
写入BigQuery时的云数据流性能问题

我试图用Cloud Dataflow(Beam Python SDK)将它读写到BigQuery。
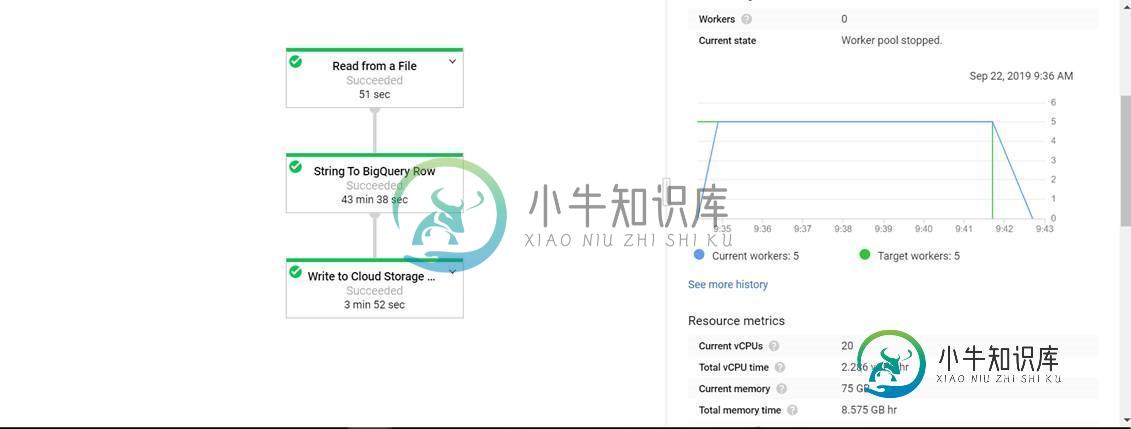
读写2000万条记录(约80 MBs)几乎需要30分钟。
查看dataflow DAG,我可以看到将每个CSV行转换为BQ行花费了大部分时间。
beam.Map(lambda s: data_ingestion.parse_record_string(s,data_ingestion.stg_schema_dict))
def parse_record_string(self, string_input,schema_dict):
for idx,(x,key) in enumerate(zip(imm_input,schema_dict)):
key = key.strip()
datatype = schema_dict[key].strip()
if key == 'HASH_ID' and datatype != 'STRING':
hash_id = hash(''.join(imm_input[1:idx]))
row_dict[key] = hash_id
else:
if x:
x = x.decode('utf-8').strip()
row_dict[key] = x
else:
row_dict[key] = None
#row_dict[key] = ''
return row_dict
共有1个答案

当您查看代码时,您的代码是计算密集型的。对于每一条20m的线路,执行以下操作:
- for循环(每行有多少元素?)
- 压缩和枚举
- 在循环上的每个元素上
- 执行2个条带(在字符串上循环以移除空格)
- 片上的联接(有2个循环)->此条件多长时间为真?
- 其他情况下的另一条
Python很棒,有很多助手,非常方便。但是,要注意这种简单性的陷阱,并正确评估算法的复杂性。
-
我想使用Cloud Dataflow,PubSub和Bigquery将tableRow写入PubSub消息,然后将它们写入Bigquery。我希望表名、项目id和数据集id是动态的。 我在internet上看到下面的代码,我不明白如何传递数据行参数。 先谢谢你,盖尔
-
使用“file_loads”技术通过Apache Beam数据流作业写入BigQuery时出错。流式插入(else块)工作正常,符合预期。file_load(如果块)失败,错误在代码后面给出。bucket中GCS上的临时文件是有效的JSON对象。 来自pub/sub的原始事件示例: 数据流作业出错:
-
我有一个简单的流程,目的是在一个BigQuery表中写两行。我使用动态目标,因为之后我将在多个表上写,在那个例子中是同一个表...问题是我的BigQuery表最后只有一行。在第二次插入时,我看到以下错误 "状态:{code: 6 消息:"已存在:作业sampleProject et3:b9912b9b05794aec8f4292b2ae493612_eeb0082ade6f4a58a14753d1
-
我想创建一个表,然后使用云函数写入bigquery,但是我不想复制表中的数据,所以我先删除表,然后在每次调用函数时创建表。 所以错误是当我首先删除表时,当它被重新创建以写入时,插入所有无法找到表我得到了这个错误:表abc.abc_names找不到
-
有一个在Dataflow中使用过DynamicDestination的人,他有一个简单的描述示例。在git(https://github.com/googleCloudPlatform/dataflowTemplates/blob/master/src/main/Java/com/google/cloud/teleport/templates/dlpTextToBigQueryStreaming.
-
我们有一个托管在Google Kubernetes引擎上的NodeJS API,我们想开始将事件记录到BigQuery中。 我可以看到三种不同的方法: 使用API中的节点BigQuery SDK将每个事件直接插入BigQuery(如此处“流式插入示例”下所述):https://cloud.google.com/bigquery/streaming-data-into-bigquery或此处:htt