《流处理》专题
-
Kafka流处理器api允许多集群拓扑?
使用kafka processor API(不是DSL)读取源主题并写入目标主题,对于单个kafka集群设置(也就是说,如果源主题和目标主题都驻留在同一集群上)来说工作很好,但是当源主题和目标主题驻留在不同的kafka集群上时,我将获得目标处理器上下文的NullPointerException 我们如何使用kafka streams处理器API从一个集群中的一个主题写到另一个集群中的另一个主题?
-
流处理器(低级API)源处理器如何从主题中获取数据?
我是Kafka流处理器的新手,接触到了“拓扑”的关键概念。 我创建了源处理器,它从如下“源主题”中读取: 上面的代码片段将创建(如果我的理解正确的话)一个名为“source”的源流处理器,并将侦听Kafka主题“source topic”。 我没有为这个“SOURCE”流处理器编写任何代码,它是如何从kafka主题中获取消息的?它是由kafka stream API本身照顾的“特殊”类型的流处理器
-
Spark Structured Streaming——有状态流处理中带有窗口操作的事件处理
我是Spark结构化流处理的新手,目前正在处理一个用例,其中结构化流应用程序将从Azure IoT中心-事件中心(例如每20秒)获取事件。 任务是使用这些事件并实时处理。为此,我在下面用Spark Java编写了Spark结构化流媒体程序。 以下是要点 目前我已经应用了10分钟间隔和5分钟滑动窗口的窗口操作。 水印被应用在以10分钟间隔的eventDate参数上。 目前,我没有执行任何其他操作,只
-
Kafka流关闭挂钩和意外异常处理在同一流应用程序中
我的任务是拆除一个开发环境,并从废品中重新设置它,以验证我们的CI-CD流程;唯一的问题是我搞砸了创建一个主题,因此Kafka Streams应用程序退出并出现错误。 我仔细研究了一下,发现了问题并纠正了它,但当我深入研究时,我遇到了另一个奇怪的小问题。 我实现了一个意外的异常处理器,如下所示: 问题是,如果应用程序抛出一个异常,因为一个主题错误时,KafkaStreams::c失去的是调用应用程
-
Kafka流:是否可以使用与流处理不同的时间戳进行删除?
在Kafka流2.0。 我的用例:能够从重新处理应用程序的历史开始(部分)用事件创建的时间(用户从原始数据定义并通过TimestampExtractor设置)重新处理数据,与长期运行的不间断应用程序一起运行,将数据发送到输出主题(两个应用程序将读取并发送到相同的输出主题,用于构建状态)。 存储是根据这些主题构建的,包括按会话设置窗口。想象一下,我想为这些主题保留一个月的时间(对于乱序事件和消费)—
-
xarg与python多处理子流程的性能对比
我对xargs的性能可伸缩性有一个问题。目前,我有一个用python编写的批处理程序,带有多处理和子进程。每个进程产生一个独立的子进程。popen()执行外部命令。最近我意识到整个过程可以用xargs重做。然而,我想知道使用xargs处理10k文件是否是一个好主意,因为我以前从未用命令行工具做过如此大规模的事情。考虑到我对小数据集的测试,如果我所做的只是批量运行一组命令,这其实不是一个坏主意,因为
-
Kafka流处理器上下文中的周期性NPE
使用kafka-stream0.10.0.0,我在转发消息时定期在StreamTask中看到空指针异常。它在10%到50%的调用之间变化。NPE发生在这个方法中: 似乎在某些情况下,thisNode字段为空。知道是什么导致了这种情况吗?堆栈跟踪在下面。
-
Camel:如何使用StreamList从SQL组件流式处理
我正在尝试使用Camels SQL组件,使用outputType=StreamList从数据库中传输数据。我从一个带有ConsumerTemplate的Java类中获取ResultIterator: 当尝试迭代ResultsetIterator时,我得到以下错误: 组织。h2。jdbc。JdbcSQLException:对象已关闭[90007-197] 经检查,我发现连接已关闭。连接={Hikar
-
是否可以在apache flink CEP中处理多个流?
