《流处理》专题
-
用Java处理流
问题内容: 在C#中,在处理流对象时,几乎总是使用该模式。例如: 通过使用该块,我们确保代码块执行后立即在流上调用dispose。 我知道Java没有关键字的等效项,但是我的问题是,当使用Java中的对象时,是否需要做任何内务处理以确保将其处置?我在看这个代码示例,但我发现他们什么也不做。 我只是想知道Java在处理处置流方面的最佳实践是什么,或者它足以让垃圾收集器处理它。 问题答案: 通常,您必
-
处理流程流的正确方法
问题内容: 任何人都可以澄清一下下面的过程是否是正确的处理流程流的方法,而没有任何流缓冲区已满和阻塞问题 我正在从Java程序中调用外部程序,正在使用ProcessBuilder来构建流程,执行之后 我正在使用一种方法来处理流程 在我的方法中,我试图处理流程流 readStream方法用于读取我的流文本。 问题答案: 不,那不是正确的方法。 首先,在某些系统上,您的代码将永远停留在调用中,因为该过
-
Flink中的处理流
null 其中lambda1、2等是条件检查函数,例如 但不知什么原因对我不起作用,也许还有其他方法?正如我从文档(https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/side_output.html)中了解到的,OutputTag用于创建标记为tag的附加消息。还是我错了?
-
Java8流:处理空值
以下代码正在为空的属性抛出NPE。class Person有属性:string:name,Integer:age,Integer:salary此处可以为空。我想创建一个工资列表。 在这里,我必须在结果列表中保留空值。null不能替换为0。
-
DispatcherServlet 的处理流程
配置好DispatcherServlet以后,开始有请求会经过这个DispatcherServlet。此时,DispatcherServlet会依照以下的次序对请求进行处理: 首先,搜索应用的上下文对象WebApplicationContext并把它作为一个属性(attribute)绑定到该请求上,以便控制器和其他组件能够使用它。属性的键名默认为DispatcherServlet.WEB_APPL
-
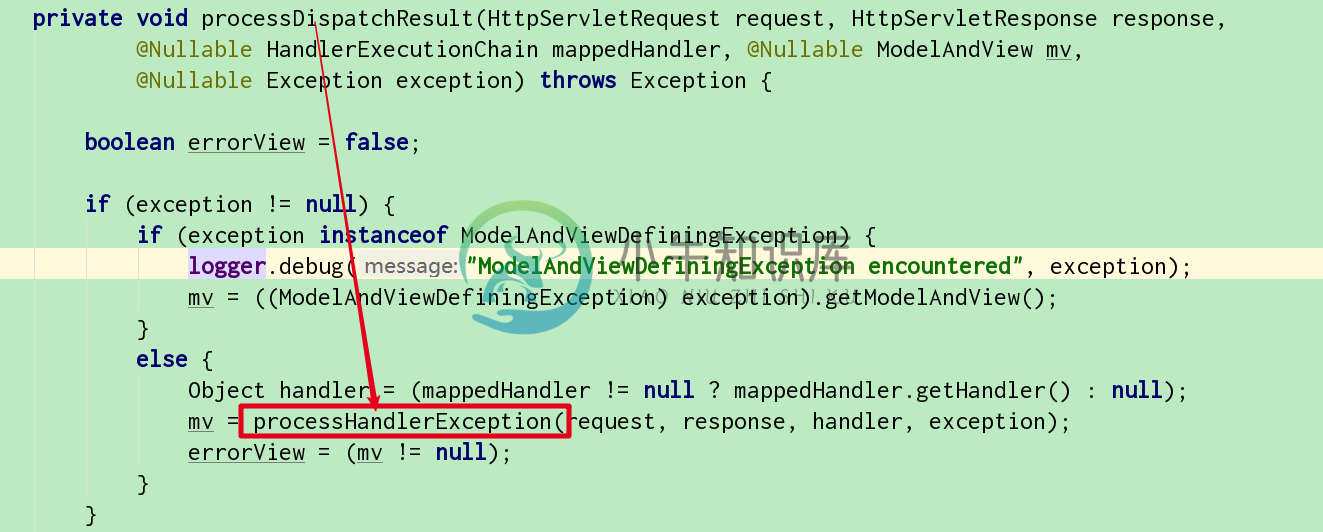 异常处理流程
异常处理流程主要内容:前记,1.processHandlerException方法前记 根据之前的文章方法中的方法返回处理的方法 1.processHandlerException方法 这个方法就是如果出现异常的话, 异常解析器进行处理异常。 先判断是否是注解下的方法, 如果是的话另外处理 -> 判断是否是注解下的方法 这里的主要有3个实现类 1.1注解下的异常 1.2注解下的方法 获取到装填码 获取到出错理由 然后渲染异常的页面 返回空的ModelAndView 1.3解析方
-
spark流式处理失败的批处理
我在spark streaming应用程序中看到一些失败的批处理,原因是与内存相关的问题,如 无法计算拆分,找不到块输入-0-1464774108087
-
流处理和消息处理的区别
流处理和传统消息处理的基本区别是什么?正如人们所说,kafka是流处理的好选择,但本质上,kafka是一个类似于ActivMQ、RabbitMQ等的消息传递框架。 为什么我们通常不说ActiveMQ也适合流处理呢。 消费者消费消息的速度是否决定了它是否是流?
