
Apache Spark未使用配置单元分区外部表中的分区信息

我有一个简单的配置单元-外部表,它是在S3的顶部创建的(文件是CSV格式的)。当我运行配置单元查询时,它会显示所有记录和分区。
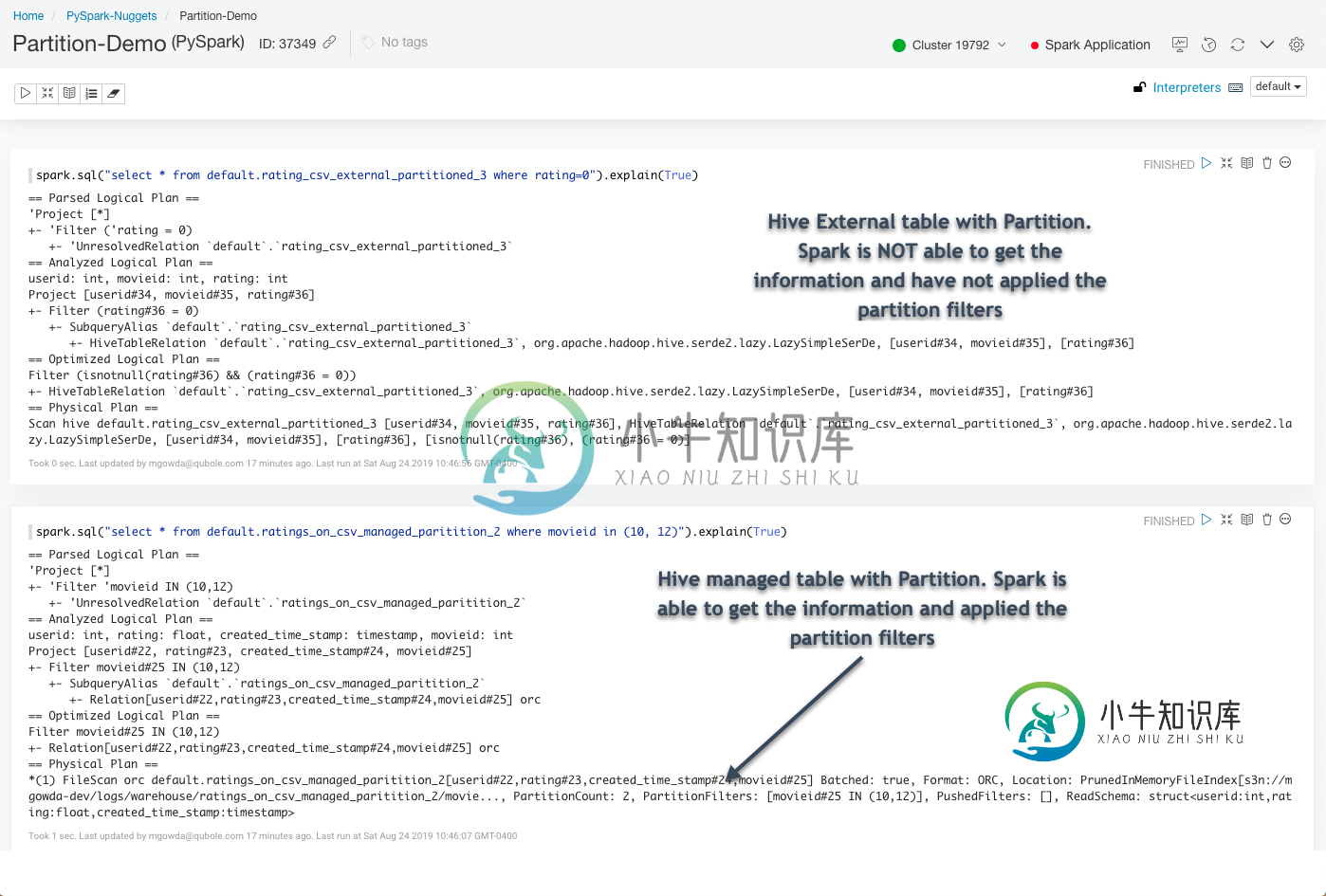
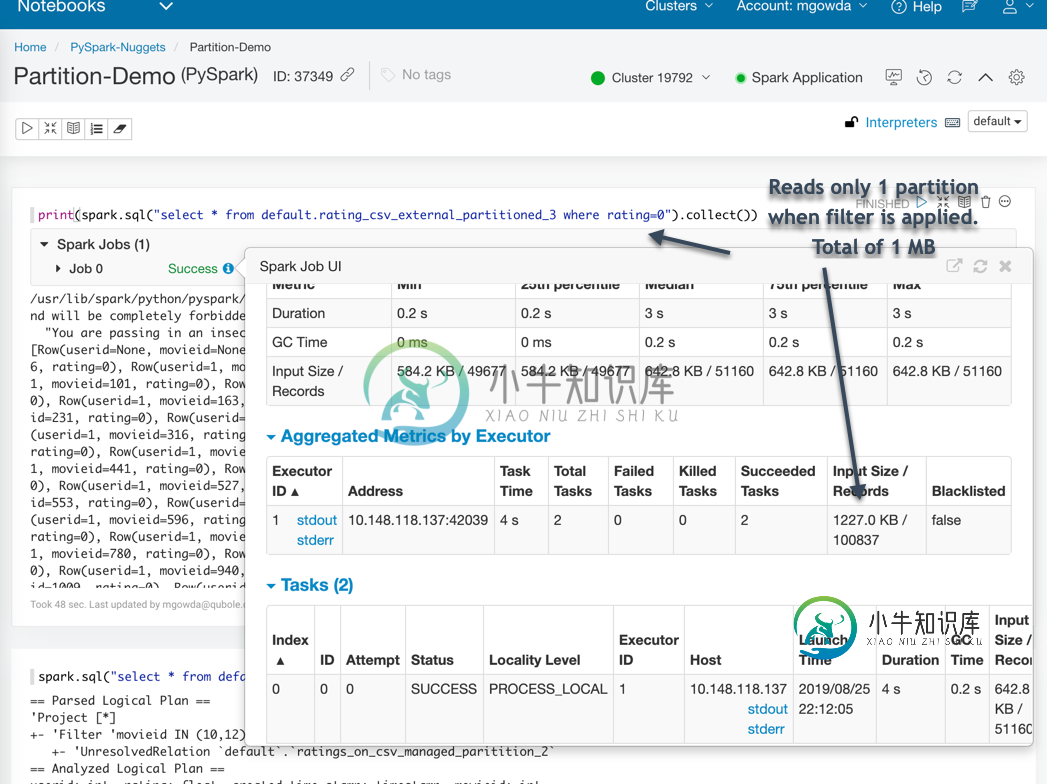
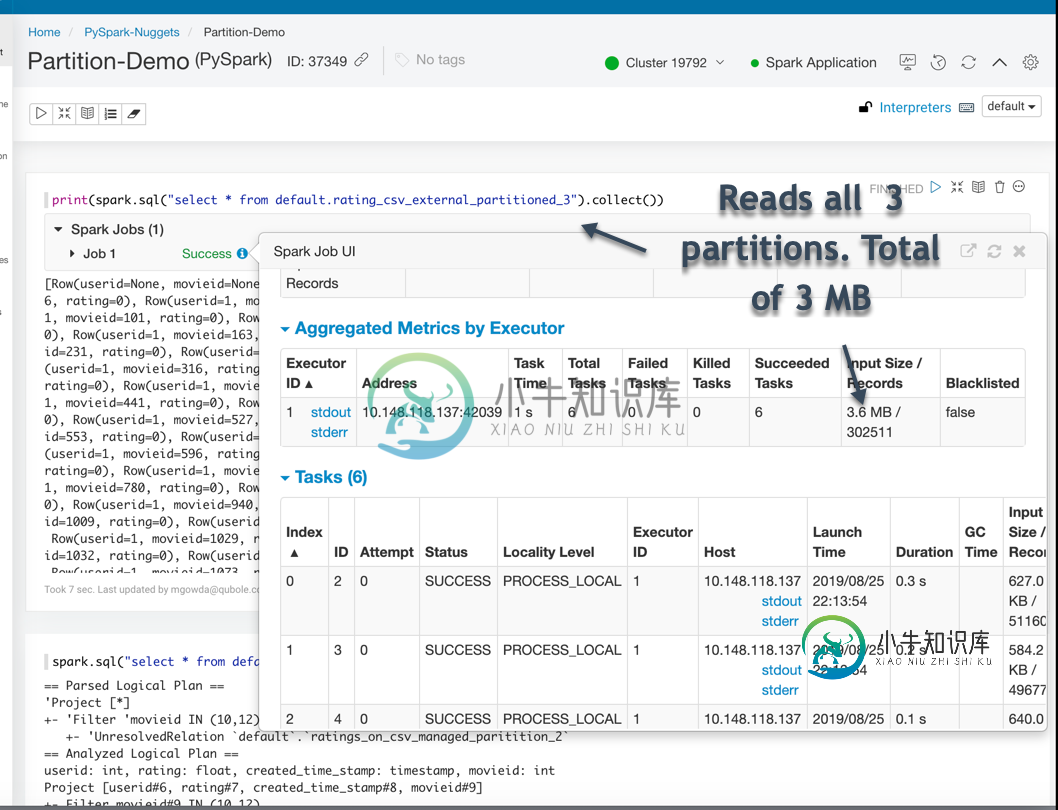
但是,当我在Spark中使用相同的表时(Spark SQL在分区列上有where条件),它并没有显示应用了分区筛选器。然而,对于配置单元托管表,Spark能够使用分区信息并应用分区筛选器。
是否有任何标志或设置可以帮助我利用Spark中Hive外部表的分区?谢了。
共有1个答案

TL;dr在运行外部表的sql之前设置了以下内容spark.sql(“set spark.sql.hive.convertmetastoreorc=true”)
行为差异不是由于Extenal/Managed表。
行为取决于两个因素
1。创建表的位置(配置单元或火花)
2。文件格式(我相信在这种情况下是ORC,从屏幕截图来看)
如果该表是使用Spark API创建的,则将其视为Datasource表。
如果该表是用HiveQL创建的,则将其视为配置单元本机表。
这两个表的元数据都存储在配置单元转移中,唯一的区别在于这些表的TBLProperties的provider字段(description extended
)。属性的值在Spark表中为orc或empty,而在配置单元中为hive。
当provider不是Hive(数据源表)时,Spark使用其本地方式处理数据。
