《Jupyter》专题
-
jupyter笔记本SSH隧道为两步ssh隧道
我想通过SSH隧道访问jupyter笔记本,并遵循以下方法 要总结-: 1.登录远程机器 2.在新航站楼: 3.然后转到浏览器,然后转到 现在我的问题是:我只能在两个步骤中访问远程机器 jupyter笔记本电脑只安装在我的电脑上。 当我用较长的登录过程替换第一步的第一行时,第二步应该写什么? 当我插入remote_user=username和remote_user=my_pc_name时,我从ju
-
重新连接远程Jupyter笔记本并获取当前电池输出
我目前正在远程服务器上使用jupyter笔记本训练神经网络。我设置了以下内容: tmux jupyter-笔记本-无-浏览器-端口=5000 用浏览器连接到jupyter笔记本,并执行训练单元(当我观看前10分钟时,输出很好) 分离tmux(ctrl-b, d)并关闭浏览器选项卡 现在,当我重新连接到浏览器中的jupyter笔记本时,我看不到训练单元的当前输出,只有我在观看前10分钟训练时看到的输
-
创建ssh隧道到运行Jupyter Notebook的远程docker容器
我想创建一个ssh隧道,从我的计算机到远程服务器,再到运行Jupyter Notebook(计算机)的docker容器 Docker容器托管在运行OS X(El Capitan)的机器上。Docker正在使用默认的机器IP:192.168.99.100。 我可以坐在运行Docker容器的服务器上,使用浏览器(192.168.99.100:8888)从Docker容器创建Jupyter笔记本。这将验
-
无法使用netowrk_mode访问docker容器中的jupyterhub: host
我有一个jupyterhub运行在一个容器与network_mode:主机由于一些要求。但是,在我的docker-comment文件中将network_mode设置为主机后,我无法使用主机ip: 8000从外部主机访问jupyterhub。 我的理解是 如果对容器使用主机网络模式,则该容器的网络堆栈不会与Docker主机隔离(容器共享主机的网络名称空间),并且容器不会获得分配的自己的IP地址。例如
-
同一个内核中Jupyter和Terminal的区别
我尝试在脚本中< code >将tensorflow作为ts导入。虽然笔记本中的一切都很好,但当我尝试在. py文件中重新创建相同的脚本时,导入会返回以下常见消息: < code>ModuleNotFoundError:没有名为“tensorflow”的模块 请注意,Jupyter和terminal都使用相同的虚拟环境。在笔记本中,它被选作内核,在终端中,它由< code>conda激活。 我确信
-
如何使用Jupyter笔记本访问远程smb驱动器上的文件?
所以,我试图使用Python/Jupyter笔记本做一些数据分析。数据集位于远程smb共享驱动器上。如何在不下载到本地计算机的情况下读取数据? 我尝试通过运行以下命令更改工作目录: 我得到一个“没有这样的文件或目录”错误。 我将感谢任何人能提供的任何帮助!
