
流星节点进程CPU使用率接近100%

当Meteor应用达到峰值流量时,我遇到了麻烦(请注意,这没什么,每天访问1000次,一天的综合浏览量可能为2500次)。CPU使用率会激增并且永远不会恢复,因此我开始使用Nodetime来监视使用率,并且我一直在重新加载进程(forever restart)以使一切恢复正常。
我对概要分析还很陌生,因此找到根本原因使我不知所措。我相当确定它与我的应用程序的服务器代码有关,但性能分析似乎将Fibers模块指向“热点”,据我了解,这有助于使服务器代码同步。
以下是分析结果的摘要。我希望有人可以引导我朝着正确的方向进行故障排除!
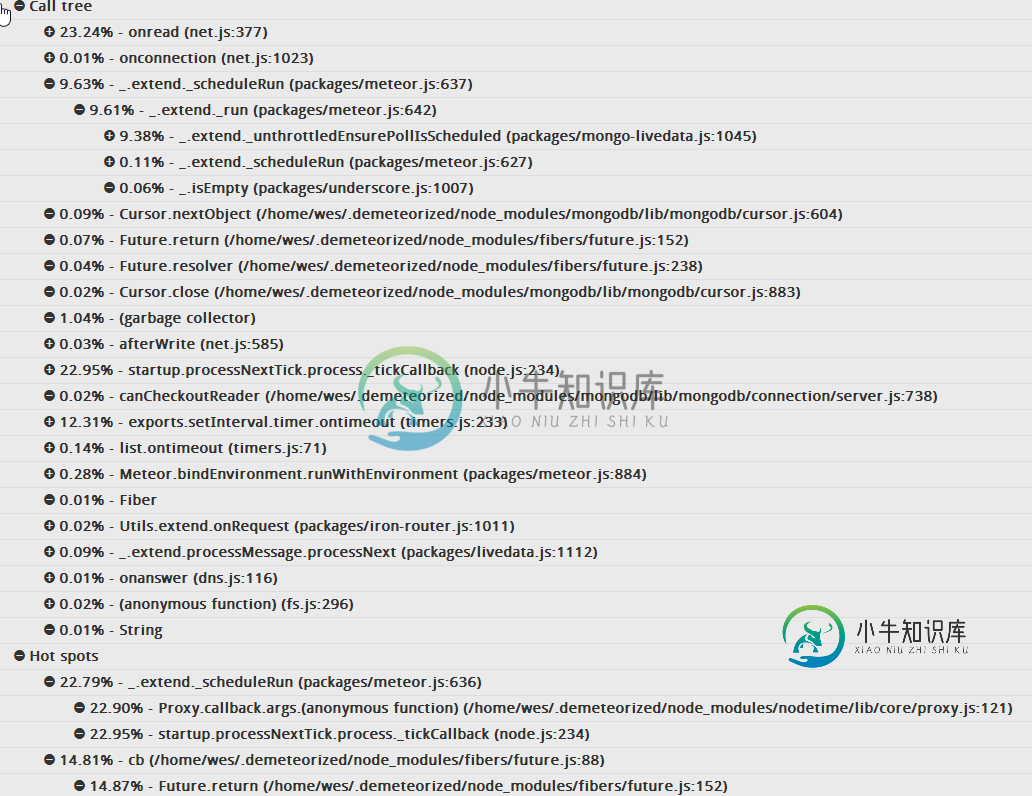
问题答案:
虽然我没有针对您问题的具体答案,但我有处理生产流星应用程序的CPU问题的经验,因此我可以向您提供要调查的事情的列表。
-
升级到最新版本的流星和相应的节点版本(请参阅changelog)。在撰写本文时,这是流星0.8.2和节点0.10.28。
-
阅读本文和这篇文章。后者提出了一个很好的观点,即您确实应该始终尝试延迟激活订阅,直到需要它们为止。特别是,您可能不需要为未登录的用户发布任何内容。根据我的经验,流星CPU问题与订阅有关。
-
请注意
observe和observeChanges。这些很 昂贵 ,很容易滥用。特别是:- 确保
stop()不再需要它们时调用它们的句柄(考虑使用诸如publish-with-relations之类的包,以便您完成此操作)。 - 仅获取您绝对需要的集合和字段。通过不断地扩散对象来观察工作(需要大量的CPU)。您拥有的对象越少,计算的内容就越少。
-
考虑使用 智能收藏它之前退休。使用oplog拖尾 -这可以使您的应用在性能和CPU使用率上昼夜不同。
- 确保
-
考虑使某些事物不具有反应性(在上面的文章中也提到过)。对我们来说,这是一个巨大的胜利。我们有一个非常昂贵的联接,该联接在站点上两个经常访问的页面上使用。当达到每30分钟将CPU固定为100%的程度时,我放弃了该元素的反应性,只是在服务器上进行了连接,并通过方法调用将数据发送给了客户端。我还为这些结果创建了一个服务器端过期缓存,并按用户存储了它们(特别感谢Matt DeBergalis的建议)。
-
每晚进行一次预防性重启。我有一份Cron作业,
forever每天半夜重启一次我们的应用程序。这使CPU从约10%降至1%。这似乎是不可思议的事情,但是在重置后CPU使用率发生变化的事实使我相信这是个好主意。
更新的想法(1/13/14)
-
我们尽快将其迁移到oplog尾矿(流星0.7),这带来了很大的变化。请注意,为了访问操作日志,您可能需要托管自己的数据库或在您选择的托管提供程序上运行专用实例。我还建议添加该
facts软件包,以实际判断其是否有效。 -
在中发现了内存泄漏
publish-with-relations,截至撰写本文时,大气版本(v0.1.5)并未受到影响以反映这些更改。如果您在生产环境中使用它,强烈建议您检出HEAD版本并在本地运行它。 -
