《均衡》专题
-
库伯内特斯NodePort类型服务如何将负载平衡到pod
我仍然对Kubernetes节点端口服务有疑问。 NodePort:在静态端口(NodePort)上公开每个节点IP上的服务。将自动创建节点端口服务将路由到的ClusterIP服务。您可以从集群外部通过请求来联系NodePort服务:。 如果我有两个节点:nodeA和nodeB,并且如果我只在nodeA上部署应用程序,然后创建NodePort服务,那么我可以同时使用nodeA和nodeB IP访问
-
使用服务类型ClusterIP的负载平衡和负载平衡器的服务类型有什么区别?
当我将服务与ClusterIP类型和2个POD一起使用时,流量分布在2个POD上。 我找到了另一种服务类型LoadBalancer。这两种服务的区别是什么?LoadBalancer与ClusterIP有何不同? 谢谢
-
GCE负载平衡器后面的Kubernetes(GCE/GKE)上的Traefik
我已经按照用户指南在库伯内特斯上实现了Traefik。这给了我一个入口控制器,我能够在80和8080上创建一个入口和traefik-ingress-service监听。 我还设置了“gce”入口: 这样做的目的是创建一个GCE负载平衡器,它终止我的TLS,并将所有请求转发给NodePort类型的traefik入口服务。 GCE负载平衡器需要进行健康检查。默认为路径“/”。我以为traefik有个“
-
如何将nginx与Kubernetes(GKE)和googlehttps负载平衡器结合使用
我们利用入口创建HTTPS负载平衡器,直接转发到我们的(通常是nodejs)服务。然而,最近我们希望对NodeJ前面的流量进行更多的控制,而Google负载平衡器没有提供这种控制。 标准化的自定义错误页面 标准重写规则(例如将超文本传输协议重定向到https) 将pod readinessProbes与负载均衡器健康检查解耦(因此当没有健康的pod时,我们仍然可以提供自定义错误页面)。 我们在堆栈
-
全局第7层http(s)负载平衡器是否具有速率限制选项?
我将全局超文本传输协议负载均衡器用于在库伯内特斯集群上运行的后端服务。我没有找到任何关于如何限制一个IP在时间窗口中的请求数量的信息。有Cloud Armor,但也可以执行简单的IP、区域和基于标头的访问。您能否分享我如何对谷歌云上的全局超文本传输协议负载均衡器执行基于IP的速率限制,以提供对DoS攻击的防御。 编辑: Kubernetes集群上运行的后端服务是一个带有web界面的symfony服
-
GKE:身份感知代理>L7负载平衡器>自定义主机和路径规则>错误代码11
我正在使用GKE身份感知代理 路径和工作正常。和抛出。 如果我禁用IAP,一切正常。 环境: > 云提供商或硬件配置:GKE 正在使用入口设置HTTP负载平衡@https://cloud.google.com/kubernetes-engine/docs/tutorials/http-balancer 为GKE启用云IAP@https://cloud.google.com/iap/docs/ena
-
gke上的kubernetes/为什么强制使用负载平衡器?
通过GKE进入kubernetes,目前正在裸机上通过kubeadm进行尝试。 在以后的环境中,不需要任何特定的负载平衡器;通过使用nginx入口和入口,可以为www提供服务。 相反,在gke上,使用相同的nginx入口,或者使用gke提供的l7,最终总是得到一个计费负载平衡器。 这似乎不是最终需要的,原因是什么?
