《分库分表》专题
-
分类
函数 说明 Pandas 定义自定义数据类型,用于表示只能接受有限的固定值集的数据。类别的 dtype 可以由 pandas.api.types.CategoricalDtype 得到 api.types.CategoricalDtype([categories, ordered]) 具有类别和有序性的分类数据类型 api.types.CategoricalDtype.categories 包含允
-
分组
可以使用括号将节点分组,也就是创建一个子图;分组会提示布局器尽量把组里面的节点放在相近的地方。 ( German Cities [ Berlin ] -> [ Potsdam ] ) { border-style: dashed; } ................................... : German Cities: : :
-
分页
Microscope 的功能看起来不错。我们可以想象当它 release 之后会很受欢迎。 因此我们需要考虑一下随着新帖子越来越多所带来的性能问题。 之前我们说过客户端集合会包含服务器端数据的一个子集。我们在帖子和评论集合已经实现了这些。 但是现在,如果我们还是一口气发布所有帖子给所有的连接用户。当有成千上万的新帖子时,这会带来一些问题。为了解决这些,我们需要给帖子分页。 添加更多的帖子 首先是我
-
分片
Chunk 条目 说明 修改 Chunk 默认大小 Chunk 默认大小为 64 MB,允许 Chunk 大小的范围是 1MB - 1024MB。 连接到 mongos,修改 Chunk 大小为 100 MB use config db.settings.save( { _id:"chunksize", value: 100 } ) 配置集合分片 执行如下命令,如果集合不为空,需要基于片键创建索引
-
分页
简介 在 Linux 内核启动过程中的第五部分,我们学到了内核在启动的最早阶段都做了哪些工作。接下来,在我们明白内核如何运行第一个 init 进程之前,内核初始化其他部分,比如加载 initrd ,初始化 lockdep ,以及许多许多其他的工作。 是的,那将有很多不同的事,但是还有更多更多更多关于内存的工作。 在我看来,一般而言,内存管理是 Linux 内核和系统编程最复杂的部分之一。这就是为什
-
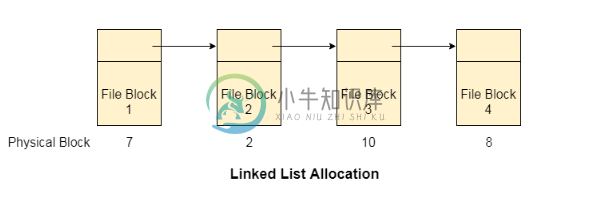 链表分配
链表分配链表分配解决了连续分配的所有问题。 在链表分配中,每个文件都被视为磁盘块的链表。 但是,分配给特定文件的磁盘块不需要在磁盘上连续存在。 分配给文件的每个磁盘块都包含一个指向分配给同一文件的下一个磁盘块的指针。 优点 链接分配没有外部碎片。 可以使用任何空闲块来满足文件块请求。 只要空闲块可用,文件可以继续增长。 目录条目将仅包含起始块地址。 缺点 随机访问不提供。 指针在磁盘块中需要一些空间。 链
-
Oracle表分区
现在,当我执行这个查询时: 请帮助我 1。既然分区不在ITEM_COLOR列上,Oracle将如何确定要转到哪个分区? 2。上面的查询不会从分区中受益吗? 3。SQL查询是否需要在WHERE子句中包含分区列,以便从分区中受益。 4。在分区的情况下如何使用索引?
-
部分类/部分类文件
问题内容: 在C#.net中,有一个规定,要有两个不同的类文件,并使用关键字partial关键字使它们成为一个类。这有助于将[UI]和逻辑分开。当然,我们可以有两个类来实现这一类,一个用于UI,另一个用于逻辑。可以在Java中实现吗? 问题答案: 源文件分割 不能。Java源代码不能拆分为多个文件。 摘自Wikipedia文章 Java和C Sharp的比较 Sun Microsystems Ja
-
DisplayTag分页与休眠分页
问题内容: 显示标签提供给定对象的分页功能。Hibernates提供了仅提取每页所需记录的选项。在我的项目中,我们同时使用了这两个概念。 显示广告代码:我需要根据过滤条件提取所有记录并将其存储在会话中。然后这个displaytag将负责所有分页和排序。因此Httpsession拥有很多数据。 hibernate:它仅从数据库中获取请求的对象数,无需为每个请求打开会话。 最好的做事方法是什么?或者如
-
Kafka分区分配的概念?
本文向大家介绍Kafka分区分配的概念?相关面试题,主要包含被问及Kafka分区分配的概念?时的应答技巧和注意事项,需要的朋友参考一下 一个topic多个分区,一个消费者组多个消费者,故需要将分区分配个消费者(roundrobin、range)
-
降维 - PCA(主成分分析)
1 主成分分析原理 主成分分析是最常用的一种降维方法。我们首先考虑一个问题:对于正交矩阵空间中的样本点,如何用一个超平面对所有样本进行恰当的表达。容易想到,如果这样的超平面存在,那么他大概应该具有下面的性质。 最近重构性:样本点到超平面的距离都足够近 最大可分性:样本点在这个超平面上的投影尽可能分开 基于最近重构性和最大可分性,能分别得到主成分分析的两种等价推导。 1.1 最近重构性
-
Python中的主成分分析
问题内容: 我想使用主成分分析(PCA)进行降维。是否已经有numpy或scipy,或者我必须使用自己滚动? 我不只是想使用奇异值分解(SVD),因为我的输入数据具有很高的维数(约460个维数),因此我认为SVD比计算协方差矩阵的特征向量要慢。 我希望找到一个预制的,已调试的实现,该实现已经对何时使用哪种方法以及哪些可能进行的其他优化进行了正确的决策,而这些优化我都不知道。 问题答案: 您可以看看
-
不可分裂的分裂器
我试图了解是如何工作的,以及拆分器是如何设计的。我认识到可能是更重要的方法之一,但是当我看到一些第三方实现时,有时我看到他们的拆分器无条件地为返回null。 问题: 普通迭代器和无条件返回null的拆分器有何不同?这样的分裂者似乎违背了分裂的目的
-
快速排序:分区分析
我正在学习快速排序在第四算法课程,罗伯特塞奇威克。 我想知道quicksort代码的以下分区是长度为n的数组中比较的个数。
-
整数个分区的分区
整数n的划分是将n写成正整数和的一种方式。对于 例如,对于n=7,一个分区是1 1 5。我需要一个程序来查找所有 使用“r”整数对整数“n”进行分区。例如,