《CPU》专题
-
为什么kubernetes mini kube限制全局CPU使用率?
我在家用电脑上安装了minikube k8s(ubuntu20.04,amd 3950x,128gb RAM)。 a创建了2个部署和3个副本。每个pod可以使用1个核心CPU。这是部署之一: 所有POD的总CPU使用率始终限制为2个CPU。看起来有某种全局设置来限制CPU的使用。 是否可以启动多个吊舱,每个吊舱有1个CPU限制?
-
基于pod cpu使用的库伯内特斯负载平衡
我在pod中运行了高视频编码任务。这些任务在接收用户请求时运行,并且CPU密集型非常高。我想确保CPU使用率最低的pod应该在传入请求中接收。库伯内特斯有没有办法根据CPU使用率的百分比来平衡我的负载?
-
Kubernetes:POD的CPU资源分配
我正在尝试为kubernetes吊舱中运行的服务分配CPU资源。服务大多是基于nodejs的RESTendpoint,带有一些DB操作。 在负载测试期间,尝试在100米和1000米之间对吊舱进行不同的组合。对于每秒的预期请求数,当值小于 我不知道应该根据什么来选择特定的CPU资源值。有人能在这方面帮助我吗?
-
 为什么实际CPU利用率百分比超过Kubernetes的Pod CPU限制
为什么实际CPU利用率百分比超过Kubernetes的Pod CPU限制我正在我的a集群(10个节点)中运行几个kubernetes pod。每个pod只包含一个托管一个工作进程的容器。我已指定容器的CPU“限制”和“请求”。以下是在节点(crypt12)上运行的一个pod的描述。 以下是我运行“kubectl可描述节点crypt12”时的输出 更新:我在github问题讨论中找到了问题的答案:“kubectl描述节点”中的cpu百分比是“cpu限制/#个内核”。由于
-
 库伯内特斯CPU节流,CPU使用率远低于请求/限制
库伯内特斯CPU节流,CPU使用率远低于请求/限制我对我的pod的所有容器设置了CPU和内存请求=限制,以使其符合有保证的服务质量等级。现在,查看过去6小时内同一Pod的CPU使用率和CPU节流图。 这看起来是不是很正常,也在意料之中? CPU使用率甚至一次都没有达到设定限制的50%,但有时仍被限制在58%。 还有一个附带的问题,节流图中25%的红线表示什么? 我对这个主题做了一些研究,发现内核中有一个错误Linux可能导致这个问题,它在内核的4
-
在kubernetes中创建pod时,CPU和内存的请求和限制的默认值是什么?
首先,正如Kubernetes所描述的:pod和cpu限制当我们不指定cpu限制时,pod可以使用节点的所有cpu。这也适用于内存吗?意味着当我们没有指定限制时,pod是否会在需要时开始使用所有内存? 其次,让我们考虑一下,我们有一个具有2GB内存的工作节点,我们在这个节点上部署了8个POD,分配256Mi请求并限制这8个POD中的每一个是否正确?是否建议对所有POD应用相同的限制? 第三,如果我
-
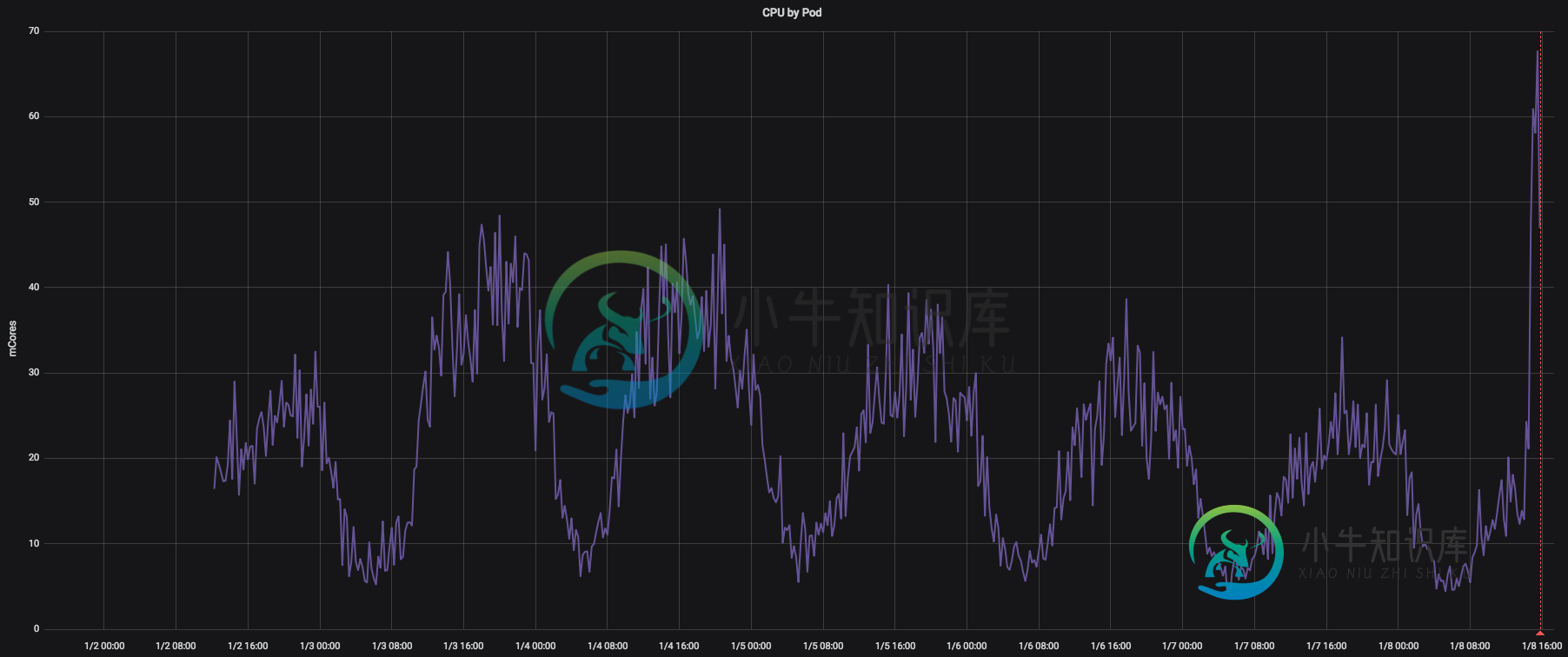 Pod CPU节流
Pod CPU节流在Kubernetes中使用CPU请求/限制时,我遇到了一个奇怪的问题。在设置任何CPU请求/限制之前,我的所有服务都执行得很好。我最近开始设定一些资源配额,以避免未来资源匮乏。这些值是根据这些服务的实际使用情况设置的,但令我惊讶的是,在添加这些值之后,一些服务开始大幅增加响应时间。我的第一个猜测是,我可能放置了错误的请求/限制,但查看这些指标发现,事实上,面对这个问题的服务中没有一个接近这些值。