-
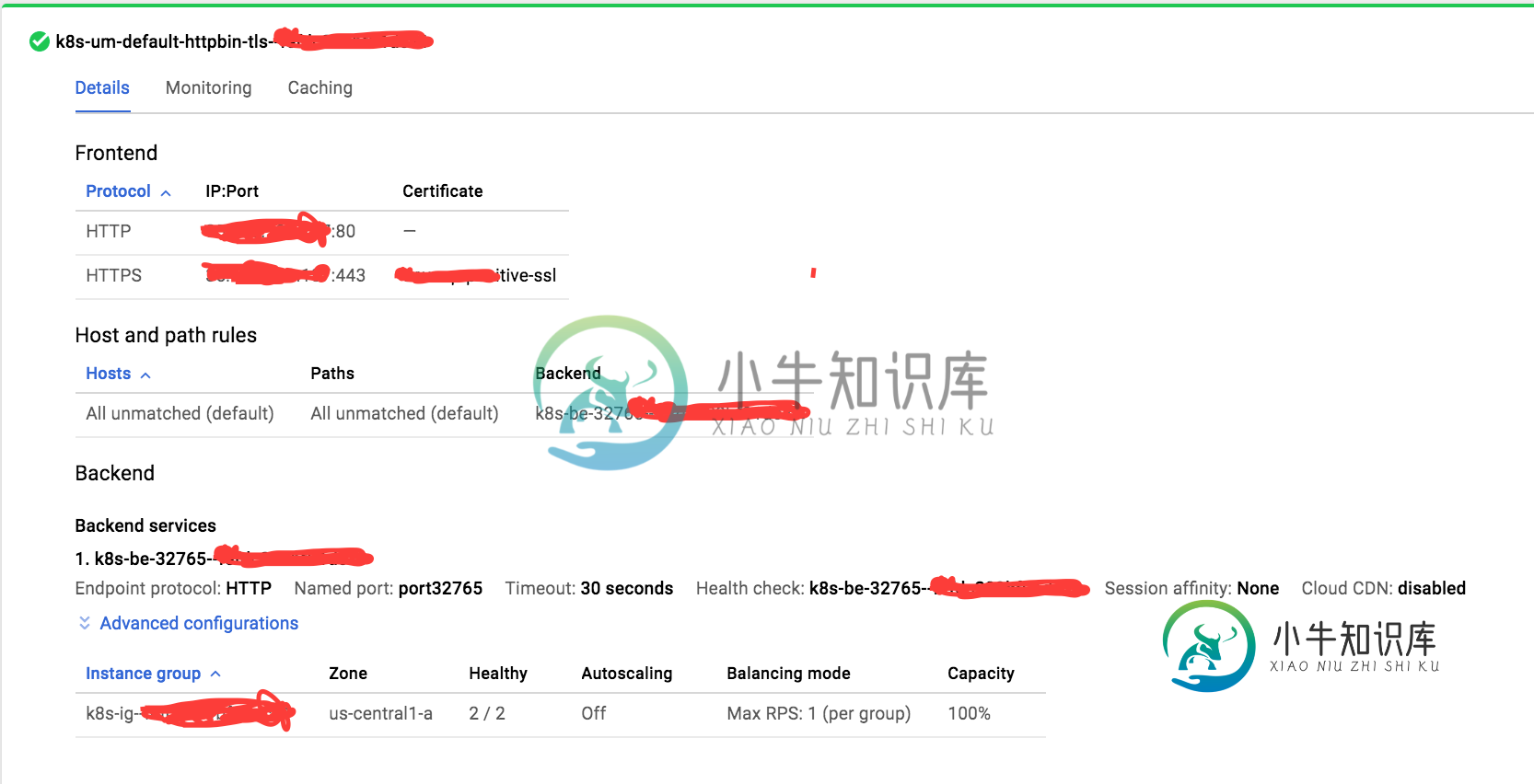 Google云负载平衡器使用Kubernetes入口强制HTTP而不是HTTPS
Google云负载平衡器使用Kubernetes入口强制HTTP而不是HTTPS我正在尝试部署一个Docker容器,它公开了一个简单的Docker服务器,它是Google容器引擎(库伯内特斯)中httpbin.org服务的克隆。 这是我正在使用的服务定义: 入口定义为: 在服务/入口仪表板中,我可以看到两个IP,一个直接绑定到服务(临时),另一个静态IP绑定到入口。直接在80号端口给他们两个打电话很有魅力。 完成后,我为静态IP创建了一个A记录,并确保GKE仪表板中的负载平衡
-
在Google云上使用HTTP负载平衡器和容器集群
我想在Google容器引擎上运行docker映像的集群前面放置一个HTTP负载平衡器,这样我就可以使用HTTPS,而无需应用程序支持它。 我使用以下命令创建了一个容器集群: 然后,我创建了一个复制控制器,在集群上运行一个映像,该映像基本上是nginx,其中复制了静态文件。 如果我为此创建一个网络负载平衡器,一切都会正常工作。我可以转到我的负载平衡器IP地址并查看网站。但是,如果创建HTTP负载平衡
-
学习。当使用具有小平衡数据集的GridSearchCV时,SVC返回完全不同的预测(模型)
当利用sk学。GridSearchCV通过skLearning。SVC(概率=True)当训练数据小而平衡(vs.小而不平衡)时,将返回完全不同的预测/模型。考虑这个例子: 在平衡数据上训练的模型返回所有新数据的概率,而使用不平衡数据训练的模型返回通常预期的结果。我知道本例中使用的训练数据很小,但差异只有1,我很好奇,到底是什么机制被改变,从而给出了完全不同的模型/概率。 更新#1在深入了解这一点
-
kubernetes负载平衡器服务
试图自学如何使用库伯内特斯,但有一些问题。 我的下一步是尝试使用LoadBalancer类型的服务来访问nginx。 我建立了一个新的集群并部署了nginx映像。 然后,我为LoadBalancer设置服务 设置完成后,我尝试使用LoadBalancer入口(我在描述LoadBalancer服务时发现)访问nginx。我收到一个此页面无法工作的错误。 不太确定我哪里出错了。 kubectl获得sv
