《花旗银行》专题
-
火花(贝壳),卡桑德拉:你好,世界?
Maven中央存储库(Spark-Cassandra-Connector-Java2.11) 那么,在本地运行Spark和Cassandra之后,如何创建keyspace、表和插入行呢?
-
 同花顺C++开发 一面 3.15 1h 凉经
同花顺C++开发 一面 3.15 1h 凉经面经祈福! 首先感谢同花顺,即使没有任何C++项目,也给面试机会了。 1.自我介绍 技术栈(Python、机器学习相关、深度学习相关,C++只是备选) 2.项目介绍 -深度学习相关的项目(Python)和C++仅有的关系就是使用PCL库和动态链接编译。 -不过面试官还是针对项目本身提问(难点、改进点)。 3.网络编程和Linux命令 -服务器、客户端通信流程。 -线程个数上限及原因(不知道)。 -
-
 同花顺 2023届秋招 Java开发(一面)
同花顺 2023届秋招 Java开发(一面)一面:(35分钟) 自我介绍 聊项目,选一个你觉得有意思的项目聊一聊(10分钟) 深挖项目流程 Linux的常用命令 你哪块比较熟?(MySQL吧) MySQL的Buffer Pool设计(我挑起来的,简单聊了一下没追问) 最左前缀法则 SQL执行计划 MySQL设计表怎么考虑 项目在产品方面存在的问题 反问环节(反问完面试官开始聊技术) Redis的gossip Happens Before规则
-
ES6导入什么时候该用花括号?
这似乎很明显,但我发现自己有点困惑,什么时候在ES6中为导入单个模块使用花括号。例如,在我正在处理的React-Native项目中,我有以下文件及其内容: 在todoReducer.js中,我必须在没有花括号的情况下导入它: 如果将括在花括号中,则会得到以下代码行的以下错误: 无法读取未定义的属性todo 类似的错误也发生在我的带有花括号的组件上。我在想什么时候应该对单个导入使用花括号,因为很明显
-
我不能在Python中使用花括号吗?
问题内容: 我正在读Python是通过缩进而不是花括号来完成所有“代码块”的工作。是对的吗?因此,函数,if和类似的东西都没有用大括号括起来而出现了吗? 问题答案: 您可以尝试使用将来的import语句添加对花括号的支持,但尚不支持,因此会出现语法错误:
-
python制作花瓣网美女图片爬虫
本文向大家介绍python制作花瓣网美女图片爬虫,包括了python制作花瓣网美女图片爬虫的使用技巧和注意事项,需要的朋友参考一下 花瓣图片的加载使用了延迟加载的技术,源代码只能下载20多张图片,修改后基本能下载所有的了,只是速度有点慢,后面再优化下
-
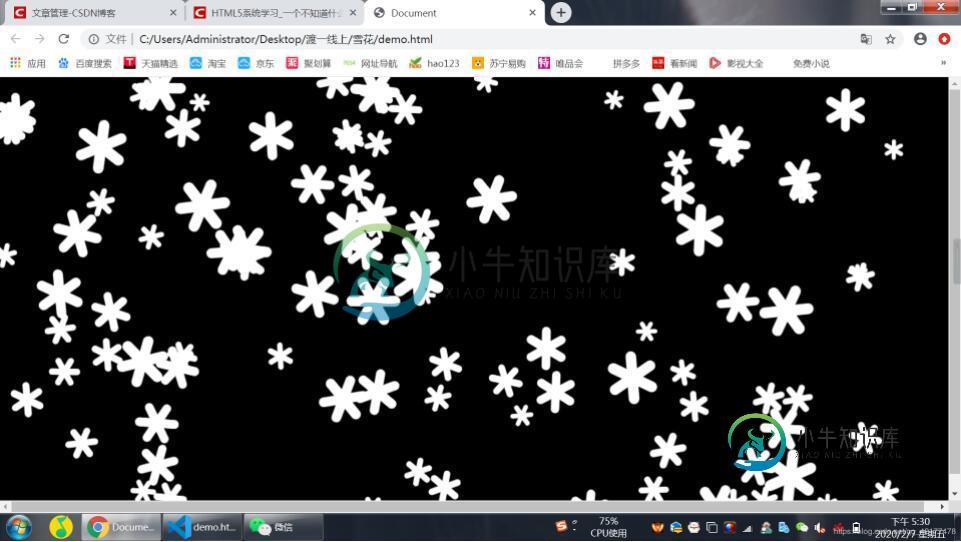 JavaScript canvas实现雪花随机动态飘落
JavaScript canvas实现雪花随机动态飘落本文向大家介绍JavaScript canvas实现雪花随机动态飘落,包括了JavaScript canvas实现雪花随机动态飘落的使用技巧和注意事项,需要的朋友参考一下 用canvas实现雪花随机动态飘落,供大家参考,具体内容如下 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
JavaScript实现的简单烟花特效代码
