《组件》专题
-
javascript - js将树状数组安装条件分成两个数组?
以上数组根据id分成两个数组 请问应该怎么解决?
-
性能优化 - Vue 子组件渲染次数与父组件 props 和子组件数据变化的关系?
一般来讲vue父组件的数据发生变化会触发父组件渲染,如果父组件传入子组件的props数据发生变化会触发子组件渲染,如果 vue 中 父组件的props和子组件的数据同时发生变化,子组件会渲染2次吗? 如题
-
 react.js - 父子组件都使用memo,兄组件切换显示,弟组件重新渲染,memo为啥失效?
react.js - 父子组件都使用memo,兄组件切换显示,弟组件重新渲染,memo为啥失效?父组件: 子组件: 父组件和子组件都是用了memo:,切换isView,理应ImgShow组件不重新渲染,但是isView切换,都会打印“渲染了”,memo感觉失效了,这是为什么啊?求大佬指教
-
PDO fetchAll将所有组键值对组合成assoc数组
问题内容: 时不时地,我遇到类似以下查询的情况: 在这种情况下,我想获得一个关联数组,使用&的值作为该数组的相应条目,例如,如果数据库包含:,则该数组应为。 最常见的方法是: *另一种方法是调用两次,然后使用创建数组。但是,由于涉及两个数据库两个调用,因此我将其省略。 还有另一种方法吗? 问题答案: 对于您的问题,有一个非常好的解决方案,即: 适用于我,在PostgreSQL 9.1和在Windo
-
javascript - 如何将json数组修改组成新的数组?
修改为新的json数组 所示coords的值是josn1里的x、y代表的值或者相加的值
-
jScrollPane无法添加组件
问题内容: 我在表单上有一个和一个按钮。该按钮将组件添加到中。我正在使用FlowLayout居中对齐来将内 的组件进行排列。 第一个组件没有出现问题,并且对齐正确。当我再次按下按钮时,似乎什么也没有发生。当我跟随调试器时,它表明一切都与以前完全一样。 单击按钮时正在执行的代码: 这就是我在上设置的方式: 问题答案: 您正在混合重量(AWT)组件和轻量(Swing) 组件,这是不可取的,因为它们往往
-
Swing组件和序列化
问题内容: 为什么Swing 类要实现该接口?我实现视图的方式是无状态的,所有状态数据都存储在Presentation Model中。因此,我不需要序列化我的视图。我使用了注释来删除警告。是否有删除它们的更好方法? 问题答案: 最初,GUI构建器将以序列化格式保存UI。该标签甚至有从序列化形式负载的属性(我不知道还有谁使用了这一点,我只用它来是恶意的)。不幸的是,对GUI使用序列化机制实际上是行不
-
将URL解析为组件
问题内容: 我想在Java中使用斜杠(例如)来解析描述性网址。 我的总体想法是处理接收到的数据以在数据库中进行查找(因此使用URL作为搜索条件),然后返回包含数据的HTML页面。 我该怎么做呢? 问题答案: 您将拥有一个可以使用的字符串数组。
-
打印大型Swing组件
问题内容: 我在JScrollPane中有一个带有自定义表的Swing表单(它只是一个JPanel,而不是JTable子类),并且我试图将其打印出来。如果仅将整个框架发送给打印机,则滚动窗格将被剪切,并且如果将框架调整为滚动窗格的内容大小,则某种内部障碍将使JFrame的高度超过1100像素。 另一种选择是在不将对话框附加到根JFrame的情况下创建对话框的内容窗格,因为在这种情况下,JPanel
