《CPU》专题
-
使用Sigar API获取JVM CPU使用率
问题内容: 我正在使用Sigar来获取应用程序服务器中当前正在运行的JVM的CPU使用率,并将其存储为该数据的历史视图,但是我总是获得0%的CPU百分比。 同时,我保持visualVM处于打开状态以监视CPU使用率,并且看到visualVM中的CPU%定期更改,而使用Sigar总是报告0%。 这是我定期运行的代码: 该代码始终给出0%。 在这种情况下,我在做什么错呢?如何让Sigar显示类似于Vi
-
在JSF saveState()期间,线程在HashMap中停留在100%CPU使用率
问题内容: 我们的生产环境中存在问题,HTOP命令中的4个线程的CPU使用率为100%。为了进一步研究该问题,我生成了一个线程转储,以查找正在占用CPU的线程。 这是我发现的。这4个线程具有相同的堆栈跟踪,所有堆栈跟踪均处于 RUNNABLE 状态。不幸的是,由于堆栈跟踪没有引用我的内部代码,所以我一直停留在调查中,而更多地是在Richfaces方面。我认为这是JSF呈现页面的部分。 堆栈跟踪。
-
Java的CPU负载
问题内容: 有没有一种方法可以在不使用JNI的情况下获取Java下的当前cpu负载? 问题答案: 使用获取并调用它。
-
iOS使用 CABasicAnimation 实现简单的跑马灯(无cpu暴涨)
本文向大家介绍iOS使用 CABasicAnimation 实现简单的跑马灯(无cpu暴涨),包括了iOS使用 CABasicAnimation 实现简单的跑马灯(无cpu暴涨)的使用技巧和注意事项,需要的朋友参考一下 网上找了几个,但都有cup暴涨的情况发生,于是利用CABasicAnimation 简单的实现一个跑马灯,实现简单,可自己定制 以上就是本文的全部内容,希望对大家的学习有所帮助,也
-
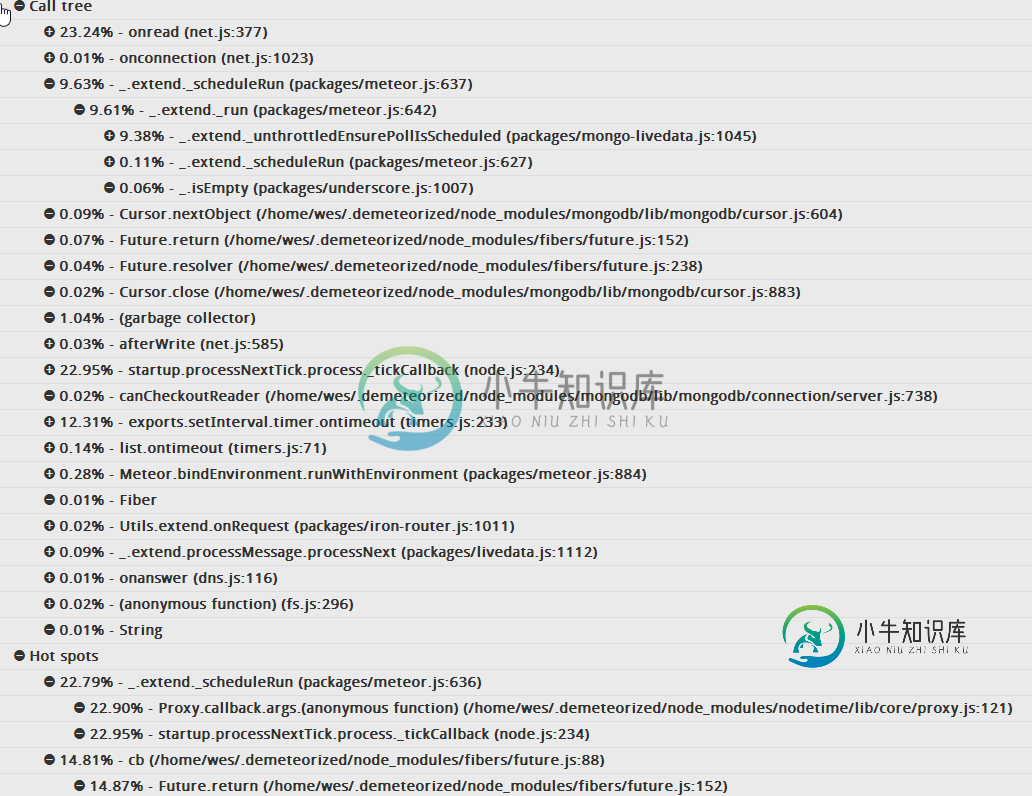 流星节点进程CPU使用率接近100%
流星节点进程CPU使用率接近100%问题内容: 当Meteor应用达到峰值流量时,我遇到了麻烦(请注意,这没什么,每天访问1000次,一天的综合浏览量可能为2500次)。CPU使用率会激增并且永远不会恢复,因此我开始使用Nodetime来监视使用率,并且我一直在重新加载进程()以使一切恢复正常。 我对概要分析还很陌生,因此找到根本原因使我不知所措。我相当确定它与我的应用程序的服务器代码有关,但性能分析似乎将Fibers模块指向“热点
-
Node.js和CPU密集型请求
问题内容: 我已经开始尝试使用Node.js HTTP服务器,并且真的很想编写服务器端Javascript,但是有些事情使我无法开始在Web应用程序中使用Node.js。 我了解整个异步I / O概念,但我对程序代码占用大量CPU资源的极端情况(如图像处理或对大型数据集进行排序)感到有些担忧。 据我了解,对于简单的网页请求(例如查看用户列表或查看博客帖子),服务器将非常快。但是,如果我想编写非常占
-
为什么node.js不适合重型CPU应用程序?