本文向大家介绍JavaScript实现的简单烟花特效代码,包括了JavaScript实现的简单烟花特效代码的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JavaScript实现的简单烟花特效代码。分享给大家供大家参考,具体如下: 这是一款JavaScript烟花特效,过年的时候放到你的网页上祝贺大家牛年大吉吧,是不是很不错? 运行效果截图如下: 在线演示地址如下: http://demo
-
AngularJS用双花括号表示法呈现HTML
问题内容: 我有包含HTML的JSON变量。 这样做:显示Angular 而不是和。 如何使Angular呈现实际的HTML? 更新: 这是我的控制器: 然后在我的HTML中可以使用: 问题答案: 您要 显示 HTML(例如)还是 渲染 HTML(例如 Hello )? 如果要显示它,大括号就足够了。但是,如果您拥有的html具有html实体(如),则需要手动对其进行转义。 如果要渲染它,则需要使
-
如何在火花外壳中注册kryo类
具有方法: 但是,它在属性提供的facade中不可用/公开 下面是有关RuntimeConfiguration的更多信息: 在创建自己的SparkSession时,有一个明确的解决方法:我们可以调用提供给 然后是一个不太清楚的... 但在运行Spark shell时,已经创建了sparkSession(sparkContext)。那么,如何使非运行时设置生效呢? 这里特别需要: 当尝试在可用于sp
-
使用pyrow如何附加到拼花文件?
如何使用pyarrow向拼花地板文件添加/更新? 我在文档中找不到任何关于附加拼花文件的内容。此外,您是否可以将pyarrow与多处理一起使用来插入/更新数据。
-
无接收器火花蒸汽驱动方法
对于使用kafka的Spark流,我们使用Directstream,这是一种无接收器的方法,并将kafka分区映射到Spark RDD分区。目前,我们有一个应用程序,其中我们使用Kafka直接方法并在RDBMS中维护我们的on偏移, 我们有类似的Kinesis吗?当我阅读火花-Kinesis集成的留档时,感觉检查点有所不同。以下是我遇到的一些问题 使用kinesis流是否将kinesis碎片映射到
-
python使用turtle库与random库绘制雪花
本文向大家介绍python使用turtle库与random库绘制雪花,包括了python使用turtle库与random库绘制雪花的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了python绘制雪花的具体代码,供大家参考,具体内容如下 代码非常容易理解,画着玩玩还是可以的。直接上代码 运行结果 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
使用配置单元生成拼花文件
-
从Kafka倒带偏移火花结构化流
我正在使用spark structured streaming(2.2.1)来消费来自Kafka(0.10)的主题。 我的检查点位置设置在外部HDFS目录上。在某些情况下,我希望重新启动流式应用程序,从一开始就消费数据。然而,即使我从HDFS目录中删除所有检查点数据并重新提交jar,Spark仍然能够找到我上次使用的偏移量并从那里恢复。偏移量还在哪里?我怀疑与Kafka消费者ID有关。但是,我无法