我的问题是,如果我们有两个原始事件流,即烟雾和温度,并且我们想通过将运算符应用于原始流来找出复杂事件(即火灾)是否发生,我们可以在Flink中做到这一点吗? 我问这个问题是因为到目前为止,我所看到的Flink CEP的所有示例都只包括一个输入流。如果我错了,请纠正我。
-
Netty ByteBuf处理,流水线中的解码器结构
我的服务器将响应发送到客户端或将消息转发到另一个客户端取决于消息内容。我需要使用8字节的消息:大括号之间的6个加密字节,例如: 其中0x3c表示<符号作为开始帧标记,0x3e表示>符号作为结束帧标记。 所以我得到4字节的有效负载(0x02,0x03,0x04,0x05)。 我已经编写了一个FrameDecoder,但现在我不能决定是否删除大括号字节: 我想写干净的代码,大括号只是框架标记,所以它们
-
在 Spark 流式处理中,如何检测空批次?
在 Spark 流式处理中,如何检测空批次? 让我们以有状态流式处理字数为例:https://github.com/apache/spark/blob/master/examples/src/main/java/org/apache/spark/examples/streaming/JavaStatefulNetworkWordCount.java。是否可以仅在将新单词添加到流中时才打印字数RDD
-
Kafka流:在窗口化时重新处理旧数据
具有Kafka Streams应用,其通过例如1天的流连接来执行开窗(使用原始事件时间,而不是挂钟时间)。 如果启动此拓扑,并从头开始重新处理数据(如在 lambda 样式的体系结构中),此窗口是否会将旧数据保留在那里?da 例如:如果今天是2022-01-09,而我收到来自2021-03-01的数据,那么这个旧数据会进入表格,还是会从一开始就被拒绝? 在这种情况下,可以采取什么策略来重新处理这些
-
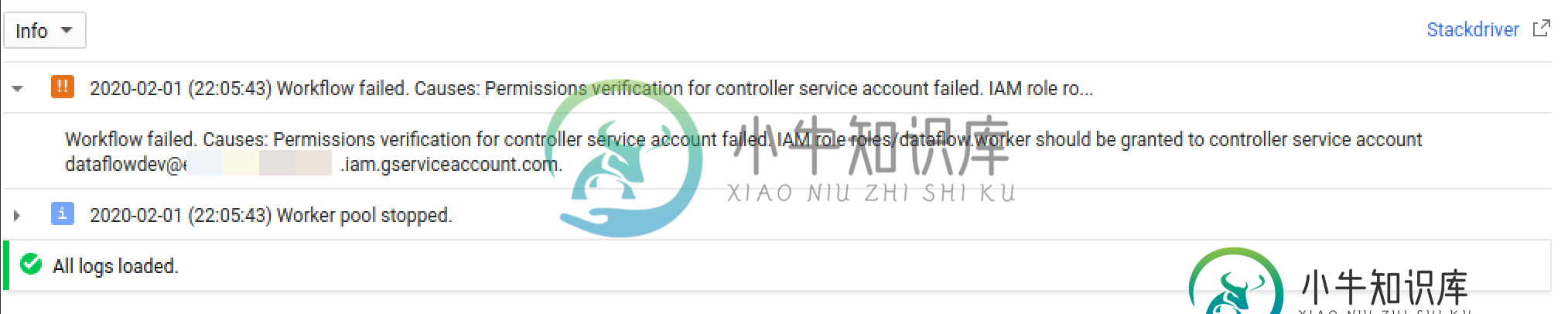 服务帐户执行批处理数据流作业
服务帐户执行批处理数据流作业我需要使用服务帐户执行数据流作业,下面是同一平台中提供的一个非常简单和基本的wordcount示例。 根据这一点,GCP要求服务号具有数据流工作者的权限,以便执行我的作业。即使我已经设置了所需的权限,错误仍然出现时,堰部分会出现: 有人能解释这种奇怪的行为吗?太感谢了
-
Kafka流处理过程中的外部系统查询
null
-
Azure流处理通过数组向上插入到DocumentDB
我使用Azure Stream Analytics将Json复制到DocumentDB,并使用upsert用最新数据覆盖文档。这对于我的基础数据来说很好,但我希望能够附加列表数据,因为不幸的是,我一次只能发送一个列表项。 在下面的示例中,文档在id上匹配,并且所有项目都更新了,但我希望“myList”数组随着来自每个文档的“myList”数据(具有相同的id)不断增长。这可能吗?是否有其他方法使用