《均衡》专题
-
AWS应用型负载均衡-重定向一小部分流量
是否有一种解决方案可以将一小部分流量重定向到AWS应用程序负载平衡器? 10%- 90%- (ALB或目标群体) 谢谢你的帮助
-
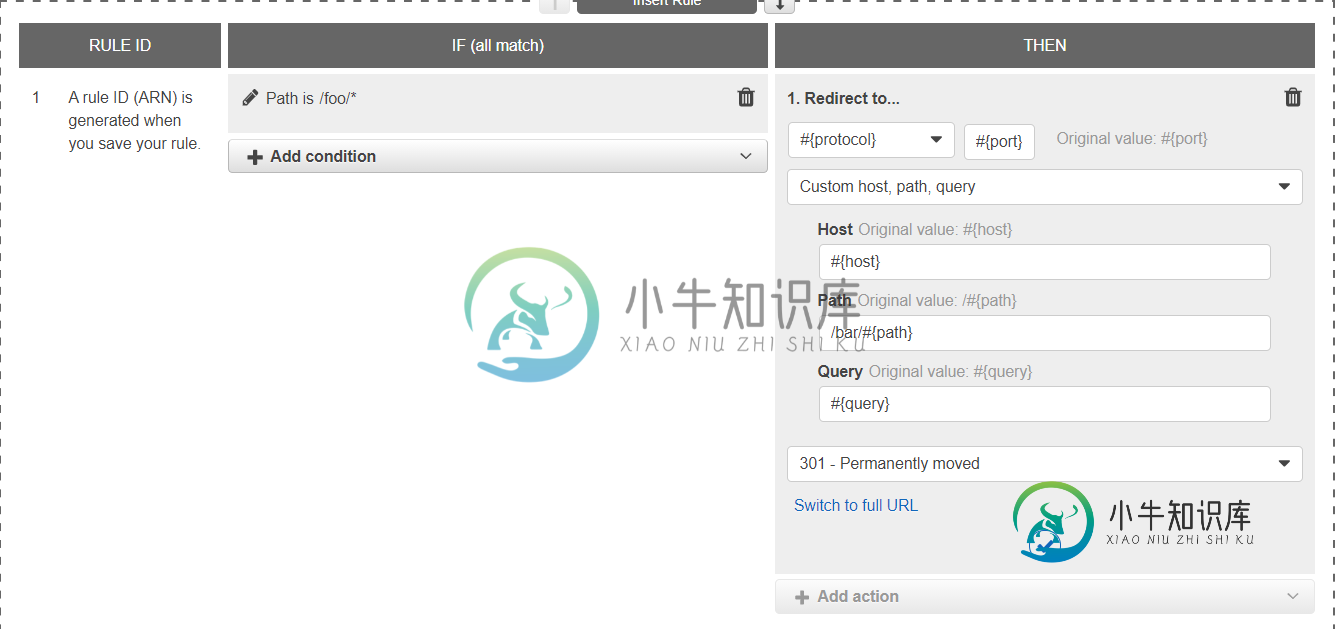 负载均衡器中的AWS重定向以使用POST和PUT
负载均衡器中的AWS重定向以使用POST和PUT我想做一些类似的事情:创建AWS应用程序负载平衡器规则,该规则修剪请求的前缀,而不使用额外的反向代理,如nginx、httpd 使用AWS负载平衡器,将流量从URL(例如)重定向到条形图(如下所示): 但是只有GET请求被正确路由,POST、PUT等被路由为GET,所以我收到一个错误,因为我的控制器没有这些GET方法。 有没有办法用AWS负载平衡器做到这一点? 我联系的问题是2016年的,所以我希
-
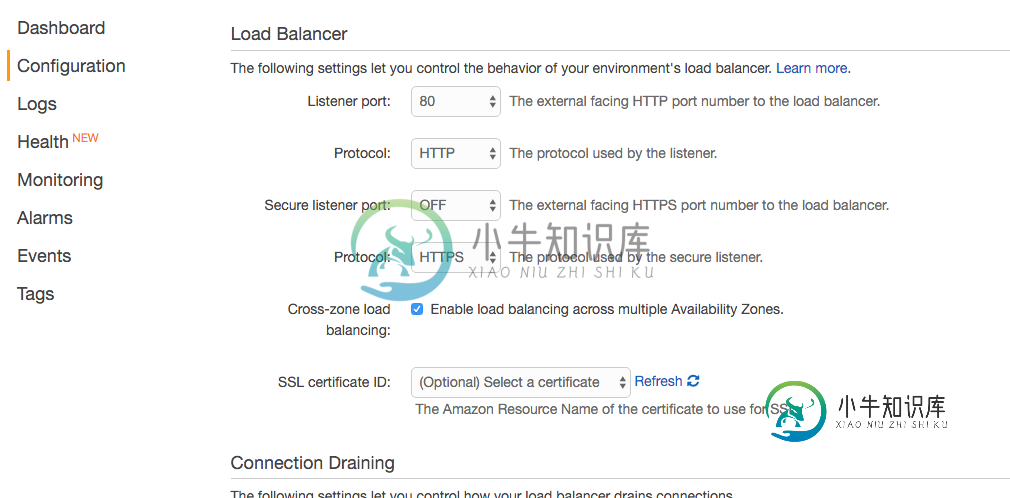 AWS弹性豆茎负载均衡器在哪里寻找认证?
AWS弹性豆茎负载均衡器在哪里寻找认证?我正在设置AWS弹性豆茎应用程序,我希望它的流量是HTTPS。 我创建了一个与beanstalk url匹配的DNS CNAME记录,并在AWS证书管理器中为该DNS名称创建并批准了一个证书。 现在,我转到Elastic Beanstalk Environment-->Configuration-->Network Tier/Load Balancer(下图),以便将“安全侦听器端口”从OFF设置
-
如何在aws经典负载均衡器上重定向HTTP->https?
