《均衡》专题
-
kubectl通过负载平衡器
kubernetes集群与api服务器(https://192.168.0.10:6443) 想法: 从我的笔记本电脑,我想运行kubectl,指向负载均衡器,在那里牧师代理将把我重定向到api服务器。 步骤: -我将kubeconfig(笔记本电脑上)文件中的服务器ip更改为LB的ip:https://192.168.0.10:6443是http://10.10.0.2:8080/ -我这样配置
-
Kubernetes GCP TCP负载平衡:如何将静态IP分配给Kubernetes服务?
我想为Kubernetes服务分配一个静态(即非临时)区域IP。目前,该服务属于“LoadBalancer”类型,GCP将其公开为一个区域TCP负载平衡器。默认情况下,转发规则的IP地址是临时的。是否有任何方法可以使用现有的静态ip或按名称分配自己的地址(如使用入口/HTTP负载平衡器可能)? 我还尝试使用该服务的节点端口使用自定义静态区域IP创建自己的转发规则。我只使用实际的节点端口成功地构建了
-
无法在带有Traefik Ingress Controller和AWS HTTPS负载平衡器的AWS上公开Keyclope服务器
我已经在我注册的域上使用Traefik Ingress Controller和AWS HTTPS负载平衡器成功公开了AWS上的两个微服务。 以下是源代码:https://github.com/skyglass-examples/user-management-keycloak 我可以通过https url轻松访问两个微服务: 因此,看来Traefik入口控制器和AWS HTTPS负载均衡器配置正确
-
K3S Kubernetes集群中Traefik入口控制器的AWS证书解析器,带有现有的AWS HTTPS负载平衡器
我有AWS K3S库伯内特斯集群 我有AWS负载均衡器 我已注册域名 我已经注册了AWS证书 我为我的域和AWS负载均衡器DNS名称创建了CNAME记录 我在AWS K3S库伯内特斯集群上安装了Traefik入口控制器 我将用户管理和whoami服务部署到AWS K3S库伯内特斯集群 我创建了带有用户管理和whoami路径的Traefik入口 问题是: 如何使用Ingress Traefik Co
-
如何为两个域的两个入口配置一个负载平衡器的nginx入口
我有一个k8s集群,如下所示 如上所述,我有一个外部ip A.B.C.D。 我还有两个域名domainA。com和域B。通用域名格式。 我的DNS设置如下: 对于domainA。通用域名格式: 在我用helm安装两个应用程序后 我得到了 我不知道为什么后端有两个IP。 www.domainA。com和www.domainB。com可能会路由到相同的ip(10.244.1.15:80),这是我不想要
