《垂直分表》专题
-
python实现在遍历列表时,直接对dict元素增加字段的方法
本文向大家介绍python实现在遍历列表时,直接对dict元素增加字段的方法,包括了python实现在遍历列表时,直接对dict元素增加字段的方法的使用技巧和注意事项,需要的朋友参考一下 example: 这个功能实在太强大了,python好棒。 以上这篇python实现在遍历列表时,直接对dict元素增加字段的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
1.4.3 如何设计可以动态扩容缩容的分库分表方案?
面试题 如何设计可以动态扩容缩容的分库分表方案? 面试官心理分析 对于分库分表来说,主要是面对以下问题: 选择一个数据库中间件,调研、学习、测试; 设计你的分库分表的一个方案,你要分成多少个库,每个库分成多少个表,比如 3 个库,每个库 4 个表; 基于选择好的数据库中间件,以及在测试环境建立好的分库分表的环境,然后测试一下能否正常进行分库分表的读写; 完成单库单表到分库分表的迁移,双写方案; 线
-
第三部分:Ceph 进阶 - 5. 清空 OSD 的分区表后如何恢复
本篇内容来自 zphj1987 —— 不小心清空了 Ceph 的 OSD 的分区表如何恢复 假设不小心对 Ceph OSD 执行了 ceph-deploy disk zap 这个操作,那么该 OSD 对应磁盘的分区表就丢失了。本文讲述了在这种情况下如何进行恢复。 破坏环境 我们现在有一个正常的集群,假设用的是默认的分区的方式,我们先来看看默认的分区方式是怎样的。 1、查看默认的分区方式。 root
-
如何将一个列表随机分为n个几乎相等的部分?
问题内容: 我已经阅读了[将列表切成n个几乎相等长度的分区重复问题的答案。 这是公认的答案: 我想知道,如何修改这些解决方案,以便将项目随机分配给分区而不是增量分配。 问题答案: 对列表进行分区之前先对其进行调用。
-
超大数据量存储常用数据库分表分库算法总结
本文向大家介绍超大数据量存储常用数据库分表分库算法总结,包括了超大数据量存储常用数据库分表分库算法总结的使用技巧和注意事项,需要的朋友参考一下 当一个应用的数据量大的时候,我们用单表和单库来存储会严重影响操作速度,如mysql的myisam存储,我们经过测试,200w以下的时候,mysql的访问速度都很快,但是如果超过200w以上的数据,他的访问速度会急剧下降,影响到我们webapp的访问速度,而
-
通过将分号分隔开来从单个查询中删除多个表
问题内容: 我试图从sqlite的单个操作中删除多个表。我尝试用分号分隔它,但没有按预期进行。这是我当前的代码: 我需要一些指导,以解决问题可能出在哪里,或者如果我缺少什么。 问题答案: 要使用多个语句进行原子操作,请使用事务: 如果使用sqlite3_prepare_v2,则必须一个接一个地执行这五个命令。使用sqlite3_exec,您可以一次调用执行它们(但不支持SQL参数)。
-
配置单元:如何将数据从分区表插入到分区表中?
查询示例: 典型错误消息: 处理语句时出错:失败:执行错误,从org.apache.hadoop.hive.ql.exec.mr.MapredTask返回代码2 问题2:当我运行命令?我是否只运行相同的命令,但使用STRING而不是bigint?**完整错误消息:**
-
在四分之一小时内每30分钟使用一次Cron表达式?
我目前正在尝试生成一个cron表达式,它在一天中每30分钟运行一次,但是在10:15, 10:45, 11:15等时间。我知道cron表达式每30分钟运行一次,但是它在10:00, 10:30, 11:00, 11:30等时间运行。我想知道是否有办法创建一个cron表达式,它可以在9:15, 9:45, 10:15, 10:45等时间运行,比如在四分之一小时内运行?