问题内容: Node.js服务器在I / O和大量客户端连接方面非常高效。但是,为什么与传统的多线程服务器相比,node.js不适合重型CPU应用程序? 我在这里读过Felix Baumgarten 问题答案: 尽管节点具有异步事件模型,但它本质上还是单线程的。启动Node进程时,您正在单个内核上的单个线程上运行单个进程。因此,您的 代码 将不会并行执行,只有I / O操作是并行的,因为它们是异步
-
C# 获取硬盘号,CPU信息,加密解密技术的步骤
本文向大家介绍C# 获取硬盘号,CPU信息,加密解密技术的步骤,包括了C# 获取硬盘号,CPU信息,加密解密技术的步骤的使用技巧和注意事项,需要的朋友参考一下 在我们编写好一款软件后,我们不想别人盗用我们的软件,这时候我们可以采用注册的方式来保护我们的作品。这时候我们可能就需要简单了解一下加密解密技术,下面是我的简单总结: 第一步:程序获得运行机的唯一标示(比如:网卡号,CPU编号,硬盘号等等)。
-
JMH是根据CPU时间还是挂钟时间计算每个时间单位的操作数?
考虑到JMH的默认用法,我想确定JMH的测量基于哪种时间类型:CPU时间还是挂钟。 我试着调查JMH的官方样本(https://openjdk.java.net/projects/code-tools/jmh/),教程(在Jenkov、Baeldung、Mykong和其他网站),但未能准确地找到这些信息(我承认我可能错过了一些关于基准测试的文档或一般信息)。 例如,在样本35中(https://h
-
32位和64位寄存器是否会导致CPU微架构的差异?
我试图比较Peter Cordes在回答“将CPU寄存器中的所有位设置为1”的问题时提到的方法。 因此,我编写了一个基准测试,将所有13个寄存器设置为除、和之外的所有位1。 代码如下所示<代码>乘以32 nop用于避免DSB和LSD影响。 我测试了他提到的以下方法,以及这里的完整代码 为了使这个问题更简洁,我将使用替换下表中的。 下表显示,从组1到组3,当使用64位寄存器时,每个循环多1个周期。
-
在单个CPU指令中可以在0和1之间翻转位/整数/布尔的任何可能的代码
一条x86指令可以在“0”和“1”之间切换布尔值吗? 我想到了以下的方法,但所有的结果是两个指令与-O3标志的GCC。 有没有更快的方法做到这一点? 这是我尝试的:https://godbolt.org/g/a3qnuw 我需要的是一个切换输入和返回的函数,以编译成一个指令的方式编写。与此函数类似的内容: 在Godbolt上对此进行编译:
-
使用Dropwizard指标报告JVM的CPU使用情况
我使用Dropwizard指标来衡量应用程序中的各种指标。它们是JVM检测中的几个预定义报告器,但奇怪的是,我找不到任何报告CPU使用情况的报告器。 我可以创建自己的Gauge(使用getThreadCpuTime或类似工具),但我最好的猜测是我错过了一些东西。 我是否在当前的实现中错过了它,或者它比我最初想象的更复杂?
-
是否因为cpu无序执行或缓存一致性问题而需要内存障碍?
我想知道为什么需要内存障碍,我读了一些关于这个Topic的文章 有人说这是因为cpu无序执行,而其他人说这是因为缓存一致性问题导致缓冲区存储和队列失效<那么,需要记忆障碍的真正原因是什么?cpu无序执行或缓存一致性问题?或者两者都有?cpu无序执行是否与缓存一致性有关?x86和arm之间有什么区别?
-
x86 CPU有多少个内存屏障指令?
我发现x86 CPU具有以下内存屏障指令:
-
了解CPU管道阶段与指令吞吐量
我错过了一些基本的东西。CPU管道:在基本层面上,为什么指令需要不同数量的时钟周期才能完成,为什么一些指令在多级CPU中只需要1个周期? 除了明显的“不同的指令需要不同的工作量来完成”,听我说完... 考虑具有大约14级流水线的i7。这需要14个时钟周期才能完成一次运行。AFAIK,这应该意味着整个流水线的延迟为14个时钟。然而事实并非如此。 XOR在1个周期内完成,延迟为1个周期,这表明它没有经