《垂直分表》专题
-
将列表分成较小的列表(分为两半)
问题内容: 我正在寻找一种将python列表轻松分成两半的方法。 这样,如果我有一个数组: 我将能够得到: 问题答案: 如果需要功能:
-
如何将一个html表并排分成两部分?
问题内容: 我想要一个表将显示一半的行,然后环绕并水平包装并显示另一半行,而不是一个长的垂直表。 我正在使用角度数据,希望能够将一个数据数组绑定到一张表,但是要像描述的那样将其水平跨两个部分。两个表是一个选项,但是这意味着我必须添加更多逻辑,如果可能的话,我希望避免使用。即,对于排序ID,必须先将数据集重新连接在一起并对其进行排序,然后再进行拆分。 任何指针表示赞赏。 问题答案: 您可以尝试使用C
-
1.4.4 分库分表之后,id 主键如何处理?
面试题 分库分表之后,id 主键如何处理? 面试官心理分析 其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 开始累加,那肯定不对啊,需要一个全局唯一的 id 来支持。所以这都是你实际生产环境中必须考虑的问题。 面试题剖析 基于数据库的实现方案 数据库自增 id 这个就是说你的系统里每次得到一个 id,都是往一个库的一个表里插入一条没什么业务
-
 Springboot2.x+ShardingSphere实现分库分表的示例代码
Springboot2.x+ShardingSphere实现分库分表的示例代码本文向大家介绍Springboot2.x+ShardingSphere实现分库分表的示例代码,包括了Springboot2.x+ShardingSphere实现分库分表的示例代码的使用技巧和注意事项,需要的朋友参考一下 之前一篇文章中我们讲了基于Mysql8的读写分离(文末有链接),这次来说说分库分表的实现过程。 概念解析 垂直分片 按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专
-
从SQL Server中的表中拆分逗号分隔值
问题内容: 我有一个其中有很多记录的记录,我想知道其中有多少个名字,以及其中一个名字多少时间。 表名 我想找到多少个名字及其数量。 预期的输出应该是这样的 帮助我解决它。 问题答案: 结果:
-
分库分表规则原理及自定义配置
背景 业务在使用分表分表时多数会使用简单的hash分表或者按照时间或者id使用内置的range分表函数,但某些情况下这些简单的hash规则和内置函数并不能满足业务复制的分表场景,这时就需要业务自定义分库分表规则。而zebra的分库分表规则使用的是groovy脚本,理论上可以支持定制各种复杂的路由规则。 基本原理 首先,先看一个简单的分库分表规则(使用本地配置时的XML),后面会基于该例子解释zeb
-
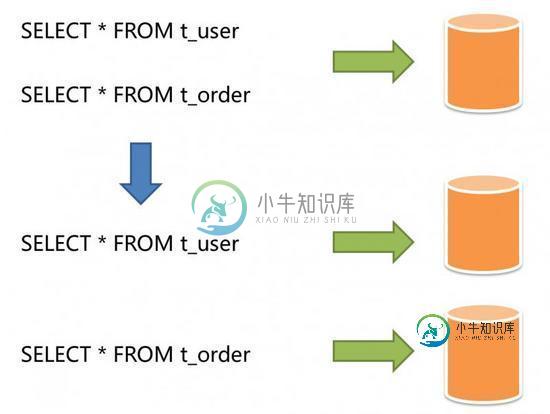
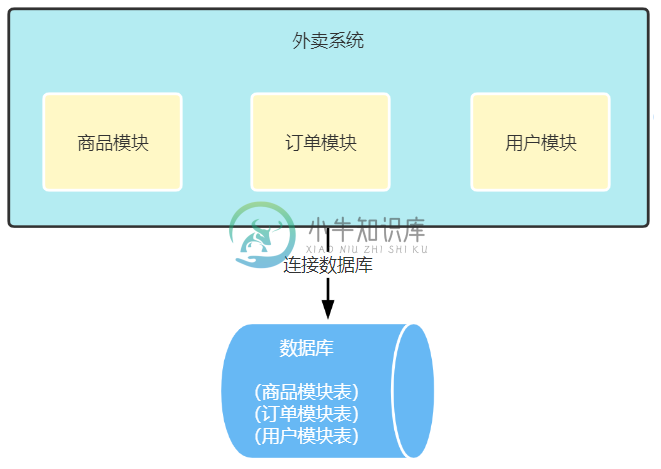 分库分表让系统性能提升上百倍
分库分表让系统性能提升上百倍主要内容:前 言,新的挑战,怎么做垂直拆分?,垂直拆分有哪些好处呢?,垂直拆分有什么不足的地方吗?前 言 读写分离方案上线后,订单sql查询时间再一次稳定在了300ms以下,此时对数据的增删改操作会走主库,而读请求会走从库,通过读写分离大大提升了数据读的处理能力,但遗憾的是没办法提升主库写数据的能力。 新的挑战 那么什么时候主库写数据的压力会过大呢?其实我们之前也聊过这个问题,那就是多个业务共用一个物理数据库的,比如商品相关的表、订单相关的表和用户相关的表等,所有表都放到了一个mysql数据库
-
使用带有逗号悬垂的airbnb样式指南,更美观、更美观
ESLint正在下面代码的第7行生成一个缺少尾部逗号的警告。我的漂亮设置设置为默认的es5。这是在创造一个混乱。我应该将此设置为所有在更漂亮的设置,以符合airbnb风格指南,还是最好在ESLint中禁用此警告?
