《性能测试》专题
-
SQL存储过程中注释的性能含义
问题内容: 最近在我的日常工作中被指示,关于存储过程的任何注释都必须不存在于存储过程中,而必须使用扩展属性。 过去我们使用过类似的方法。 这样,只要有人在SSMS中打开该过程,他们就会看到该注释,而在过程中还存在其他注释,以记录我们的过程。现在我不知道与此有关的任何性能/内存问题。但是,我们有些人坚持要这样做。 我无法找到任何文档来证明或否认此类注释存在性能和/或内存问题。 所以我的问题是,有人知
-
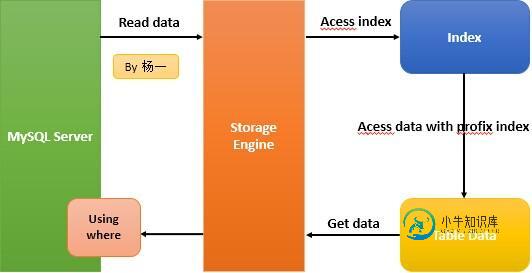 MySQL Index Condition Pushdown(ICP)性能优化方法实例
MySQL Index Condition Pushdown(ICP)性能优化方法实例本文向大家介绍MySQL Index Condition Pushdown(ICP)性能优化方法实例,包括了MySQL Index Condition Pushdown(ICP)性能优化方法实例的使用技巧和注意事项,需要的朋友参考一下 一 概念介绍 Index Condition Pushdown (ICP)是MySQL 5.6 版本中的新特性,是一种在存储引擎层使用索引过滤数据的一种优化方式。
-
查询性能WHERE子句包含IN(子查询)
问题内容: 当表开始增长时,我担心WHERE子句中IN的性能。有没有人对这种查询有更好的策略?子查询返回的记录数比TradeLine表中的记录数增长得慢得多。TradeLine表本身以每天10个的速度增长。 谢谢你。 编辑:我使用了将子查询从WHERE移到FROM的想法。我对有助于此新查询的所有答案投了赞成票。 问题答案: 子句中的子查询不依赖于外部查询中的任何内容。您可以安全地将其移到子句中;一
-
我们如何使用挂钩来增强性能?
Java Docs说Java Docs 公共类BufferedReader扩展阅读器 但是通过挂钩Filereader,我们使用Filereader的读取方法来读取一次读取一个字符的文件,所以如果我的文件包含2000个字符,Filereader首先会一次读取2000个字符,并将其转移到缓冲区,我们将使用bufferedreader从缓冲区读取,那么它如何提高性能?我们可以只用Filereader来
-
Java中性能优化的35种方法汇总
本文向大家介绍Java中性能优化的35种方法汇总,包括了Java中性能优化的35种方法汇总的使用技巧和注意事项,需要的朋友参考一下 前言 对程序员们来说,代码优化是一个很重要的课题。可能有些人觉得没用,一些细小的地方有什么好修改的,改与不改对于代码的运行效率有什么影响呢?这个问题我是这么考虑的,就像大海里面的鲸鱼一样,它吃一条小虾米有用吗?没用,但是,吃的小虾米一多之后,鲸鱼就被喂饱了。代码优化也
-
Azure应用程序服务的CPU性能如何?
我对将CPU密集型web应用部署到Azure应用程序服务实例很感兴趣。我找不到有关Azure应用程序服务的CPU使用率和/或限制的任何详细信息。我担心的是,如果不了解我的应用程序的CPU规格/限制,我就无法规划如何准确规划基于云的物理基础设施(使用Azure应用程序服务)。 我的应用程序将使用OpenCV计算机视觉库对数百/数千张高质量图像进行重图像处理、人脸检测和人脸识别。这自然是一个CPU密集
-
对Java Spring应用程序进行性能分析
问题内容: 我有一个Spring应用程序,我认为它存在一些瓶颈,因此我想用一个探查器运行它来衡量哪些功能需要花费多少时间。有什么建议我应该怎么做? 我正在运行STS,该项目是一个maven项目,并且正在运行Spring 3.0.1 问题答案: 我已经使用Spring AOP做到了。 有时,我需要有关在项目中执行某些方法(例如,控制器的方法)花费多少时间的信息。 在servlet xml中,我把 另
-
Java运行时性能与本机C / C ++代码?