-
负载平衡的意义什么?
本文向大家介绍负载平衡的意义什么?相关面试题,主要包含被问及负载平衡的意义什么?时的应答技巧和注意事项,需要的朋友参考一下 在计算中,负载平衡可以改善跨计算机,计算机集群,网络链接,中央处理单元或磁盘驱动器等多种计算资源的工作负载分布。负载平衡旨在优化资源使用,最大化吞吐量,最小化响应时间并避免任何单一资源的过载。使用多个组件进行负载平衡而不是单个组件可能会通过冗余来提高可靠性和可用性。负载平衡通
-
请选择一款你使用过的互联网金融的APP,来分析一下他的产品定位、目标用户、竞争优势。如果让你给这个产品出一套校园推广方案,你会怎么来做呢?可以从目标、行动计划、成本、效果衡量、人员安排等方向来说。
本文向大家介绍请选择一款你使用过的互联网金融的APP,来分析一下他的产品定位、目标用户、竞争优势。如果让你给这个产品出一套校园推广方案,你会怎么来做呢?可以从目标、行动计划、成本、效果衡量、人员安排等方向来说。相关面试题,主要包含被问及请选择一款你使用过的互联网金融的APP,来分析一下他的产品定位、目标用户、竞争优势。如果让你给这个产品出一套校园推广方案,你会怎么来做呢?可以从目标、行动计划、成本
-
AUC究竟在衡量模型什么能力?代码实现
本文向大家介绍AUC究竟在衡量模型什么能力?代码实现相关面试题,主要包含被问及AUC究竟在衡量模型什么能力?代码实现时的应答技巧和注意事项,需要的朋友参考一下 当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。 它不受类别不平衡
-
如何解决数据不平衡问题?
本文向大家介绍如何解决数据不平衡问题?相关面试题,主要包含被问及如何解决数据不平衡问题?时的应答技巧和注意事项,需要的朋友参考一下 这主要是由于数据分布不平衡造成的。解决方法如下: 采样,对小样本进行加噪声采样,对大样本进行下采样 进行特殊的加权,如在Adaboost中或者SVM 采用对不平衡数据集不敏感的算法 改变评价标准:用AUC|ROC来进行评价 考虑数据的先验分布 https://blog