-
Java 8流条件处理
问题内容: 我有兴趣将流分成两个或多个子流,并以不同的方式处理元素。例如,(大)文本文件可能包含A类型的行和B类型的行,在这种情况下,我想执行以下操作: 上一个是我试图抽象这种情况。实际上,我有一个非常大的文本文件,其中的每一行都针对正则表达式进行测试;如果该行通过,则将对其进行处理,而如果被拒绝,则我想更新一个计数器。对拒绝的字符串进行的进一步处理是为什么我不简单使用的原因。 是否有任何合理的方
-
处理连续的JSON流
问题内容: (现已失效)页面http://stream.twitter.com/1/statuses/sample.json用于返回连续无休止的JSON数据流。 我想在自己的网页中使用jQuery(或JavaScript,但最好是jQuery)对其进行处理,以便能够基于实时推文显示视觉效果。 据我所知,jQuery 函数仅在服务器发送完所有数据后才执行回调函数,但这实际上是连续的数据流。我如何“按
-
Storm 和流处理简介
一、Storm 1.1 简介 Storm 是一个开源的分布式实时计算框架,可以以简单、可靠的方式进行大数据流的处理。通常用于实时分析,在线机器学习、持续计算、分布式 RPC、ETL 等场景。Storm 具有以下特点: 支持水平横向扩展; 具有高容错性,通过 ACK 机制每个消息都不丢失; 处理速度非常快,每个节点每秒能处理超过一百万个 tuples ; 易于设置和操作,并可以与任何编程语言一起使用
-
第十一章:流处理
有效的复杂系统总是从简单的系统演化而来。 反之亦然:从零设计的复杂系统没一个能有效工作的。 ——约翰·加尔,Systemantics(1975) [TOC] 在第10章中,我们讨论了批处理技术,它读取一组文件作为输入,并生成一组新的文件作为输出。输出是衍生数据(derived data)的一种形式;也就是说,如果需要,可以通过再次运行批处理过程来重新创建数据集。我们看到了如何使用这个简单而强大
-
Sql命令处理流程
主要内容:一、Sql流程,二、源码分析,四、总结一、Sql流程 MySql是数据库,这次就分析一下一条SQL语句的流程,流程可能不会全面展开分析,当后面遇到具体的模块时,再由各个模块深入学习。如果使用过MySql的客户端(任意一种都可以),基本的形式就是在客户端写一条SQL语句,然后点击运行,正常的情况下,就会返回这条SQL执行后的结果。 可能学习Sql源码的人不少,但学习编译器知识的人就少多了。在SQL语句的执行过程中,其实SQL语句就是一门
-
使用if/检查流状态的Java流处理
给定:客户列表(带供应商和代理字段)、字符串代理、字符串供应商。 目标:检查是否有客户支持给定的代理和给定的供应商。 我有一个流需要过滤两次(两个值)。如果在第一次过滤后流是空的,我需要检查它并抛出异常。如果它不是空的,我需要通过第二个过滤器处理它(然后再次检查它是否不是空的)。 如果可能的话,我想避免将流收集到列表中(我不能使用任何匹配或计数方法,因为它们是终端) 目前我的代码看起来像: 在这个
-
使用AWS处理DynamoDB流JavaDynamoDB流Kinesis适配器
我试图捕获DynamoDB表更改使用DynamoDB流和AWS提供JavaDynamoDB流Kinesis适配器。我正在Scala应用程序中使用AWSJavaSDK。 我从遵循AWS指南和通过AWS发布的代码示例开始。然而,我在让亚马逊自己发布的代码在我的环境中工作方面遇到了问题。我的问题在于对象。 在示例代码中,使用DynamoDB提供的流ARN配置了。 我在Scala应用程序中遵循了类似的模式