《流处理》专题
-
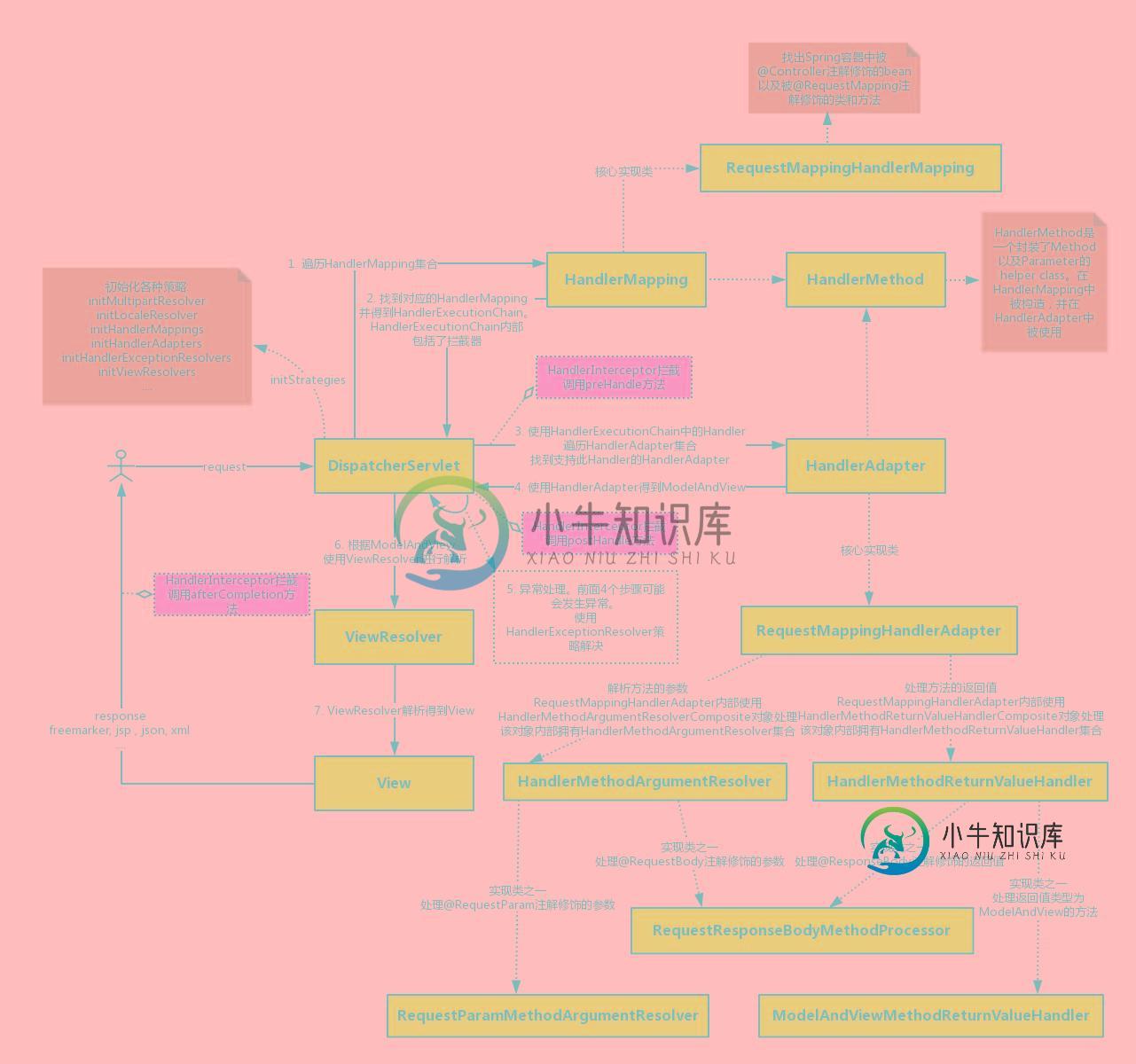 Spring MVC 处理一个请求的流程
Spring MVC 处理一个请求的流程本文向大家介绍Spring MVC 处理一个请求的流程,包括了Spring MVC 处理一个请求的流程的使用技巧和注意事项,需要的朋友参考一下 一个请求从客户端发出到达服务器,然后被处理的整个过程其实是非常复杂的。本博客主要介绍请求到达服务器被核心组件DispatcherServlet处理的整理流程(不包括Filter的处理流程)。 1. 处理流程分析 Servlet处理一个请求时会调用servi
-
在flink广播流中处理大数据
我正在使用一个Flink流式Java应用程序,输入源为Kafka。在我的应用程序中总共使用了4个流。一个是主数据流,另一个3个用于广播流。 我加入了使用任何一种类型的三个广播流。我已经作为流B广播,并且能够在广播过程函数上下文状态(即在processBroadcastElement())中接收。 我的问题是, > 是否可以在广播状态下存储大数据? 注意:根据我的理解,Flink广播状态在运行时保存
-
自定义处理器和反压,节流
NiFi 1.2.0 有一个自定义处理器从db读取数据并进一步传递数据。在最近的一次压力测试中,'success'关系队列被阻塞,后来的流也被阻塞,因为处理器转储了几个GBs的数十万个流文件。显然,反压力没有实施。我还读了一篇关于节流和反压的信息帖子。 在处理器中是否需要额外的编码(例如:要实现的某个接口)以使其能够“Hibernate/停止消耗数据”来进行反压,或者一旦处理器的“成功”关系被配置
-
处理flink数据流的输出数据
下面是我的流处理的伪代码。 上面的代码流程正在创建多个文件,我猜每个文件都有不同窗口的记录。例如,每个文件中的记录都有时间戳,范围在30-40秒之间,而窗口时间只有10秒。我预期的输出模式是将每个窗口数据写入单独的文件。对此的任何引用或输入都会有很大帮助。
-
流处理引擎的并行性行为
相反,如果我从web服务器收集数据,为什么不直接使用相同的节点进行事件处理呢?这些操作已经由负载均衡器分布在节点上,我在web服务器上使用负载均衡器。我可以在相同的JVM实例上创建执行器,并将事件从web服务器异步发送到执行器,而不涉及任何额外的IO请求。我还可以监视web服务器中的执行器,并确保执行器处理了事件(至少一次或恰好一次处理保证)。通过这种方式,管理我的应用程序将容易得多,而且由于不需
-
如何在功能上处理分割流
给定以下代码,如何将其简化为单个功能行? 这是我遇到的一个常见模式,我有一个流,我想过滤这个流,根据这个过滤器创建两个流,然后我可以对流a做一件事,对流B做另一件事。这是一个反模式,还是以某种方式得到支持?
-
带处理器的NiFi流文件移动
我一直在读关于NiFi的书,很少有疑问。考虑一个用例,我希望将数据从本地移动到HDFS中。我将使用getFile和putHDFS处理器。 > 我看到流文件内容是字节表示,字节转换是由Nifi完成的吗?(如果我的源文件是文本文件)? 如何将数据从内容回购转移到HDFS?
-
Kafka流处理器API上下文.转发
