《内存淘汰》专题
-
分析火花执行器内存转储{几天后,纱容器内存耗尽}
我正在开发 spark 1.3,我的应用程序是一个 spark 流应用程序。我使用纱线作为资源经理。我的应用程序运行正常几天,然后 spark 作业定期丢失执行程序。当我查看node_manager日志时,我发现了一个异常: 我对这一例外的问题如下: > 我知道11G会运行执行程序的内存。但是我在spark-defaults.conf.中将10G设置为执行程序内存。那么11G是如何分配给执行程序的
-
解决淘宝cnpm 安装后cnpm不是内部或外部命令的问题
本文向大家介绍解决淘宝cnpm 安装后cnpm不是内部或外部命令的问题,包括了解决淘宝cnpm 安装后cnpm不是内部或外部命令的问题的使用技巧和注意事项,需要的朋友参考一下 今天通过网上查找的教程安装和配置了node环境,接着按照教程安装了cnpm。然而最后运用cnpm -v查看版本却出现了如下的错误: 不知道是自己在配置环境时出了什么问题,于是上网查了很多解决办法都不行,于是便自己寻找解决的办
-
Nginx作为缓存代理不缓存任何内容
问题内容: 我正在尝试缓存静态内容,这些内容基本上位于虚拟服务器配置中的以下路径内。由于某些原因,文件没有被缓存。我在缓存目录中看到了几个文件夹和文件,但总是像20mb一样高或低。例如,如果要缓存图像,则将至少占用500mb的空间。 这是nginx.conf缓存部分: 这是默认的虚拟服务器。 问题答案: 确保您的后端不返回标头。如果Nginx看到它,它将禁用缓存。 如果是这种情况,最好的选择是修复
-
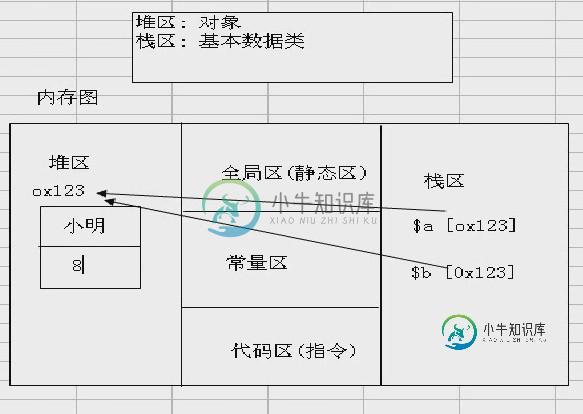 php对象在内存中的存在形式分析
php对象在内存中的存在形式分析本文向大家介绍php对象在内存中的存在形式分析,包括了php对象在内存中的存在形式分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了php对象在内存中的存在形式。分享给大家供大家参考。具体分析如下: (1)$p1对应内存地址,假设是0x123,($p1和地址存放在栈区,相当于我们查字典时的索引); (2)通过内存地址的索引,找到堆区。堆区里面存放着”小王“,”80“等数据 (3)$p2
-
MAX144 ADC读写的寄存器值和内存地址
我使用的是MAX144 ADC,数据表中没有提供有关读取ADC值的控制寄存器的信息。我使用STM32L452RE微控制器和SPI从ADC获取数据。ADC的数据表如下: https://datasheets.maximintegrated.com/en/ds/MAX144-MAX145.pdf 遇到相同问题的任何人请指导。 我的想法是为SPI RX创建一个2字节的缓冲区,并在其中存储值。但是我不知道
-
Spark:当我保存到HDFS时内存不足错误
当我将大数据保存到hdfs时,我正在体验OOME 我在Spark-Submit中使用这个: 当我增加框架时,现在的错误是:Java.lang.outofMemoryError:Java堆空间,所以我必须将驱动程序内存和执行程序内存增加到2G才能工作。如果累加Collection.value.length是500,000,我需要使用3G。这正常吗? 该文件只有146MB,包含200,000行(对于2
-
Spark SQL:“order by”提高了缓存内存占用率
我有两个场景,其中我有分区 中,读取的输入数据为6.2 GB,缓存的对象为15.1 GB。 案例1: 从 读取的输入数据为 6.2 GB,缓存的对象为 5.5 GB。 对此行为有任何解释或代码参考吗?