-
在EMR上使用Spark上的Jupyter笔记本
连接到Spark:pyspark_driver_python=/usr/local/bin/jupyter pyspark_driver_python_opts=“notebook--no-browser--port=7777”pyspark--packages com.databricks:spark-csv2.10:1.1.0--master spark://127.0.0.1:7077--e
-
访问在AWS中运行的Jupyter-访问它时获取证书错误
[E 06:33:24.239 NotebookApp]回调中的异常(,.null_wrapper at 0x7f5689fcdd90>)回溯(最近的调用为last):文件“/home/ubuntu/anaconda3/lib/python3.6/site handler_func(fd_obj,events)中的”/home/ubuntu/anaconda3/libado/ioloop.py“,
-
运行jupyter笔记本时出现ec2 ubuntu名称或服务未知错误
我正在使用ec2和ubuntu 18机器,并希望安装jupyter笔记本,我遵循了这个教程,并不断得到这个错误: Traceback(最近的调用为last):文件“/home/ubuntu/.local/bin/jupyter-notebook”,第11行,在sys.exit(main())文件“/home/ubuntu/.local/lib/python3.6/site-packages/jup
-
将Jupyter笔记本连接到Spark
我有一台安装了Hadoop和Spark的机器。下面是我目前的环境。 Python3.6 /root/.ipython/profile_pyspark/startup/00-pyspark-setup.py /root/anaconda3/share/jupyter/kernels/pyspark/kernel.json kernel.json 所以,由于sc无法初始化,如果我想运行以下操作,它失败
-
如何从jupyter笔记本中访问pyspark
我在Ubuntu14.04上的ipython笔记本上成功地使用了pyspark[与python 2.7],为spark创建了一个特殊的配置文件,并通过调用$ipython笔记本--profile spark启动了笔记本。创建spark配置文件的机制在许多网站上都给出了,但我使用了这里给出的一个。 $home/.ipython/profile_spark/startup/00-pyspark-set
-
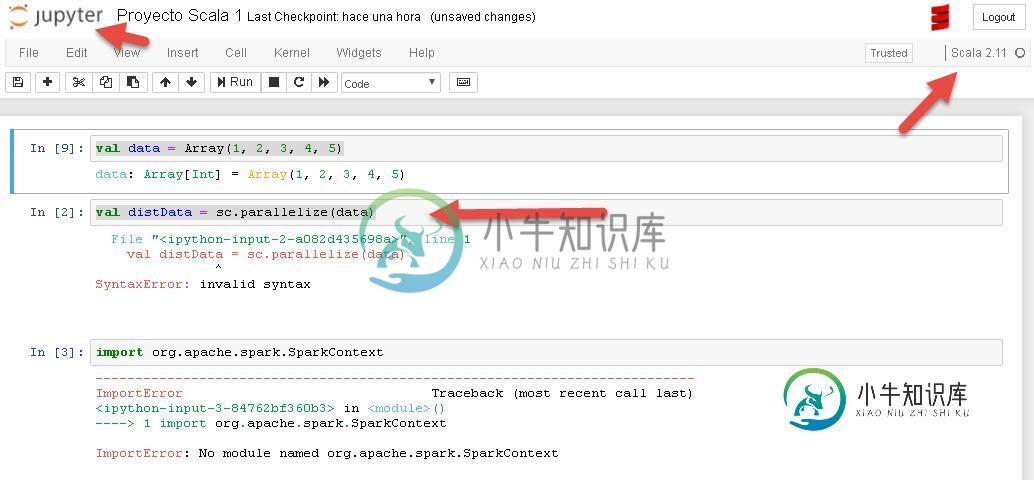 我不能从Jupyter运行scala
我不能从Jupyter运行scala我在jupyter中,选择kernel scala 2.11,当我放置返回数据时运行平稳: 然后,当我执行时,它返回
-
无法在Jupyter笔记本中导入scipy
C:\users\user\appdata\local\programs\python\python37\lib\site-packages\scipy__init__.py在154#中,这使得“from scipy import fft”返回scipy.fft,而不是np.fft 155 del fft-->156 from。导入fft C:\users\user\appdata\local\p
-
 HdInsight服务-Jupyter笔记本问题
HdInsight服务-Jupyter笔记本问题我在Microsoft Azure上部署了一个HDInsight 3.6 Spark(2.3)集群,使用标准配置(位置=美国中部,头节点=D12 v2(x2)-8个核心,工作节点=D13 v2(x4))-32个核心)。 在这方面有什么帮助吗
-
用HDI Jupyter Spark(Scala)笔记本配置外部JAR
我有一个外部自定义罐子,我想与Azure HDInsight Jupyter笔记本一起使用;HDI中的Jupyter笔记本使用Spark Magic和Livy。 在笔记本的第一个单元格中,我尝试使用配置: 但我收到的错误消息是: 我想知道我是否只是不明白Livy在这种情况下是如何工作的,因为我能够成功地在同一个集群中包含一个spark-package(GraphFrames): null