-
C#中分部方法和分部类分析
本文向大家介绍C#中分部方法和分部类分析,包括了C#中分部方法和分部类分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了C#中分部方法和分部类。分享给大家供大家参考。 具体代码如下: 希望本文所述对大家的C#程序设计有所帮助。
-
1.13 第十二部分 独立成分分析
第十二部分 独立成分分析(Independent Components Analysis ) 接下来我们要讲的主体是独立成分分析(Independent Components Analysis,缩写为 ICA)。这个方法和主成分分析(PCA)类似,也是要找到一组新的基向量(basis)来表征(represent)样本数据。然而,这两个方法的目的是非常不同的。 还是先用“鸡尾酒会问题(cocktai
-
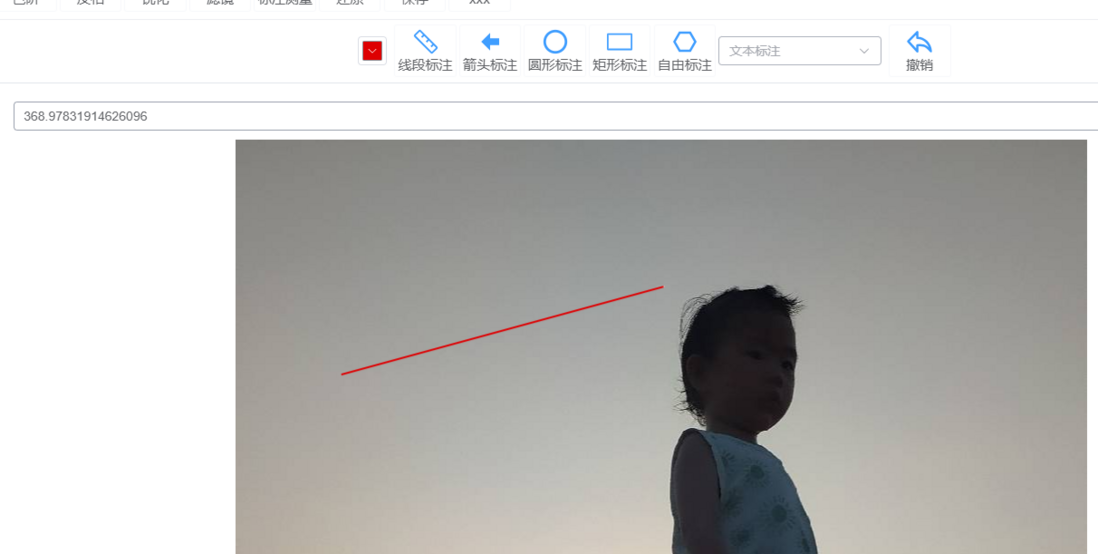 vue3中怎么求一条直线的长度,如这直线是100个像素,它是多少毫米?
vue3中怎么求一条直线的长度,如这直线是100个像素,它是多少毫米?如下面的红线是100像素的长度,怎么算出它有多少毫米。
-
分页与分段比较
分页与分段比较,如下表所示 - 编号 分页 分段 1 非连续的内存分配 非连续的内存分配 2 分页将程序分成固定大小的分页。 分段将程序分成可变大小的段。 3 由操作系统负责 由编译器负责。 4 分页比分段更快 分段比分页慢 5 分页更接近操作系统 分段更接近用户 6 它会遭受内部碎片问题 它会遭受外部碎片问题 7 没有外部碎片 没有外部碎片 8 逻辑地址分为:页码和页码偏移 逻辑地址分为:分段号
-
分区分布不均匀
我们在AWS上运行16个节点kafka集群,每个节点是m4. xLargeEC2实例,具有2TB EBS(ST1)磁盘。Kafka版本0.10.1.0,目前我们有大约100个主题。一些繁忙的话题每天会有大约20亿个事件,一些低量的话题每天只有数千个。 我们的大多数主题在生成消息时使用UUID作为分区键,因此分区分布相当均匀。 我们有相当多的消费者使用消费群体从这个集群消费。每个使用者都有一个唯一的
-
1.3.4.3 行为分析分群
用户分群是一种用户运营和用户分析手段,通过对特定用户进行定向投放实现精细化运营,通过对某一个用户群体分析发现不同用户的特征以及偏好。HubbleData的分群区别于传统的标签体系,支持产品策划或者运营人员通过行为数据指定用户,具体使用场景包括: 策划,交互或者视觉同事,通过对比不同分群用户对产品的使用,发现用户特征以优化产品设计 运营通过用户分群定向投放,实现用户的精细化运营 HubbleData
-
 thinkphp3.2.3 分页代码分享
thinkphp3.2.3 分页代码分享本文向大家介绍thinkphp3.2.3 分页代码分享,包括了thinkphp3.2.3 分页代码分享的使用技巧和注意事项,需要的朋友参考一下 对于thinkphp分页的实现效果,两种调用方法,一种调用公共函数中的函数方法(参考http://www.cnblogs.com/tianguook/p/4326613.html),一种是在模型中书写分页的方法 1、在公共函数Application/C