
配置单元:配置单元在使用外部表时是否支持分区和bucketing

在创建配置单元表时,如果使用按分区或按关键字群集,配置单元将创建对应于每个分区或桶的单独文件。但是对于外部表,这仍然有效。根据我的理解,与外部文件相对应的数据文件不是由hive管理的。同样,hive也会创建对应于每个分区或bucket的附加文件,并将相应的数据移到这些文件中。
编辑-添加详细信息。
摘自“Hadoop:权威指南”-“第17章:配置单元”创建表日志(ts BIGINT,line STRING)按(dt STRING,country STRING)分区;
当我们将数据加载到分区表中时,分区值是显式指定的:
将数据本地INPATH“input/hive/partitions/file1”加载到表日志分区(DT='2001-01-01',country='gb');
在文件系统级别,分区只是表目录的嵌套子目录。将更多文件加载到logs表中后,目录结构可能如下所示:
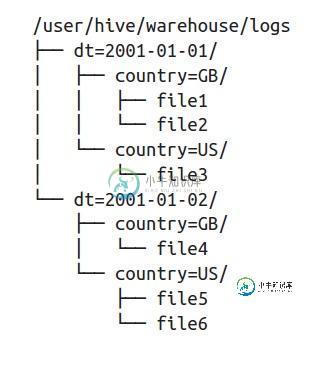
上面的表显然是一个托管表,因此hive拥有数据的所有权,并为每个分区创建目录结构,就像上面的树结构一样。
共有1个答案

假设在日期上分区,因为这是一件常见的事情。
CREATE EXTERNAL TABLE mydatabase.mytable (
var1 double
, var2 INT
, date String
)
PARTITIONED BY (date String)
LOCATION '/user/location/wanted/';
然后添加您所有的分区;
ALTER TABLE mytable ADD PARTITION( date = '2017-07-27' );
ALTER TABLE mytable ADD PARTITION( date = '2017-07-28' );
诸如此类。
最后,您可以在适当的位置添加数据。您将有一个外部分区文件。
-
我在java中开发了一个工作正常的配置单元udf,我的函数返回输入与配置单元表中列之间的最佳匹配,因此它有以下简化的伪代码: 我的问题是,如果这个函数是由Hive调用的,为什么我需要在代码中连接到Hive?我可以使用使用我的功能的用户所连接的当前连接吗?
-
1-创建了源表 2-将数据从本地加载到源表 3-创建了另一个带有分区的表-partition_table 我不确定如何在外部表中进行分区。有人能帮我一步一步地描述一下吗?。
-
当使用外部配置单元表时,是否有一种方法可以删除目录中的数据,但通过查询保留分区。请注意,我不想删除表并重新创建它。我只想清空底层文件夹并重新启动一个进程。我的表很大,按年、月、日期和小时划分分区,手动重新创建分区需要大量时间。 谢谢
-
我有一个复杂的/嵌套的配置单元外部表,它是在HDFS顶部创建的(文件是avro格式的)。当我运行配置单元查询时,它会显示所有记录和分区。 然而,当我在Spark中使用相同的表时: 请注意,当我查看数据时,分区列不是底层保存数据的一部分,但当我通过hive查询表时,我可以看到它。当我尝试使用PySpark加载avro文件时,我也可以看到分区列: 所以我想知道那是什么样子?
-
我有一个简单的配置单元-外部表,它是在S3的顶部创建的(文件是CSV格式的)。当我运行配置单元查询时,它会显示所有记录和分区。 但是,当我在Spark中使用相同的表时(Spark SQL在分区列上有where条件),它并没有显示应用了分区筛选器。然而,对于配置单元托管表,Spark能够使用分区信息并应用分区筛选器。 是否有任何标志或设置可以帮助我利用Spark中Hive外部表的分区?谢了。
-
插入覆盖表myTable分区(字段)从myTable中选择*,其中机器='xxxxx' 但是SELECT中的数据不会替换MyTable中的数据。