如果provider是Hive,Spark使用Hive代码处理数据。
Spark给出配置标志,指示引擎使用Datasource方式处理floowing文件格式=ORC和Parquet标志的数据:
val CONVERT_METASTORE_ORC = buildConf("spark.sql.hive.convertMetastoreOrc")
.doc("When set to true, the built-in ORC reader and writer are used to process " +
"ORC tables created by using the HiveQL syntax, instead of Hive serde.")
.booleanConf
.createWithDefault(true)
val CONVERT_METASTORE_PARQUET = buildConf("spark.sql.hive.convertMetastoreParquet")
.doc("When set to true, the built-in Parquet reader and writer are used to process " +
"parquet tables created by using the HiveQL syntax, instead of Hive serde.")
.booleanConf
.createWithDefault(true)
-
我有一个复杂的/嵌套的配置单元外部表,它是在HDFS顶部创建的(文件是avro格式的)。当我运行配置单元查询时,它会显示所有记录和分区。 然而,当我在Spark中使用相同的表时: 请注意,当我查看数据时,分区列不是底层保存数据的一部分,但当我通过hive查询表时,我可以看到它。当我尝试使用PySpark加载avro文件时,我也可以看到分区列: 所以我想知道那是什么样子?
-
当使用外部配置单元表时,是否有一种方法可以删除目录中的数据,但通过查询保留分区。请注意,我不想删除表并重新创建它。我只想清空底层文件夹并重新启动一个进程。我的表很大,按年、月、日期和小时划分分区,手动重新创建分区需要大量时间。 谢谢
-
1-创建了源表 2-将数据从本地加载到源表 3-创建了另一个带有分区的表-partition_table 我不确定如何在外部表中进行分区。有人能帮我一步一步地描述一下吗?。
-
我有一个配置单元外部表,有3个分区列(a,B,C),现在我想从分区中删除B和C列。这样做可能吗?我已经尝试使用Alter table tab_name drop column col_name;---但它会抛出一个错误,说明无法删除分区列。
-
插入覆盖表myTable分区(字段)从myTable中选择*,其中机器='xxxxx' 但是SELECT中的数据不会替换MyTable中的数据。
-
在创建配置单元表时,如果使用分区或关键字群集,配置单元将创建对应于每个分区或桶的单独文件。但是对于外部表,这仍然有效。根据我的理解,与外部文件相对应的数据文件不是由hive管理的。同样,hive也会创建对应于每个分区或bucket的附加文件,并将相应的数据移到这些文件中。 编辑-添加详细信息。 摘自“Hadoop:权威指南”-“第17章:配置单元” 当我们将数据加载到分区表中时,分区值是显式指定的