-
MacOS上的Tensorflow:您的CPU支持该Tensorflow二进制文件未编译使用的指令:AVX2 FMA
我试着用这些说明来验证我的mac tensorflowhttps://www.tensorflow.org/install/install_mac#ValidateYourInstallation 但要产生这样的结果。可以吗?令人不快的我该怎么解决这个问题?谢谢 sess=tf。会话() 您的CPU支持该TensorFlow二进制文件未编译使用的指令:AVX2 FMA 打印(sess.run(你好
-
Tensorflow GPU错误“您的CPU支持指令…等”[重复]
刚刚安装了Cuda,使用我的GPU获取Tensorflow。我按照上面的说明做了https://www.tensorflow.org/install/gpu并在上运行了Cuda测试https://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/(deviceQuery和bandwidthTest)这两个测试都很好。 当我
-
如何使一个简单的程序使用所有的CPU[关闭]
这是一个面试问题。在压力测试中,CPU上不去。我希望它能降低所有CPU的速度,但我的程序很简单,我如何改变我的代码?
-
IntelliJ Scala 在具有 32GB RAM 的快速 CPU 上非常慢
我用的是IntelliJ 2019.1.3社区版。在Scala编译服务器中,< code>JVM最大堆大小:4096 my idea.vmoptions: 环境 IntelliJ IDEA 2019.1.3(社区版)构建#IC-191.7479.19,构建于2019年5月28日JRE:1.8.0_202-release-1483-b58 x86_64 JVM:JetBrains s.r.o mac
-
解决Java应用程序cpu负载过高的方法
今天,我发现我的服务器的cpu负载过高,而服务器只是在运行一个Java应用程序。 下面是我的操作步骤。 > 我使用命令查找应用程序的PID。pid为25713。 以下是我的问题: 为什么使cpu负载过高。 为什么在我使用命令后,cpu变得正常。 不止这一次,每一次。 当我执行命令时,打印的日志
-
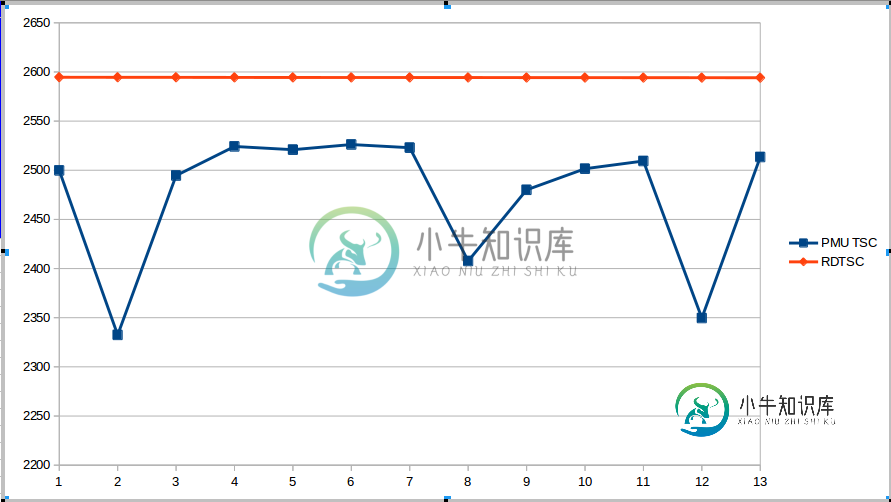 在情报上丢失的周期?rdtsc与CPU_CLK_UNHALTED.REF_TSC之间的不一致
在情报上丢失的周期?rdtsc与CPU_CLK_UNHALTED.REF_TSC之间的不一致在最近的CPU上(至少是过去十年左右),Intel提供了三种固定功能硬件性能计数器,此外还有各种可配置的性能计数器。三个固定柜台是: 第一个计算退役的指令,第二个计算实际循环的数量,最后一个计算我们感兴趣的。《英特尔软件开发人员手册》第3卷的描述如下: 当内核不处于停止状态和TM停止时钟状态时,此事件以TSC速率计算参考周期数。内核在运行HLT指令或MWAIT指令时进入halt状态。该事件不受核心
-
如何减少GC CPU使用的峰值
-
Java编译线程占用更多CPU
首先,我的问题是,为什么编译线程占用大量的CPU,以及如何最小化这一点,以便我们可以将CPU分配给其他线程。 提前感谢!