《哈啰出行》专题
-
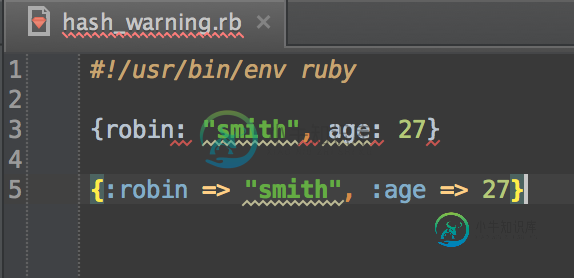 IntelliJ Idea终极红底红宝石速记哈希文字
IntelliJ Idea终极红底红宝石速记哈希文字有人知道为什么IntelliJ Idea Ultimate不喜欢更新语法中的Ruby哈希文本吗?请参阅下面IDE屏幕截图中的红色下划线。语法: 真的很烦人,因为这意味着我的整个项目在目录树上都有一条红色下划线。 我在IDE首选项中设置了一个大于1.9的Ruby SDK版本(我认为是在这个时候引入了新的哈希文本语法),所以没有任何借口! 谢谢
-
只有一个参数函数有效吗?哈斯克尔
我已经开始学习Haskell,我读到Haskell中的每一个函数只需要一个参数,我不明白在Haskell的庇护下发生了什么魔法,这使得它成为可能,我想知道它是否有效。 上面的签名意味着函数接受一个,然后返回另一个函数,该函数接受一个,并返回一个 示例1相对简单,但我开始想知道当函数稍微复杂一点时会发生什么。 在这个例子中,我编写了一个函数,并以两种方式执行它,一次传递一个参数,一次传递所有参数。
-
 米哈游 产品运营 一二面凉经(更新中)
米哈游 产品运营 一二面凉经(更新中)今晚刚刚收到了感谢信,虽然已经预想到了这个结果,但真的等到那一刻的感觉还是很不好受,眼泪一点点从眼角滑落,在床上瘫了一个多小时才爬起来。虽然作为24届还有机会,主要原因还是自己水平不够,就好好复盘起从头开始吧,也希望给各位一点我个人的经验教训,我们秋招再见。 看了一下牛客上还没有今年运营春招的,不知道会不会被米的人看到要求删除,如果有需要我会配合 Timeline:2.28投递简历,3.09笔试通
-
 哟尔哈 游戏客户端开发工程师 一面
哟尔哈 游戏客户端开发工程师 一面40min,只问了项目,虚幻引擎和场景题 1.简述项目,然后稍微深挖了一下AI功能实现和行为树相关知识以及人物动作的逻辑,比如状态机,以及移动时开火动作冲突的问题 2. A*算法,以及优化。A*算法得到的一定是最短路径吗 3.场景题:场景中有两万个人和一个防御塔,会锁定其攻击范围内生命值最低的5个人,怎么实现? (第一反应是topk的方法,简单说了一下),追问:每个人都有矩形碰撞体积而不是点的情况
-
 米哈游后端笔试第一场(含1,2题代码)
米哈游后端笔试第一场(含1,2题代码)太菜了只做出两题,有没有大佬出了第三题 第一题:求两点间最短曼哈顿距离,可以穿越边界 #include <bits/stdc++.h> using i64 = long long; i64 n, m; i64 getDist(std::pair<i64, i64> a, std::pair<i64, i64> b) { return std::min(std::abs(a.first -
-
 米哈游系统策划一面凉经(已经凉了)
米哈游系统策划一面凉经(已经凉了)刚刚凉的,趁还记得东西,来给大家(包括我自己)分享一下。 本人菜鸡某双非本科,数字媒体艺术专业出生。无大厂实习,无游戏开发比赛经验。有一个小厂的实习经验。 秋招凭着一腔热血,问学长要了内推。 然后写了笔试(笔试不太会,就努力写) 笔试八九天HR短信约我面试时间。 然后我那天还在上班(那样有下午茶,我放不下。) 正经:面试上来先是自我介绍,然后我和背稿子一样,自我介绍了一下。 然后问我在实习公司的项
-
 【米哈游秋招三轮面经】 — 国际化运营岗
【米哈游秋招三轮面经】 — 国际化运营岗除去一二面重复问的问题,三面大概问了这些 原神多少级了?现在在哪个地图? 上一段实习时具体负责了哪些工作? 你是如何让公司账号粉丝数增长的? 你认为一篇内容火爆的原因是什么? 为什么想做这个岗位? 你觉得你有什么优势? #非技术面试记录#
-
 米哈游一面前端校招提前批面试题
米哈游一面前端校招提前批面试题1. 开摄像头,自我介绍 2. 实习经历,有没有遇到什么困难 3. webpack使用,优化等 4. js的底层是什么语言实现 5. js的堆栈,引用类型基本类型分别在什么内存,有没有大小限制 6. 任务队列,setTimeout底层如何实现的?nextTick是宏任务还是微任务,使用场景是什么,你知道的微任务都有什么 7. tcp是双工还是单工 8. 为什么挥手次数比握手多 9. 粘包 9. t
-
如何使用FlatMap java8根据键的数量对值进行哈希映射排序?
问题内容: 我有一个,我想找到每个值的键数 根据上面的帖子,我尝试了平面映射: 输出是 这意味着0有两个键,1有三个键,依此类推。现在,我想根据键的数量以降序对键和值进行排序。我尝试过这样的事情: 我想要以下输出: 键和值应根据此键的数量降序排列:1、2、3、4具有三个键,0和5具有两个键。 例如::1具有三个键,因此它首先出现:2和3具有三个键,而0仅具有两个键。 问题答案: 您可能具有以下内容
-
Eclipse-导出可运行的JAR文件(报警弹出)
我完全误解了关于将项目导出到JAR的一些事情。 2事情正在发生。
-
将对象的哈希码定义为所有类变量哈希码的总和,乘积或其他乘积是不正确的吗?
问题内容: 假设我有以下课程: 这是hashCode的正确实现吗?这不是我通常这样做的方式(我倾向于遵循有效的Java准则),但是我总是很想做类似上面的代码的诱惑。 谢谢 问题答案: 这取决于您所说的“正确”。假设您正在使用所有相关的-defining字段,那么是的,它是“正确的”。但是,此类公式可能不会具有良好的分布,因此可能导致比其他情况更多的冲突,这将对性能产生不利影响。 这是来自 有效Ja
-
typescript - xlsx 如何导出 表头分组的数据,exportExcel 只写出了单行的导出?
-
習題 8: 印出,印出
1 2 3 4 5 6 7 8 9 10 11 12 formatter = "%s %s %s %s" puts formatter % [1, 2, 3, 4] puts formatter % ["one", "two", "three", "four"] puts formatter % [true, false, false, true] puts formatter % [form
-
映射还原 - 化简器在一行中发出输出
我有一个简单的MapReduce作业,它应该从文本文件中读取字典,然后逐行处理另一个大文件并计算逆文档矩阵。输出应该如下所示: 但是,减速器的输出只在一个huuuge行中发出。我不明白为什么它应该为每个(这是减速器的关键)发出新行。 映射器生成正确的输出(一对<code>单词id的值在单独的行中)。我在没有减速器的情况下进行了测试。reducer应该只为每个键在一行中附加与相同键对应的值。 你能看
-
导出的可运行jar文件出现Java eclipse错误
导出的jar文件有问题。当我在Eclipse中运行项目时,它运行得很好,但是当我从控制台作为导出的jar运行它时,我收到以下错误消息: 代码如下: 我执行该方法的语法是