-
基元数组存储在 JVM 内存中的位置
JVM内存分为:1.方法区2.堆区3.堆栈4.PC寄存器5.本机堆栈 > 现在假设我有一个属性为“int[]dealCodes”(int基元数组)的类。根据内存管理,一旦处理代码初始化,内存中就会有连续内存分配(total_elements*4字节)。所以,如果数组大小为10,则JVM内存中有40字节的分配。 我的问题是,这40个字节将分配到哪个区域(堆还是堆栈)? 我对数组的理解是:它就像任何其
-
如何减少Spring内存占用
问题内容: 我想问你如何减少Spring框架的RAM占用量。 我创建了一个简单的helloworld应用来演示该问题。只有两个类和context.xml文件: -主要方法课 -用于模拟某些“工作”的类(无穷循环中的printig Hello) 仅包含以下内容: 测试类仅包含称为的方法,构造后会调用: 我准备了两种情况,在这两种情况下,方法仅包含一行。 在第一种情况下,主要方法是这样做的: App在
-
减少内存流失的方法
问题内容: 背景 我有一个Spring批处理程序,该程序读取一个文件(我正在使用的示例文件的大小约为4 GB),对该文件进行少量处理,然后将其写到Oracle数据库中。 我的程序使用1个线程读取文件,并使用12个工作线程进行处理和数据库推送。 我正在搅动很多年轻一代的记忆,这使我的程序运行得比我想象的要慢。 建立 JDK 1.6.18 春季批处理2.1.x 4核计算机,带16 GB内存 问题 使用
-
Java 8中的Java内存区域
问题内容: 我已经阅读了很多有关Java内存区域的信息,但看起来只是一团糟。主要是由于引入了新区域而不是java8。现在有问题: java8 +中包括哪些区域? 其中的方法和变量存储之前java8和java8 +? 除了类元数据信息外,是否存储任何其他内容? 存储器区域的结构是否取决于的实现? 谢谢您的回答。 问题答案: 内存区域的结构是否取决于JVM的实现? 绝对。PermGen或Metaspa
-
Java进程内存检查测试
问题内容: 我想看看和我的程序参数的影响,并检查多少内存我的过程中消耗。 我编写了一个简单的程序,但无法推断出结果。请帮助。 我跑了参数 。理想情况下,由于一个字符占用2个字节,因此在超过内存限制之前,它应容纳100M个字符。即使我们说,几乎没有空间用于 指针 和 length ,我也不知道,为什么它在 69926904 length 之后会 引发 错误 。 谢谢。 问题答案: 仔细阅读有关Gen
-
Android:持续的内存消耗/ dumpGfxInfo()
问题内容: 给定的:使用Android Studio向导创建的简单Activity, 内部没有任何自定义代码 ,会永久占用调用dumpGfxInfo()的内存。 Android Studio在Allocation Tracker中的构建至少揭示了 三个 相同的线程: 显然,dumpGfxInfo()通过为空字符串分配内存来消耗内存。编译中唯一相关的依赖项是 com.android.support:
-
Java本机内存使用情况
问题内容: 有什么工具可以知道我的Java应用程序已使用了多少个本机内存?我的应用程序内存不足:当前设置是:-Xmx900m 计算机,Windows 2003 Server 32位,RAM 4GB。 还在Windows上将boot.ini更改为/ 3GB,会有什么不同吗?如果设置为Xmx900m,则可以为此进程分配多少最大本机内存?是1100m吗? 问题答案: (就我而言,我使用的是Java 8)
-
JNI Attach / Detach线程内存管理
问题内容: 我有一个JNI回调: 当我像这样(空有用的代码)运行它时,会发生内存泄漏。如果我注释掉整个方法,则不会泄漏。连接/分离线程的正确方法是什么? 我的应用程序处理实时声音数据,因此负责数据处理的线程必须尽快完成,以便为下一批做好准备。因此,对于这些回调,我创建了新线程。每秒有数十个甚至数百个它们,它们将自己附加到JVM,调用一个回调函数来重绘图形,分离并消亡。这是做这些事情的正确方法吗?如