《花旗银行》专题
-
 同花顺一面
同花顺一面自我介绍 项目 MySQL:索引分类,回表,索引覆盖 Redis:RDB,AOF相关 软件开发所遵守的一些原则 Spring:底层一些优秀的设计模式 SpringBoot:自动装配,starter组件 JVM:垃圾回收器 怎么积累技术 手撕股票最大收益(lc122) 未来几年内的工作规划 面试官人很好,没有问很刁钻的问题,表达不清楚的点面试官也会帮助表达
-
JavaScript 秘密花园
这篇文章的作者是两位 Stack Overflow 用户, 伊沃·韦特泽尔 Ivo Wetzel(写作) 和 张易江 Zhang Yi Jiang(设计)。
-
妙码生花 - BuildAdmin
项目是基于Thinkphp6、Vue3、TypeScript、Vite、Pinia、Element Plus等最新稳定技术栈的后台管理系统,支持CRUD代码生成、内置WEB终端可直接执行npm install等命令、还内置了管理员管理/附件管理/会员管理/数据全局回收站/敏感数据修改记录等功能,无需授权即可免费商用,希望可以帮助大家快速开发。 主要特性 �� CRUD代码生成 一行命令即可生成数据
-
欧洲央行、交通银行、开放式银行中的密码模式
我知道当我在Openssl中使用CBC模式时,我可以给出一个块大小的倍数作为输入。但其他模式呢?ECB,CFB,OFB?我看到了一个医生,但我并不完全清楚。我应该打电话给他们吗? 比如说欧洲央行。它一次加密64位。所以伪代码应该是这样的(应该是这样的)? 但是上面的代码并不好。当我将更改为时,没关系。有什么好方法可以做到这一点?我的意思是,我们都知道8x8=64位,所以这应该是正确的,但事实并非如
-
 招银二面9.18
招银二面9.18#面经# #校招# #秋招# #招银网络科技校招# 全程三十多分钟。期间网又断了一次,校园网太垃圾了,老忘记开热点 1.项目,问了两三个问题,没咋回答出来。 2.开始八股。 方法重写和重载? static关键字的使用? synchronized可以修饰什么? valotile有啥用? 3.mysql 主键和索引有啥区别?底层是啥? 隔离级别有哪些? 怎么解决幻读? 4.redis redis的删除
-
 招银-java开发
招银-java开发面试官是个无情的提问机器...感觉他面试别人也麻了,我被别人面试也麻了...真的麻了,想摆烂的心蠢蠢欲动 1.mybatis怎么模糊查询 2.mybatis怎么防止sql注入 3.redis持久化方法有哪些 4.redis数据类型 5.hashmap扩容机制 6.保存1000个元素,怎么确定hashmap初始长度 7.代理模式 8.hashmap为什么要重写equals 9.jvm内存模型 10.
-
 招银Java一面
招银Java一面40min(准时结束) 1、自我介绍 2、你经常使用的集合有哪些? 3、介绍一下HashMap?是否线程安全?怎样可以线程安全? 4、什么时候改用的红黑树?为什么改用红黑树?红黑树怎么自平衡? 5、类中代码加载顺序?子类父类代码加载顺序? 6、string为什么不可变? 7、知道什么设计模式? 8、实现一下懒汉模式?实现一下双重判断并说一下为什么能线程安全? 9、介绍一下synchronized?
-
 招银C++一面
招银C++一面上来简短自我介绍 FTP解释一下 你项目没有用FTP吗(没) 解释一下你的项目 项目相关问题 阻塞和非阻塞区别 阻塞如何唤醒(感觉没理解,答了轮询或者信号) LT和ET HTTP请求方式,区别 HTTP状态码 302重定向解释一下,存在哪,关键字还有印象吗 sizeof strlen返回值是什么 用过linux吗,命令写一下,有什么用 手撕,删除重复链表节点,十分钟 A了 结束反问 总过程35分钟
-
 招银Java一面
招银Java一面无手撕,无手撕,无手撕! base:成都 1.自我介绍,项目挑一个讲讲 2.SQL语句可以从哪些方面优化(就答出来一个索引。。) 3.java面向对象的原则(不只封装,继承,多态) 4.java设计模式,挑两个讲讲具体 5.java内存管理怎么实现的 6.OSI七层模型,TCP在哪一层,HTTP在哪一层 7.TCP三次握手过程,长连接短链接是什么,各有什么优劣 8.数据从a系统发送至b系统,怎么知
-
 招银Java笔试
招银Java笔试15道 408+3道编程题; 编程题(Java方向): 1. 字符串列表逆序; 2. 约瑟夫环填空题; 3. ipv4和ipv6格式校验填空;
-
 09.02 招银笔试
09.02 招银笔试招商银行 笔试 - 2024-09-02 客观 + 编程,编程选的c++后端,客观考的很奇怪,然后是Java代码,并且有些知识点有点离谱。 1. 最小覆盖子串,只能调试无法提交,自己试了一些例子,有些没通过,没找出问题在哪。 2. 一道回溯,代码补全,只能填空无法测试。 3. 一道字符串处理,代码补全,只能填空无法测试。 逆天抽象笔试,跑不了代码我还写个啥,不能提交我怎么知道自己写的对不对。 #软
-
火花工和执行器芯
我有一个Spark集群运行在hdfs之上的纱线模式。我启动了一个带有2个内核和2G内存的worker。然后我提交了一个具有3个核心的1个执行器动态配置的作业。不过,我的工作还能运转。有人能解释启动worker的内核数量和为执行者请求的内核数量之间的差异吗。我的理解是,由于执行者在工人内部运行,他们无法获得比工人可用的资源更多的资源。
-
火花访问行对象值
我想通过分区迭代一个dataframe,对于每个分区,迭代它的所有行,并创建一个deleteList,它将包含HBase的每一行的delete对象。我将Spark和HBase与Java一起使用,并使用以下代码创建了一个行对象: 但它无法工作,因为我无法正确访问行的值。而df有一个名为“hbase_key”的列。
-
火花流后立即使用火花RDD过滤器
我正在使用火花流,我从Kafka读取流。阅读此流后,我将其添加到hazelcast地图中。 问题是,我需要在读取Kafka的流之后立即从地图中过滤值。 我正在使用下面的代码来并行化地图值。 但在这个逻辑中,我在另一个逻辑中使用JavaRDD,即JavaInputDStream.foreachRDD,这会导致序列化问题。 第一个问题是,如何通过事件驱动来运行spark作业? 另一方面,我只是想得到一
-
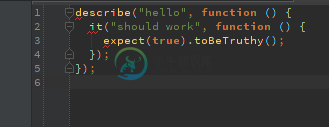 WebStorm茉莉花集成-JSHint无法识别茉莉花
WebStorm茉莉花集成-JSHint无法识别茉莉花我使用文件在 Webstorm 8.0.4 中设置了茉莉花集成 这与语法突出显示的工作方式一样,我可以跳转到声明,文档显示正确。所以连接看起来很好。然而,JSHint仍然为每个关键字抱怨它没有被定义,例如 另请参见以下屏幕截图。正如您所看到的,语法突出显示很好,但我仍然收到一个错误。