《性能测试》专题
-
使用弹性搜索的自动完成功能
我有一个弹性搜索索引与以下文档,我希望有一个自动完成功能在指定的字段: 制图:https://gist.github.com/anonymous/0609B1D110D91DCEB9A90FAA76D1D5D4 1)暗示者自动完成: https://www.elastic.co/guide/en/elasticsearch/reference/1.7/search-suggesters-compl
-
java正则表达式:性能和替代方案
最近,我不得不搜索许多字符串值,以查看哪一个匹配某个模式。在用户输入搜索项之前,字符串值的数量和模式本身都不清楚。问题是,每次我的应用程序运行以下行时,我都会注意到:
-
JDK7和JDK8之间的性能差异使用AtomicLong.IncrementAndGet
使用AtomicLong.IncrementAndGet方法测试JDK7和JDK8的性能差异,测试数据表明JDK7的性能优于JDK8。为什么JDK7的性能比JDK8好?是什么导致JDK8中的性能差? 系统环境: CPU:Intel(R)至强(R)CPU E5620@2.40 GHz 2.40 GHz(双处理器) 内存:8.00 GB set jvm_opt=-xms1024m-xmx1024m-x
-
使用磁盘存储缓存时的 EHcache 性能
我们在应用程序中使用ehcache。请看以下配置: 既然我们已经配置为eternal="true ",那么它会永远创建缓存吗?。磁盘空间有可能用完吗? 对磁盘存储的性能会有什么影响?。肯定比内存缓存慢,但是影响有多大。 如果磁盘中存储了更多缓存,是否会导致执行多个文件操作的IO问题? 请建议生产级应用的最佳实践。假设我们有一个3 GB的堆内存和25000个并发用户访问应用程序。但是,我们的应用程序
-
在docker容器中运行nginx的性能问题
我正在使用ApacheBench(ab)来测量两个nginx在Linux上的性能。它们有相同的配置文件。唯一的区别是nginx运行在docker容器中。 只是想知道为什么容器一有这么差的性能 nginx.conf:
-
Java性能:removeAll()上的搜索和删除速度
我在比较< code>removeAll(集合的速度时获得了一些乐趣 让我们假设我有两个不太小的集合,比如100000个连续的整数元素,而且它们大部分重叠,例如,5000个在左边,而不是右边。现在我只需打电话: 当然,这一切都取决于左集合和右集合的类型。如果正确的集合是一个哈希图,那么它会非常快,因为这就是查找的地方。但仔细一看,我发现了两个我无法解释的结果。我尝试了所有的测试,既有排序的<cod
-
@InjectMocks属性不能调用Mockito的方法ThenReturn吗?
本周我开始使用,但我遇到了一个问题,无法理解字段。 我有一个a级是这样的: 当我在测试中使用时,我这样调用它: 但我想设置字符串属性!我是这样试的: 但是,测试抛出一个异常: MissingMethodInvocationException:when()需要一个必须是“mock上的方法调用”的参数。例如:when(mock.getarticles()).ThenReturn(articles);
-
 将.NET framework转换为.NET核心,性能损失
将.NET framework转换为.NET核心,性能损失这是.NET framework 4.8---->.NET core 5.0 我有一个个人的国际象棋引擎,我正在工作,昨天我决定从.NET framework切换到.NET Core。 在这个过程中我没有更改1行代码,完全相同的代码。 当我这样做的时候,我注意到损失了几个百分点,在2%到5%之间(目前为止) 这足以看出perft每秒平均有500,000到200,000步的差异(如果你不知道这是什么
-
RDD中的分区数量和Spark中的性能
在 Pyspark 中,我可以从列表中创建一个 RDD 并决定有多少个分区: 我决定对RDD进行分区的分区数量如何影响性能?这如何取决于我的机器的核心数量?