-
http负载平衡器和运行状况检查
我发现了这个问题。。 您希望使用最少的步骤为在多个区域中运行的一组计算引擎实例配置网络负载平衡的自动修复。如果VM在3次尝试后无响应,则需要配置VM的重新创建,每次10秒。你应该怎么做? A、 使用引用现有实例组的后端配置创建HTTP负载平衡器。将运行状况检查设置为健康(HTTP) B、 使用引用现有实例组的后端配置创建HTTP负载平衡器。定义平衡模式并将最大RPS设置为10。 C.创建托管实例组
-
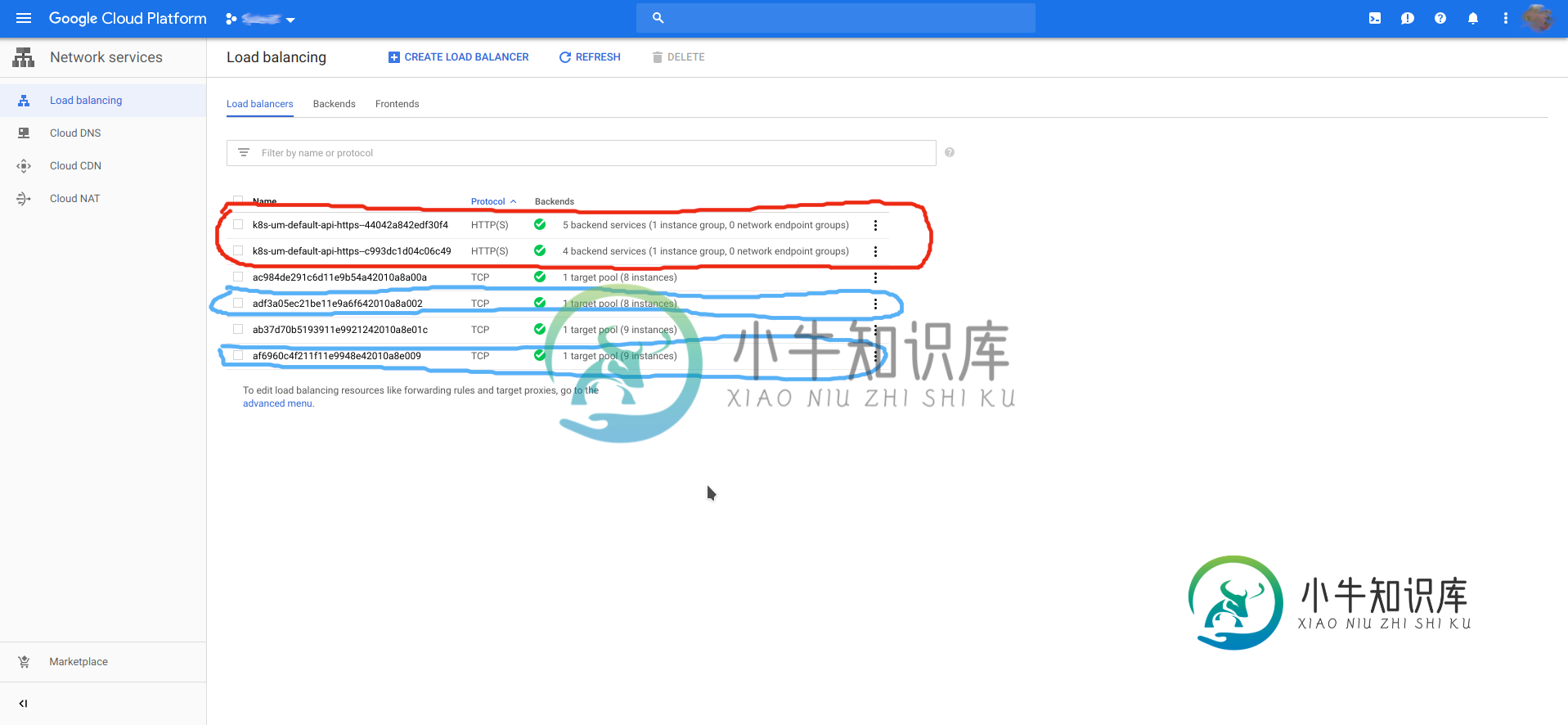 gke nginx ingress创建额外的负载平衡器
gke nginx ingress创建额外的负载平衡器有一个入口配置,比如 gke创建了nginx ingress负载平衡器,但也创建了另一个具有后端的负载平衡器,就像如果没有选择nginx,而是选择gcp作为ingress一样。 下面的屏幕截图以红色显示了两个意外的LB,蓝色显示了两个nginx ingress LB,分别用于我们的qa和prod env。 kubectl的输出获取服务 gcp gke服务视图中错误信息入口的屏幕截图 这是意料之中的
-
如何在GKE上设置服务负载平衡器请求超时
我在GKE上有一个LoadBalancer类型的服务,它指向运行nginx的GKE部署。我的nginx将所有超时设置为10分钟,但在收到响应之前必须等待处理的HTTP/HTTPS请求在30秒后因500个错误而被切断。我的设置: 显然,在LoadBalancer的某个地方有30秒的默认设置。 在浏览了大量文档之后,我在Google上只找到了一个步骤,其中概述了如何在GKE使用的类型为LoadBala
-
谷歌云负载平衡健康检查重置
Google容器引擎(kubernetes) 使用我的Web服务器应用程序(Torando/python)部署/pod kubernetes中Web服务器服务的入口-它在GCP中创建了负载均衡器 负载均衡器中的后端服务,后端是Web服务器 指向后端服务器的前端 将自定义域和子域引导到相关后端的主机和路径规则 防火墙规则设置为由入口创建 当我创建上述所有内容时,我使用正确的端口和所有内容创建了一个新
-
Kubernetes Google容器引擎HTTPS负载平衡器错误
有人知道谷歌的HTTPS负载平衡器是否正常工作吗?我当时正在建立一个NGINX入口服务,但我注意到谷歌负载平衡器是由Kubernetes自动设置的。我得到了两个外部IP,而不是一个。因此,我决定使用谷歌服务,而不是设置NGINX负载平衡器。我删除了我的容器集群,创建了一个全新的集群。我在端口80上启动了HTTP pod和HTTP服务。然后,我创建了入口服务和L7控制器吊舱。现在,我在查看负载平衡器