几周前,我们停止了每晚重启。到目前为止,一切都很好(手指交叉)。
更新的想法(7/2/14)
-
几个月前,我们切换到在mongohq上使用弹性部署。它价格适中,性能非常好,他们甚至还有一篇博客文章,告诉您如何启用oplog拖尾。
-
我强烈建议您检出kadira,以帮助诊断您应用中的性能问题。另外,请查阅其中包含许多技巧的学术文章。
-
问题内容: 我正在尝试按以下方式计算Android中进程的CPU使用率,但是由于产生的输出,我不确定它是否正确。 要将吉菲转换为秒:吉菲/赫兹 第一步: 使用文件的第一个参数获取正常运行时间。 第二步: 从中获取每秒的时钟滴答数。 第三步: 从中获取过程参数花费的总时间 第四步: 从 Linux 2.6之后的时钟滴答声中除以sysconf(_SC_CLK_TCK)表示的值,获取进程的startti
-
问题内容: 我能否查看当前python应用程序正在使用的处理器使用量(占最大值的百分比)? 场景:只要不消耗超过X%的CPU能力,我的主机就可以允许我运行我的应用程序,因此我希望它“关注自身”并放慢速度。那么我如何知道该应用程序使用了多少CPU? 目标平台是* nix,但是我也想在Win主机上进行。 问题答案: 从(2.5)手册中: 次() 返回一个五元组的浮点数,以秒为单位指示累计(处理器或其他
-
我对我的pod的所有容器设置了CPU和内存请求=限制,以使其符合有保证的服务质量等级。现在,查看过去6小时内同一Pod的CPU使用率和CPU节流图。 这看起来是不是很正常,也在意料之中? CPU使用率甚至一次都没有达到设定限制的50%,但有时仍被限制在58%。 还有一个附带的问题,节流图中25%的红线表示什么? 我对这个主题做了一些研究,发现内核中有一个错误Linux可能导致这个问题,它在内核的4
-
我对运行的节点进程所看到的情况感到有点困惑。主机上的显示容器使用了超过100%的CPU。这让我认为节点进程正在耗尽CPU。当我在主机上运行并看到节点进程使用了超过100%的CPU时,就确认了这一点。 当我跳入docker容器时,我看到该节点只使用了54%的CPU,并且处理在两个内核之间进行。我希望看到一个核心被最大化,另一个为0,因为Node是单线程的。 我发现了这个QA,看起来操作系统可能在内核
-
在Kubernetes中使用CPU请求/限制时,我遇到了一个奇怪的问题。在设置任何CPU请求/限制之前,我的所有服务都执行得很好。我最近开始设定一些资源配额,以避免未来资源匮乏。这些值是根据这些服务的实际使用情况设置的,但令我惊讶的是,在添加这些值之后,一些服务开始大幅增加响应时间。我的第一个猜测是,我可能放置了错误的请求/限制,但查看这些指标发现,事实上,面对这个问题的服务中没有一个接近这些值。
-
问题内容: 我想获取Linux上单个进程的CPU和内存使用情况-我知道PID。希望我可以每秒获取一次,并使用“ watch”命令将其写入CSV。我可以使用什么命令从Linux命令行获取此信息? 问题答案: (您可以省略“ cmd”,但这可能有助于调试)。 请注意,这给出了该进程在运行期间的平均CPU使用率。