《分库分表》专题
-
请你简单介绍一下,数据库水平切分与垂直切分
本文向大家介绍请你简单介绍一下,数据库水平切分与垂直切分相关面试题,主要包含被问及请你简单介绍一下,数据库水平切分与垂直切分时的应答技巧和注意事项,需要的朋友参考一下 考察点:数据库 垂直拆分就是要把表按模块划分到不同数据库表中(当然原则还是不破坏第三范式),这种拆分在大型网站的演变过程中是很常见的。当一个网站还在很小的时候,只有小量的人来开发和维护,各模块和表都在一起,当网站不断丰富和壮大的
-
mysql分表和分区的区别浅析
本文向大家介绍mysql分表和分区的区别浅析,包括了mysql分表和分区的区别浅析的使用技巧和注意事项,需要的朋友参考一下 数据库的数据量达到一定程度之后,为避免带来系统性能上的瓶颈。需要进行数据的处理,采用的手段是分区、分片、分库、分表。 一、什么是mysql分表和分区 什么是分表,从表面意思上看呢,就是把一张表分成N多个小表 什么是分区,分区呢就是把一张表的数据分成N多个区块,这些区块可以在同
-
控制台-频道-分类-分类列表
控制台-频道-分类-分类列表 接口URL {youke-url}/console/Index.php?c=live&a=categoryList×tamp=1607677497&access_key=abc&sign=c7da8103312da8793af4f526a42cb6ebaa06cfd4 请求方式 POST Content-Type form-data 请求Query参数 参数
-
区分关系型数据库与非关系型数据库
一种是关系数据库,典型代表产品:DB2; 另一种则是层次数据库,代表产品:IMS层次数据库。 非关系型数据库有MongoDB、memcachedb、Redis等。
-
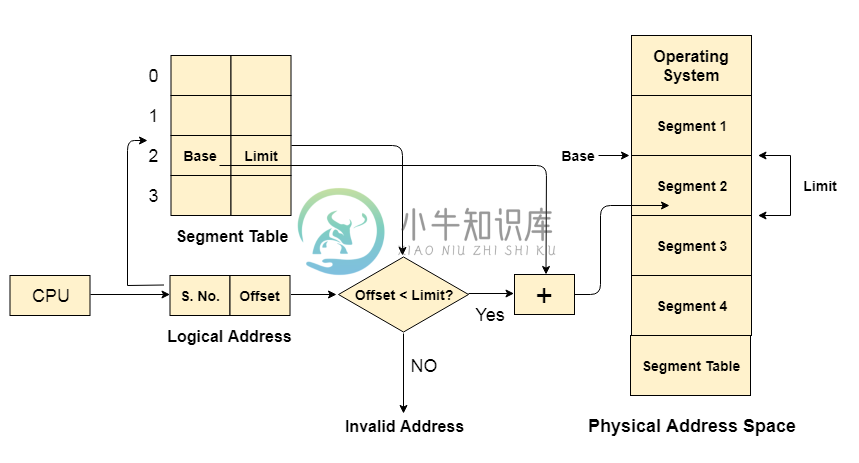 分段
分段主要内容:为什么需要分段?,逻辑地址按段表转换为物理地址在操作系统中,分段是一种内存管理技术,其中内存分为可变大小的部分。 每个部分被称为可以分配给进程的段。 有关每个段的详细信息存储在称为段表的表中。 分段表存储在一个(或多个)分段中。 分段表主要包含两个关于分段的信息: 基:它是细分分段的基地址 限制:它是分段的长度。 为什么需要分段? 到目前为止,我们使用分页作为主要内存管理技术。 分页更接近操作系统而不是用户。 它将所有进程划分为页面形式,而不
-
分页
Django提供了一些类来帮助你管理分页的数据 -- 也就是说,数据被分在不同页面中,并带有“上一页/下一页”标签。这些类位于django/core/paginator.py中。 示例 向Paginator提供对象的列表,以及你想为每一页分配的元素数量,它就会为你提供访问每一页上对象的方法: >>> from django.core.paginator import Paginator >>> o
-
分析
StackExchange.Redis公开了一些方法和类型来启用性能分析。 由于其异步和多路复用 表现分析是一个有点复杂的主题。 接口 分析接口由 IProfiler, ConnectionMultiplexer.RegisterProfiler(IProfiler) ,ConnectionMultiplexer.BeginProfiling(object) , ConnectionMultipl
-
分页
当一次要在一个页面上显示很多数据时,通常需要将其分成几部分, 每个部分都包含一些数据列表并且一次只显示一部分。这些部分在网页上被称为分页。 Yii 使用 yii\data\Pagination 对象来代表分页方案的有关信息。特别地, total count 指定数据条目的总数。 注意,这个数字通常远远大于需要在一个页面上展示的数据条目。 page size 指定每页包含多少数据条目。 默认值为 2
-
分类
在上几章中我们使用用户对物品的评价来进行推荐,这一章我们将使用物品本身的特征来进行推荐。这也是潘多拉音乐站所使用的方法。 内容: 潘多拉推荐系统简介 特征值选择的重要性 示例:音乐特征值和邻域算法 数据标准化 修正的标准分数 Python代码:音乐,特征,以及简单的邻域算法实现 一个和体育相关的示例 特征值抽取方式一览 数据集: athletesTrainingSet.txt athletesTe
-
分号
Semicolons 分号 Like C, Go’s formal grammar uses semicolons to terminate statements, but unlike in C, those semicolons do not appear in the source. Instead the lexer uses a simple rule to insert semicol
-
分页
简介 在 Linux 内核启动过程中的第五部分,我们学到了内核在启动的最早阶段都做了哪些工作。接下来,在我们明白内核如何运行第一个 init 进程之前,内核初始化其他部分,比如加载 initrd ,初始化 lockdep ,以及许多许多其他的工作。 是的,那将有很多不同的事,但是还有更多更多更多关于内存的工作。 在我看来,一般而言,内存管理是 Linux 内核和系统编程最复杂的部分之一。这就是为什
-
积分
积分部分 获取积分配置 积分流水 发起充值 取回凭据 充值回调 发起提现 发起 IAP(in-App Purchase) 充值 验证 IAP 订单 获取苹果IAP商品列表 积分商城(待开发) IAP帮助页面 获取积分配置 GET /currency 响应 Http Status 200 { "recharge-ratio": 1, "recharge-options": "100, 5
-
分支
分支变换与组合变换恰好相反,它通常是由一个上游节点以特定的规则分离出不同的下游节点。下面是全部的分支变换形式。 switch-case-default switch-case-default 变换是通过给出的 block 将每个上游的值代入,求出唯一标识符,再分离这些标识符的一种操作。我们举例一个分离剧本的例子: EZRMutableNode<NSString *> *node = [EZRMut
-
分类
获取全部圈子分类 获取全部圈子分类 GET /categories 响应 status 200 [ { "id": 1, "name": "123123", "sort_by": 1000, "created_at": "2017-11-27 10:06:38", "updated_at": "2017-11-27 10:06:40" } ]
-
分类
获取资讯分类 订阅分类 获取资讯分类 返回全部资讯分类和已订阅的分类,在未登录或未订阅状态下已订阅分类随机返回5个分类 GET /news/cates Response Headers Status: 200 OK Body { "my_cates": [ { "id": 1, "name": "热门" }, { "id": 2, "name":