-
学习Vue组件实例
本文向大家介绍学习Vue组件实例,包括了学习Vue组件实例的使用技巧和注意事项,需要的朋友参考一下 Vue实例 项目启动过程 看一下现在我们的项目,想想整个项目的启动过程是什么(以直接打开index.html的方法访问为例来说明)? 你首先打开了index.html,里面只有一个写了一个id='root'的div,还有你引入了打包之后的代码,然后Vue自己肯定运行了一下(可以认为是Vue初始化)。
-
C++:组件协作模式
模板模式 模式定义 定义一个操作中的算法的骨架 (稳定),而将一些步骤延迟(变化)到子类中。 Template Method使得子类可以不改变(复用)一个算法的结构即可重定义(override 重写)该算法的某些特定步骤。 //程序库开发人员 class Library { public: void Run() { Step1(); if (Step2()) { //支持变化 ==> 虚
-
具有漏洞的组件
当应用程序中使用的库和框架等组件几乎总是以完全权限执行时,就会发生这种威胁。如果利用易受攻击的组件,则会使黑客的工作更容易导致严重的数据丢失或服务器接管。 让我们来了解这个漏洞的威胁代理,攻击向量,安全弱点,技术影响和业务影响。 威胁代理 - 使用自动化工具识别和利用的框架。 攻击者的方法 - 攻击者通过扫描或手动分析识别组件。 安全弱点 - 识别所使用的组件是否在应用程序的深处变得更加复杂。 如
-
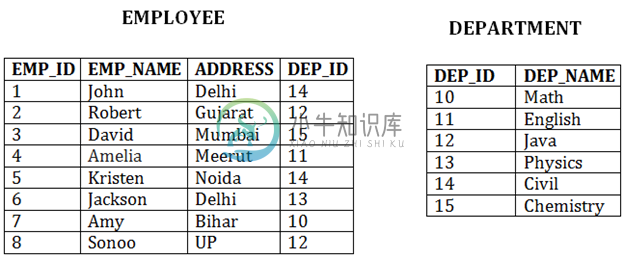 DBMS群集文件组织
DBMS群集文件组织当两个或多个记录存储在同一文件中时,它称为群集。 这些文件在同一数据块中有两个或多个表,并且用于将这些表映射到一起的键属性仅存储一次。 该方法降低了在不同文件中搜索各种记录的成本。 当经常需要以相同条件连接表时,将使用群集文件组织。这些连接只会从两个表中提供几条记录。 在给定的示例中,仅检索指定部门的记录。此方法不能用于检索整个部门的记录。 在这种方法中,可以直接插入,更新或删除任何记录。 数据根
-
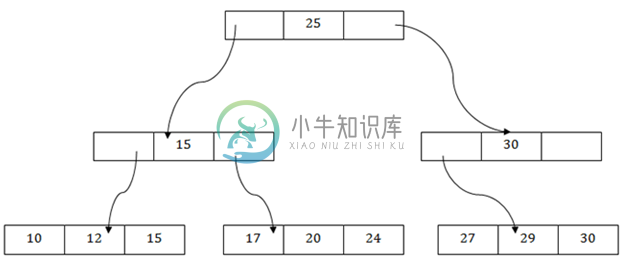 DBMS B+树文件组织
DBMS B+树文件组织B+树文件组织是索引顺序访问方法的高级方法,它使用树状结构在文件中存储记录。 它使用与概念相同,其中主键用于对记录进行排序。 对于每个主键,将生成索引的值并与记录一起映射。 B+树类似于二叉搜索树(BST),但它可以有两个以上的子节点。 在此方法中,所有记录仅存储在叶节点处,中间节点充当指向叶节点的指针,它们不包含任何记录。 上面 B+树 的描述: 树有一个根节点,即25。 存在具有节点的中间层。
-
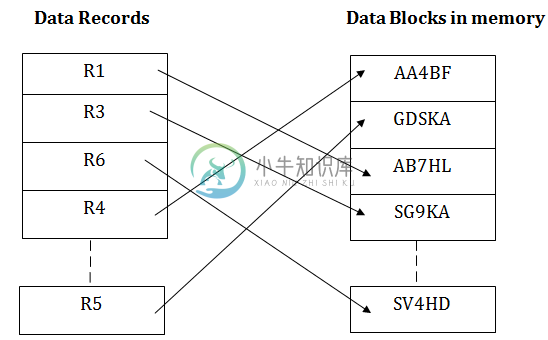 DBMS哈希文件组织
DBMS哈希文件组织哈希(散列)文件组织在记录的某些字段上使用哈希函数的计算。哈希函数的输出确定要放置记录的磁盘块的位置。 当必须使用哈希键列接收记录时,则生成地址,并使用该地址检索整个记录。 以同样的方式,当必须插入新记录时,使用哈希键生成地址并直接插入记录。 在删除和更新的情况下应用相同的过程。 在这种方法中,没有必要搜索和排序整个文件。 因为在此方法中,每条记录将随机存储在内存中。