()]);
return super.visitParseExpression(ctx);
}
@Override
public Object visitDottedExpression(TestParserParser.DottedExpressionContext ctx) {
System.out.println(TestParserParser.ruleNames[ctx.getRuleIndex()] + ":DottedExpression");
return super.visitDottedExpression(ctx);
}
@Override
public Object visitPrimaryExpression(TestParserParser.PrimaryExpressionContext ctx) {
System.out.println(TestParserParser.ruleNames[ctx.getRuleIndex()] + ":PrimaryExpression");
return super.visitPrimaryExpression(ctx);
}
@Override
public Object visitThis(TestParserParser.ThisContext ctx) {
System.out.println(TestParserParser.ruleNames[ctx.getRuleIndex()]);
return super.visitThis(ctx);
}
@Override
public Object visitPrimaryIdentifier(TestParserParser.PrimaryIdentifierContext ctx) {
System.out.println(TestParserParser.ruleNames[ctx.getRuleIndex()]);
return super.visitPrimaryIdentifier(ctx);
}
}
private static class MyListener extends TestParserBaseListener {
@Override
public void enterParseExpression(TestParserParser.ParseExpressionContext ctx) {
System.out.println(TestParserParser.ruleNames[ctx.getRuleIndex()]);
}
@Override
public void enterDottedExpression(TestParserParser.DottedExpressionContext ctx) {
System.out.println(TestParserParser.ruleNames[ctx.getRuleIndex()] + ":DottedExpression");
}
@Override
public void enterPrimaryExpression(TestParserParser.PrimaryExpressionContext ctx) {
System.out.println(TestParserParser.ruleNames[ctx.getRuleIndex()] + ":PrimaryExpression");
}
@Override
public void enterThis(TestParserParser.ThisContext ctx) {
System.out.println(TestParserParser.ruleNames[ctx.getRuleIndex()]);
}
@Override
public void enterPrimaryIdentifier(TestParserParser.PrimaryIdentifierContext ctx) {
System.out.println(TestParserParser.ruleNames[ctx.getRuleIndex()]);
}
}
}
我得到以下输出:
line 1:0 mismatched input '<EOF>' expecting {'this', Identifier}
parseExpression
expression:PrimaryExpression
----------------
parseExpression
expression:PrimaryExpression
----------------
因此,不仅树的深度不匹配,输出还表明第二次匹配了不同的规则(“PrimaryExpression”而不是“DottedExpression”)。
为什么我显示的内容和我试图显示的内容之间存在如此大的差异?如何创建与插件所显示的相同的树表示?
使用ANTLR版本4.7。插件版本是1.8.4。
共有1个答案

此问题已在插件版本1.8.2修复。如果您有版本1.8.2或更高版本,那么您可能发现了该问题的其他未知子情况。
然而(基于我所指的问题),只有当解析导致错误时,树才会不同。因此,如果你对使用错误信息不感兴趣,你应该没问题。
-
问题内容: 我试图区分侦听器和适配器。 它们是否几乎相同,但是在侦听器中,您必须实现接口中的所有方法,但是对于适配器,您可以选择仅实现所需的方法,从而使代码更简洁,更易于阅读? 我还被告知适配器只能通过一种实现实现实例化,而您不能实例化侦听器,我对此并不完全了解。 有人可以解释使用哪一种更好,而另一种却不能用吗? 问题答案: WindowListener是强制您使用所有方法的方法,而WindowA
-
问题内容: 我无法理解以下文本…这是否意味着空的构造函数?为什么拥有两个不同的版本很重要? https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-2.html 在Java虚拟机级别,每个构造函数(第2.12节)都作为具有特殊名称的实例初始化方法出现。该名称由编译器提供。因为该名称不是有效的标识符,所以不能直接用Java编程语言编写的程序中使
-
我正在浏览微软的Rust教程,它是关于 实现函数,以便返回对插入向量中的值的引用 这里给出了解决方案,但它与我的不同之处在于它使用了 除了返回类型之外,我的和标准解决方案之间的另一个区别是,我只是简单地返回了参数,而标准解决方案使用复杂方式)。 我想知道我的解决方案是否有任何问题,本教程采取了另一种方式? 虽然@Masklin为我的问题提供了一个很好的答案,但它有点特定于我给出的示例,但没有直接解
-
问题内容: 我试图破译以下功能: 我从http://blog.danlew.net/2014/09/15/grokking-rxjava- part-1/ 获得了一个很好的rxjava简介,但是它只是顺便提到了Observer,说您将在大多数情况下使用Subscriber从Observable发射到消费项目的时间。 有人可以向我解释 什么是观察者? 观察者与订户有何不同? 上面的代码段是做什么的?
-
问题内容: 在此示例中: 无法编译为: 而被编译器接受。 这个答案说明唯一的区别是,与不同,它允许您稍后引用类型,似乎并非如此。 是什么区别,并在这种情况下,为什么不第一编译? 问题答案: 通过使用以下签名定义方法: 并像这样调用它: 在jls§8.1.2中,我们发现(有趣的部分被我加粗了): 通用类声明定义了一组参数化类型(第4.5节), 每种可能通过类型arguments调用类型参数节的类型
-
问题内容: 我所有的React项目的文件大小通常都非常大(bundle.js为4.87 mb,vendor.bundle.js为2.87 mb)。我不知道为什么这么大。我已经启用了uglifyJS,但这似乎并没有太大帮助(5.09> 4.87mb和2.9> 2.87mb) 我的package.json 有谁知道如何解决这个问题? 问题答案: 编辑 我不确定您是在Mac / IO还是Windows上