-
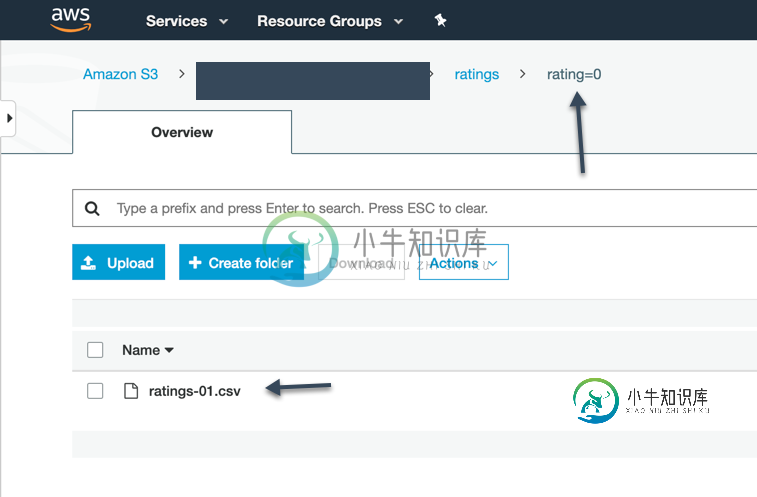 Apache Spark未使用配置单元分区外部表中的分区信息
Apache Spark未使用配置单元分区外部表中的分区信息我有一个简单的配置单元-外部表,它是在S3的顶部创建的(文件是CSV格式的)。当我运行配置单元查询时,它会显示所有记录和分区。 但是,当我在Spark中使用相同的表时(Spark SQL在分区列上有where条件),它并没有显示应用了分区筛选器。然而,对于配置单元托管表,Spark能够使用分区信息并应用分区筛选器。 是否有任何标志或设置可以帮助我利用Spark中Hive外部表的分区?谢了。
-
配置单元分区表读取所有分区,尽管有Spark过滤器
但是我得到了这个错误: sparkException:由于阶段失败而中止作业:阶段0.0中的任务236失败4次,最近的失败:阶段0.0中丢失任务236.3(TID 287,server,executor 17):org.apache.hadoop.security.AccessControlException:权限被拒绝:user=user,access=read,inode=“/path-to-
-
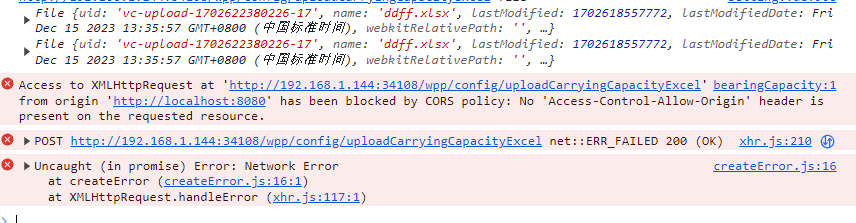 前端 - vue上传文件一直报错,该配的也写上了,但是一直上传不上去,这是为什么呢?
前端 - vue上传文件一直报错,该配的也写上了,但是一直上传不上去,这是为什么呢?上传报错:
-
在Python中将以分号分隔的字符串拆分为字典
问题内容: 我有一个看起来像这样的字符串: Python中是否有内置类/函数将采用该字符串并构造一个字典,就像我已经做到了那样: 我浏览了可用的模块,但似乎找不到任何匹配的模块。 谢谢,我确实知道如何自己编写相关代码,但是由于此类较小的解决方案通常是等待发生的雷区(即有人写道:Name1 =’Value1 = 2’;)等,因此我通常更喜欢使用测试功能。 那我自己去做 问题答案: 没有内置功能,但是
-
使用由分隔符Java分隔的位置值拆分字符串
我有一个输入字符串,其中包含由分隔符(| |)分隔的4个ID。我使用的代码如下: 但有些情况下并非所有ID都存在,如: 在上面的场景中,拆分不会分为4个部分,并且无法判断拆分数组中缺少哪个id。 有人可以帮助一个有效的解决方案。
-
Spark分区:创建RDD分区,但不创建配置单元分区
这是将Spark dataframe保存为Hive中的动态分区表的后续操作。我试图在答案中使用建议,但无法在Spark 1.6.1中使用 任何推动这一进程的帮助都是感激的。 编辑:还创建了SPARK-14927
-
如何制作一个3xp直径的圆形Javafx按钮?
问题内容: 我想制作一个非常小的圆形按钮,上面没有文字。这是我尝试过的方法。 但是,存在两个问题: 1.按钮的形状不是完美的圆形,而是更像椭圆形。 2. ;无效。正如我认为,它的 直径超过3 … 我如何才能让一个较小的圆按钮?帮助表示赞赏。 问题答案: 更新:在仔细查看结果按钮时,像在José答案中那样设置形状似乎在很小的按钮上比 -fx-background-radius在此答案中使用设置更好(