问题内容: 与使用C ++或C相比,使用Java进行编程变得越来越舒适。我希望能感觉到使用JVM解释器引起的性能下降,而不是本地执行相同的“项目”。我意识到这里有一定程度的主观性。程序的质量将在很大程度上取决于良好的实施。我对一般意义上的以下方面感兴趣: 使用解释器时,必须有一些开销基线。有一些一般的经验法则要记住吗?10%15%?(我凭空想出了这些数字)我读过偶尔的博客,指出Java代码几乎与本
-
高性能网络的Netty替代品有哪些?
问题内容: 我正在选择一个网络库来实现不能花费任何微秒时间的客户端/服务器系统。它将实现自己的协议来发送和接收消息。我正在寻找一个好的NIO框架,该框架将使我能够轻松开发服务器和客户端,而不必过多担心低层选择器的细节。每个人都向我推荐Netty,但在向团队提出框架之前,我想尝试2或3个其他选择。我不太喜欢Netty的一件事是它如何使用自己的ByteBuf实现和引用计数来处理ByteBuffer。谁
-
检查java.lang.Double是否相等的高性能方法
问题内容: 检查双精度值是否相等的最有效方法是什么。 我明白那个 是慢的。 所以我在用 问题在于,测试耗时过多。没什么大不了的(最高1秒),但这让我感到好奇。 附加信息 硬编码,因为它是期望值,由 更新资料 java.lang.Double就是这样 因此可以认为这是最佳做法。 问题答案: JUnit有一种检查给定delta的“相等性” 的方法: 请参阅此API文档。 如评论中所述,JUnit实际上
-
优化大型表最近行查询的性能
问题内容: 我有一张大桌子: 所有请求中有90%与最近2-3天的订单有关,例如: 如何提高性能? 我知道分区,但是现有行呢?看来我需要每2-3天手动创建表格。 问题答案: 一个 部分,多列索引 上与伪状态将有助于(很多)。需要不时地重新创建以保持性能。 注意,如果表不是很大,则可以在很大程度上简化和使用普通的多列索引。 或者考虑在Postgres 12或更高版本(功能最终成熟的地方)中进行表分区。
-
为什么Nginx的性能要比Apache高很多
本文向大家介绍为什么Nginx的性能要比Apache高很多,包括了为什么Nginx的性能要比Apache高很多的使用技巧和注意事项,需要的朋友参考一下 为什么Nginx的性能要比Apache高很多? 这得益于Nginx使用了最新的epoll(Linux 2.6内核)和kqueue(freebsd)网络I/O模型,而Apache则使用的是传统的select模型。 目前Linux下能够承受高并发访问的
-
JavaScript知识点总结之如何提高性能
本文向大家介绍JavaScript知识点总结之如何提高性能,包括了JavaScript知识点总结之如何提高性能的使用技巧和注意事项,需要的朋友参考一下 JavaScript的性能问题不容小觑,这就需要我们开发人员在编写JavaScript程序时多注意一些细节,本文非常详细的介绍了一下JavaScript性能优化方面的知识点,绝对是干货。 先给大家巩固下javascript基本语法: javascr
-
Node.js与PHP、Python的字符处理性能对比
本文向大家介绍Node.js与PHP、Python的字符处理性能对比,包括了Node.js与PHP、Python的字符处理性能对比的使用技巧和注意事项,需要的朋友参考一下 测试用例分为用函数和类来进行一个大字符串的字符逐一读取。 测试代码 Node.js 函数 类 PHP 函数 类 Python 函数 类 其中 page.html 文件内容为一个长度为 的文本。 测试结果
-
如何实现Spring Kafka消费者的高性能
如何提高Kafka消费者的绩效?我有(并且需要)至少一次Kafka消费语义学 我有以下配置。processInDB()需要2分钟才能完成。因此,仅处理10条消息(全部在单个分区中)就需要20分钟(假设每条消息2分钟)。我可以在不同的线程中调用processInDB,但我可能会丢失消息!。如何在2到4分钟的时间窗口内处理所有10条消息? 下面是我的Kafka消费者代码。