对于传入记录,我需要验证值,并且基于结果对象,我需要将错误转发到不同的主题,如果成功验证,则使用context.forward()转发相同的错误。可以使用本链接中提供的DSL来完成 现在,调用者再次需要检查并根据键来区分接收器主题。我使用processorAPI是因为我需要use头。 编辑: 当条件为false时,如何推送到不同的流。当前正在创建另一个谓词,该谓词收集链中不满足上述谓词的所有其他记
-
反应器中平行流量的处理
-
9.2 编写自己的流处理程序
在本指南中,我们将从头开始建立属于自己的项目,使用 Kafka Streams 编写一个流处理应用程序。如果你还没阅读过 quickstart (在Kafka流中运行一个流应用程序)章节,我们强烈建议你先去阅读一下。 建立一个Maven项目 使用以下命令来创建具有 Kafka Streams 项目架构的 Maven 原型: mvn archetype:generate \ -Darchety
-
一般处理流程 - 查看客户端
client list 列出所有连接 client kill 杀死某个连接, 例如CLIENT KILL 127.0.0.1:43501 client getname # 获取连接的名称 默认nil client setname "名称" 设置连接名称,便于调试
-
一般处理流程 - 获取慢查询
SLOWLOG GET 10 结果为查询ID、发生时间、运行时长和原命令 默认10毫秒,默认只保留最后的128条。单线程的模型下,一个请求占掉10毫秒是件大事情,注意设置和显示的单位为微秒,注意这个时间是不包含网络延迟的。 slowlog get 获取慢查询日志 slowlog len 获取慢查询日志条数 slowlog reset 清空慢查询
-
Web Player Streaming 网络播放器流处理
Desktop Web Player Streaming is critical for providing a great web gaming experience for the end user. The idea behind web games is that the user can view your content almost immediately and start pla
-
用于kafka主题再处理的火花流批处理间隔
当前设置:Spark流作业处理timeseries数据的Kafka主题。大约每秒就有不同传感器的新数据进来。另外,批处理间隔为1秒。通过,有状态数据被计算为一个新流。一旦这个有状态的数据穿过一个treshold,就会生成一个关于Kafka主题的事件。当该值后来降至treshhold以下时,再次触发该主题的事件。 问题:我该如何避免这种情况?最好不要切换框架。在我看来,我正在寻找一个真正的流式(一个
-
 冲刺云流Kafka流绑定器处理器应用程序卡住
冲刺云流Kafka流绑定器处理器应用程序卡住我有以下Spring Cloud Stream Kafka Streams Binder 3. x应用程序: 当我通过这个应用程序运行X消息时,通过使用和从联调将它们发布到,点1和点2的消息计数是相等的,正如我所期望的那样。 当我使用连接到Kafka代理的实时应用程序做同样的事情时,点1和点2的计数仍然显着不同: 消费者在< code >主题2上有很大的滞后,并且该滞后保持不变(在我停止发布消息后