-
在Google云平台上使用HTTP负载平衡器和Kubernetes
我遵循了GKE教程,使用beta Inrit类型创建HTTP负载均衡器,并且在使用nginx映像时工作正常。我的问题是为什么Inrit是必要的。 我可以创建一个容器引擎集群,然后创建一个使用库伯内特斯创建的实例组作为服务后端的HTTP负载均衡器,并且一切似乎都运行良好。当仅在部分流程中使用库伯内特斯似乎运行良好时,为什么我要经历使用Inete的所有麻烦?
-
 Mac Kubernetes负载平衡器NoHttpResponseException的Docker
Mac Kubernetes负载平衡器NoHttpResponseException的Docker我正在尝试运行一个连接到部署pod的简单负载平衡服务器。 我安装了Docker for Mac edge版本。 问题是,当我尝试向公开的负载均衡器urlhttp://localhost:8081/api/v1/posts/health发出GET请求时,出现的错误是: org.apache.http.localhost:8081响应失败 做的时候: 我得到: 很明显,服务正在运行,但localhos
-
Kubernetes基础设施的选择性Kafka再平衡
一段时间后,Kubernetes controller将重新创建/重新启动失败/死亡的消费者实例,并再次执行新的重新平衡。 是否有任何方法来控制第一个重新平衡过程(当消费者死亡时)?例如,等待几秒钟而不重新平衡,直到失败的消费者返回,或者直到触发超时。如果消费者返回,是否继续基于旧的再平衡分配(即,没有新的再平衡)进行消费?
-
seekToEnd所有分区和生存Kafka消费者的自动再平衡
当使用者组a的一个Kafka使用者连接到Kafka代理时,我希望搜索到所有分区的末尾,即使在代理端存储了一个偏移量。如果更多的其他消费者为同一个消费者组连接,他们应该提取最新存储的偏移量。我正在做以下工作: 问题是,当我连接消费者组A的第一个消费者c1时,一切都按预期工作,如果我连接消费者组A的另一个消费者c2,该组将重新平衡,c1将消耗跳过的抵消。 有什么想法吗?
-
Kafka中主题分区再平衡的代价
在消费者之间重新平衡分区的代价有多大。我期待着每隔几秒钟就有一个新的消费者结束或加入同一个消费者群体。所以我只想知道一个再平衡操作的开销和延迟。 假设使用者C1具有分配给它的分区P1、P2、P3,并且它正在处理来自分区P1的消息M1。现在消费者C2加入了这个群体。C1和C2之间的分区是如何划分的。是否有可能拒绝C1的(可能需要一些时间将其消息提交给Kafka)对M1的提交,而M1将被视为一个新的消