-
两个表连接时的火花性能问题
我有两个大的Hive表,我想用spark.sql将它们连接起来。表格采用snappy格式,在Hive中存储为拼花文件。 我想加入它们并对某些列进行一些聚合,假设计算所有行和一列的平均值(例如 doubleColumn),同时使用两个条件进行过滤(假设在 col1,col2 上)。 注意:我在一台机器上进行测试安装(虽然功能非常强大)。我希望集群中的性能可能会有所不同。 我的第一个尝试是使用spar
-
如何估计Windows Azure表存储查询性能?
我想评估一下我的Windows Azure表存储查询是如何缩放的。为此,我建立了一个简单的测试环境,在这个环境中,我可以增加表中的数据量,并测量查询的执行时间。基于时间,我想定义一个成本函数,它可以用来评估未来查询的性能。 我评估了以下查询: 使用PartitionKey和RowKey查询 使用PartitionKey和属性进行查询 使用PartitionKey和两个行键进行查询 带有Partit
-
不同操作系统中的主动 MQ 性能
我已经在某些操作系统中测试了主动MQ JMS创建器。结果如下: > 这是正常的行为吗?因为在Linux,它要快得多?文档仅基于Linux。 而且,< code >慢速KahaDB访问是否会降低activeMQ的性能? 谢谢。
-
未能将“|”下的属性绑定到com.zaxxer.hikari.hikaridataSource Spring Boot
-
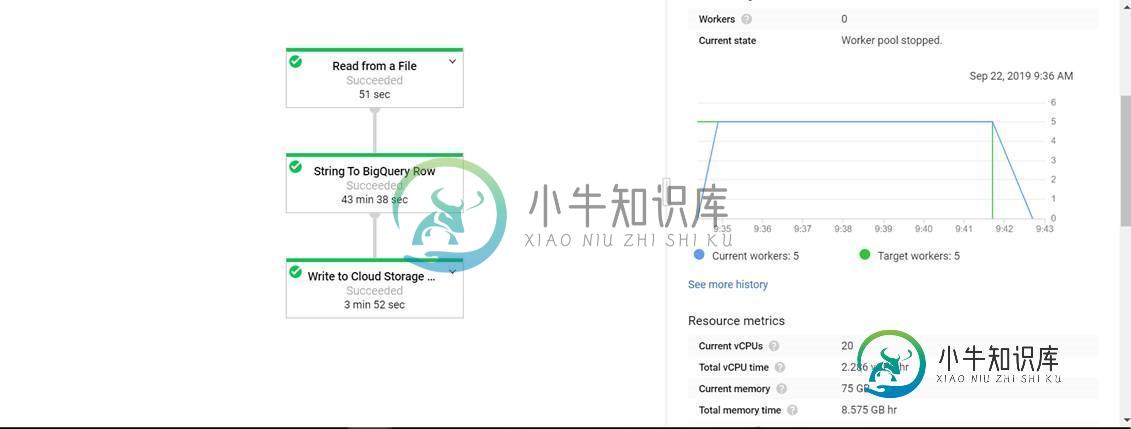 写入BigQuery时的云数据流性能问题
写入BigQuery时的云数据流性能问题我试图用Cloud Dataflow(Beam Python SDK)将它读写到BigQuery。 读写2000万条记录(约80 MBs)几乎需要30分钟。 查看dataflow DAG,我可以看到将每个CSV行转换为BQ行花费了大部分时间。
-
CMOV是如何提高CPU流水线性能的?
我知道当一个分支很容易预测时,最好使用IF语句,因为分支是完全自由的。我了解到,如果分支不容易预测,那么CMOV会更好。但是,我不太明白如何实现这一点? 问题域肯定还是一样的——我们不知道下一条要执行的指令的地址?因此,我不明白在整个管道中,当执行CMOV时,它是如何帮助指令获取器(过去有10个CPU周期)选择正确的路径并防止管道暂停的? 有人能帮我了解一下CMOV是如何改进分支的吗?