我在beanstalk和配置的nginx实例上有一个经典的负载均衡器。我想重定向http到https请求。 我设置了负载均衡器侦听器重定向到端口80到它的实例。 我在.ebextensions/nginx_config.config中创建了一个文件,在其中设置重定向并筛选出HealthCheck。 请参阅下面的配置重写: 但似乎什么也没有发生,服务器仍然没有重定向到HTTPS。好像我的配置被忽略了
-
官方博客 - 超越轮循:为了延迟的负载均衡
原文: BEYOND ROUND ROBIN: LOAD BALANCING FOR LATENCY 作者: STEVE JENSON, 时间: 2016-3-16 这个帖子是与 Ruben Oanta 合作编写的。 负载均衡是任何大型软件部署的关键组成部分。但是有很多方法可以进行负载均衡。哪种方式是最好?我们如何评估不同的选择? 在现代软件生态系统中,负载均衡扮演了几个角色。首先,它是扩展性概念
-
如何使用MySQL计算移动平均线?
问题内容: 我需要做类似的事情: 除了,我还需要检索的前20个值的移动平均值。 首选标准SQL,但如有必要,我将使用MySQL扩展。 问题答案: 这只是我的头顶,而且我正要出门,所以未经测试。我也无法想象它会在任何种类的大数据集上表现出色。我确实确认它至少可以正常运行。:)
-
pandas DataFrame:用列的平均值替换nan值
问题内容: 我的pandas DataFrame主要填充了实数,但是其中也包含一些nan值。 如何nan用列的平均值替换s? 这个问题与这个问题非常相似:numpy array:用列的平均值替换nan值, 但是不幸的是,给出的解决方案不适用于pandas DataFrame。 问题答案: 你可以直接使用来nan直接填充: 的文档字符串说,应该是一个标量或快译通,但是,它似乎工作用为好。如果你想通过
-
Pandas在特定列上的滚动平均值
问题内容: 我有一个从CSV导入的像这样的数据框。 我想添加一个新的MA列,该列计算该列pop的滚动平均值。我尝试了以下 我得到一个错误 所以我想让我尝试一下,如果它不添加任何列就可以工作。我用了 我得到了输出 我似乎无法对栏弹出应用滚动平均。我究竟做错了什么? 问题答案: 要分配列,您可以根据以下内容创建滚动对象: ac2001发布的答案并不是执行此操作最有效的方法。他正在计算数据帧中每一列的滚
-
通过Javascript获取图像的平均颜色
问题内容: 不确定是否可行,但希望编写一个脚本来返回图像的平均值或值。我知道可以在AS中完成,但希望在JavaScript中完成。 问题答案: AFAIK,做到这一点的唯一方法是… 请注意,这仅适用于相同域中的图像以及支持HTML5 canvas的浏览器:
-
 Python绘制股票移动均线的实例
Python绘制股票移动均线的实例本文向大家介绍Python绘制股票移动均线的实例,包括了Python绘制股票移动均线的实例的使用技巧和注意事项,需要的朋友参考一下 1. 前沿 移动均线是股票最进本的指标,本文采用numpy.convolve计算股票的移动均线 2. numpy.convolve numpy.convolve(a, v, mode='full') Returns the discrete, linear convo
-
Python实现滑动平均(Moving Average)的例子
本文向大家介绍Python实现滑动平均(Moving Average)的例子,包括了Python实现滑动平均(Moving Average)的例子的使用技巧和注意事项,需要的朋友参考一下 Python中滑动平均算法(Moving Average)方案: 以上这篇Python实现滑动平均(Moving Average)的例子就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊
-
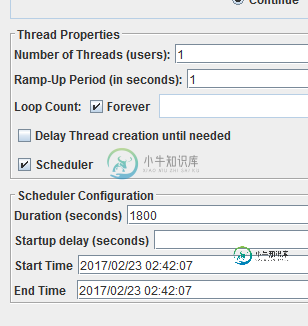 无法增加jmeter中的平均吞吐量
无法增加jmeter中的平均吞吐量我已经将线程数和上升时间设置为1/1,我正在从data.csv迭代我的1000条记录1800秒。现在给出数字,我已经设置了CTT,恒定时间吞吐量为每分钟2000,我预计平均吞吐量2000/60 = 33.3 /sec,但我得到18.7/秒,当我将吞吐量提高到4000/60时,我仍然得到18或19/秒。
-
R语言平均值,中位数和众数
主要内容:1.平均值,2.中位数,3.众数R中的统计分析通过使用许多内置函数来执行的。这些函数大部分是R基础包的一部分。这些函数将R向量与参数一起作为输入,并在执行计算后给出结果。 我们在本章中讨论的是如何求平均值,中位数和众数。下面将分别一个个演示和讲解 - 1.平均值 平均值是通过取数值的总和并除以数据序列中的值的数量来计算。函数用于在R中计算平均值。 语法 R中计算平均值的基本语法是 - 以下是使用的参数的描述 - x - 是输入向
-
返回每一行中每组的平均值
我正在使用SQL Server,数据库中有下表: 到目前为止我尝试了什么(错误的,因为它不计算每个组的平均值,而是计算所有列的总平均值):
-
用查找表在Pyspark中求平均向量
我试图在PySpark中使用https://nlp.stanford.edu/projects/GloVe/预先训练的手套模型实现一个简单的Doc2Vec算法。 我有两个RDD: