《均衡》专题
-
kube路由器IPVS最少连接算法,负载平衡是在同一个节点还是不同的节点?
我正在开发的应用程序作为kubernetes集群中的部署运行。为该部署创建的pod分布在集群中的各个节点上。我们的应用程序一次只能处理一个TCP连接,并将拒绝进一步的连接。目前,我们使用kube代理(Iptables模式)在各个节点的pod之间分配负载,但pod是以随机方式选择的,当其传递到繁忙的pod时,连接会断开。我可以在我的用例中使用Kube router的基于最小连接的负载平衡算法吗。我希
-
Kubernetes不在集群中的节点之间进行负载平衡
我按照此处找到的指南设置了一个 4 节点 Kubernetes 集群:https://www.tecmint.com/install-a-kubernetes-cluster-on-centos-8/ 它有一个主节点和3个工作节点。 我正在运行一个名为“hello world”的部署,它基于bashofmann/rancher演示映像,有20个副本。我还创建了一个名为hello world的nod
-
在负载平衡器后面使用Spring Security的Spring Boot:将HTTP重定向到HTTPS
我正在使用Elastic Beanstalk部署Spring Boot web服务器,运行在应用程序负载平衡器(Elastic load balancer)后面。业务规则是,只能通过HTTPS联系此web服务器。因此,任何HTTP请求都必须首先转发到HTTPS。 基于这篇来自Amazon的文章,我应该简单地检查由负载平衡器设置的和头文件。这些标头包含有关客户端向负载平衡器发出的原始请求的信息。 所
-
Engine Yard Rails应用程序-在弹性负载平衡器(ELB)处终止SSL并传递X-Forwarded-Proto http头
跟踪了https://support.cloud.engineyard.com/entries/21715452-use-elastic-load-balancing-with-engine-yard-cloud的引擎场医生 设置好后,似乎运行良好,允许我们在ELB上使用SSL端接,而不是在服务器上使用SSL端接。理论上,这应该允许我们在一个环境中使用多个SSL证书。 这种设置意味着浏览器和ELB
-
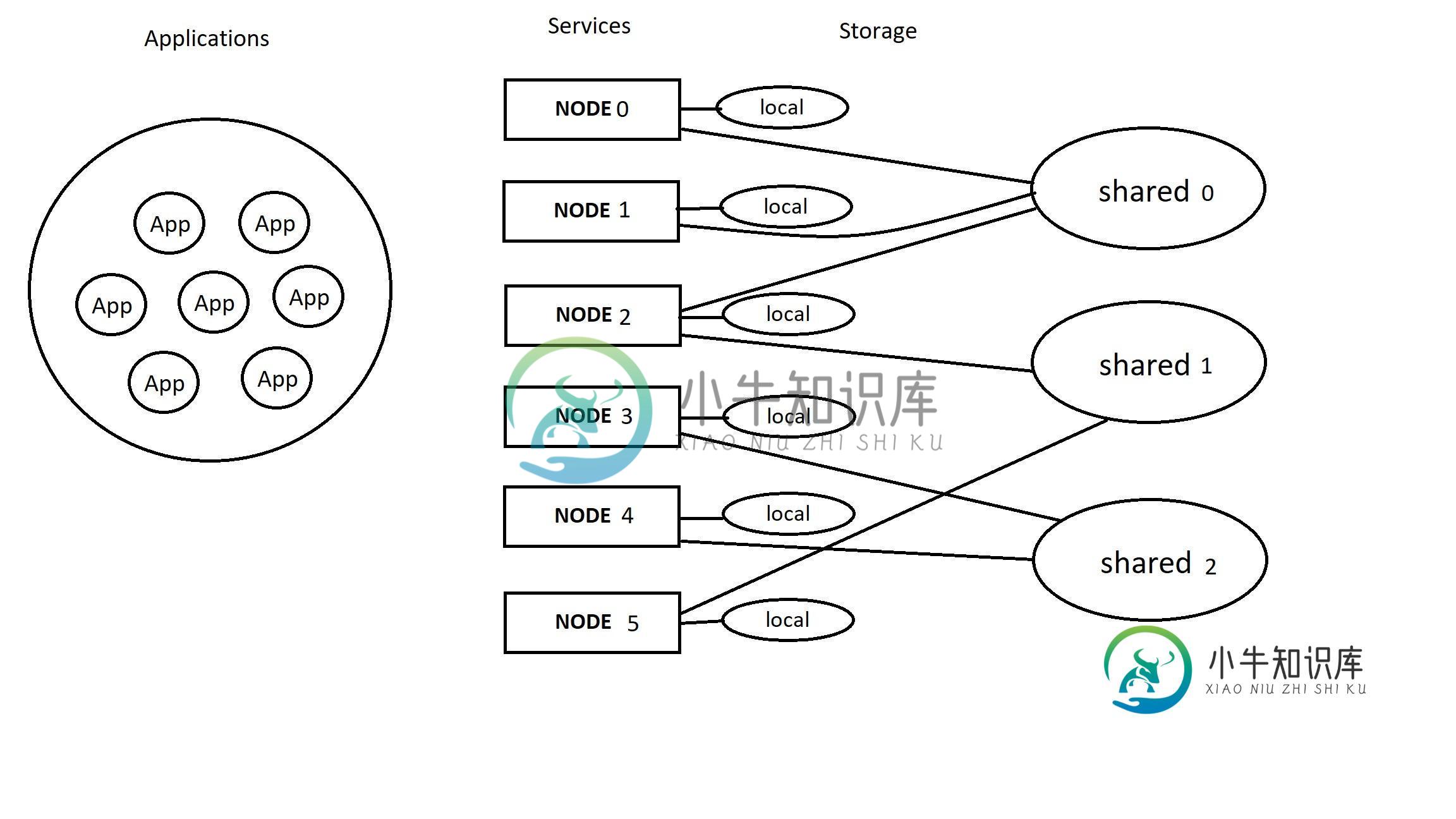 具有限制的再平衡算法
具有限制的再平衡算法请帮助解决以下问题。 给出了以下实体: < li >应用。应用程序驻留在存储上,它们通过服务节点产生流量。 < li >服务。服务分为几个节点。每个节点都可以访问本地或/和共享存储。 < li >存储。这是应用程序驻留的地方。它可以是本地的(仅连接到一个服务节点),也可以由几个节点共享。 规则: 每个应用程序都放置在某个特定的存储上。并且不能改变存储 只要新的服务节点可以访问应用程序的存储,应用程
-
库伯内特的Kafka流:重新部署后的长期再平衡
我们使用StatefulSet在Kubernetes上部署Scala Kafka Streams应用程序。实例具有单独的s,因此它们每个都复制完整的输入主题,以实现容错。它们本质上是只读服务,只读取一个状态主题并将其写入状态存储,客户请求通过REST从那里得到服务。这意味着,在任何给定时间,消费者组总是仅由单个Kafka Streams实例组成。 现在我们的问题是,当触发滚动重启时,每个实例大约需
-
消费者再平衡在Kafka是如何运作的?
当一个新的消费者/borker被添加或下降时,Kafka会触发一个再平衡操作。Kafka是在重新平衡封锁行动。Kafka的消费者是不是在一个再平衡操作正在进行的时候就被封锁了?
-
MongoDB分片集合未重新平衡
我们有一个相对简单的分片MongoDB设置:4个分片,每个分片是一个副本集,至少有3个成员。每个集合都由从大量文件加载的数据组成;每个文件都被赋予一个单调递增的ID,并且根据ID的哈希完成分片。 我们的大部分产品都在按预期工作。然而,我有一个集合似乎没有正确地将块分布到各个碎片上。在创建索引之前,集合加载了大约30GB的数据,并且进行了分片,但是据我所知,这并不重要。以下是该集合的统计数据: 这个
-
使用线性探测实现Hashtable时调整大小的权衡
我正在尝试使用线性探测实现一个哈希表。 在将(键、值)对插入哈希表之前,我想检查它是否已满一半。如果是,我需要将底层数组的大小增加一倍。 显然,有两种方法可以做到这一点: 一种是创建另一个大小加倍的数组,重新刷新旧数组中的所有条目,并将它们添加到新数组中。然后,将旧阵列重新绑定到新阵列。这种方法易于实现,但占用了大量空间。 另一种方法是将阵列加倍,并在适当的位置进行重新灰化。这种方式可能会导致更长
-
有哪些算法可以增量构建没有顺序约束的平衡二叉树?
我感兴趣的是获取一个元素列表,并将它们转换成一个平衡的二叉树,每个元素位于树的一片叶子上。此外,我想用一种一次只能看到一个元素的算法来构建树,而不是一次看到整个列表。最后,这个树没有排序约束——也就是说,它不是一个搜索树,所以节点可以按任何顺序排列。 我的问题是:有很多算法可以增量地构建二叉搜索树,但有哪些算法可以在没有任何排序约束的情况下构建平衡的二叉树?它们应该更有效,因为它们不必担心保持节点
-
 为什么在不平衡的二叉搜索树中添加O(n)?
为什么在不平衡的二叉搜索树中添加O(n)?这是BST Add中二进制搜索树中add的实现 我的问题是,即使二元搜索树是不平衡的,同样的策略是否也能用于分析add的运行时?你要做多少次切割。运行时不是仍然是O(logn),而不是O(n)吗?如果是这样的话,有人能证明为什么它会是O(n)吗?
-
 图中的平衡副词
图中的平衡副词 -
 多个Kafka制作人都在写同一个主题-如何平衡消费
多个Kafka制作人都在写同一个主题-如何平衡消费所以我有一个设计,其中我有多个生产者P1、P2、P3、P4... PN写入单个主题T1,它有32个分区。 另一方面,我在一个消费者组中最多有32个消费者。 我想负载平衡我的消息消耗 阅读文档时,我可以看到3个选项: 1。自己定义分区(缺点是我必须知道最后一条消息发送到哪里,或者为每个生产者定义分区范围P) 2。定义一个密钥并将分区决定权交给Kafka哈希算法(缺点-负载平衡将在运气好的情况下定义)
-
Spring Security性在负载平衡(AWS Beanstalk)环境中失败?
我正在处理一个在现有环境中工作得很好的现有代码。该应用程序有一个登录表单,将用户带到登陆页面后,他们登录。 应用程序在单节点环境中运行良好,例如用户登录时的日志跟踪: 1:[http-bio-8080-exec-1 DEBUG defaultreDirectStrategy-sendredirect-重定向到'/myapp/secure/landing.html' 2:[http-bio-8080
-
基于pod cpu使用的库伯内特斯负载平衡
我在pod中运行了高视频编码任务。这些任务在接收用户请求时运行,并且CPU密集型非常高。我想确保CPU使用率最低的pod应该在传入请求中接收。库伯内特斯有没有办法根据CPU使用率的百分比来平衡我的负载?