《流处理》专题
-
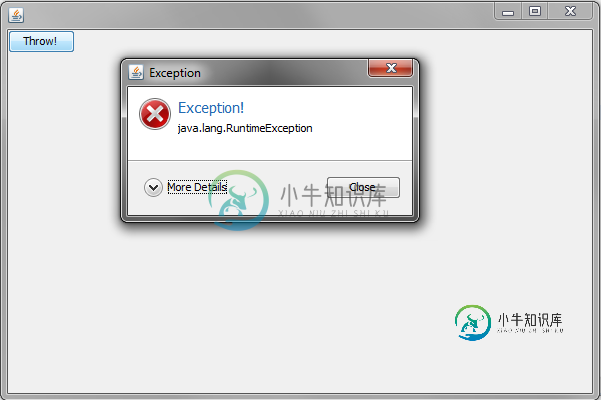 在GUI中处理未处理的异常
在GUI中处理未处理的异常我主要是为技术精明的人编写一个小工具,例如程序员、工程师等,因为这些工具通常是快速的,随着时间的推移,我知道会有未处理的异常,用户不会介意。我希望用户能够向我发送回溯,这样我就可以检查发生了什么,并可能改进应用程序。 我通常做wxPython编程,但我最近做了一些Java。我已经将
-
Spark Streaming中处理的批处理与RDD
我在中看到了几个答案(例如这里),因此建议批次中的记录将成为单个RDD。我对此表示怀疑,因为假设batchInterval为1分钟,那么单个RDD将包含最后一分钟的所有数据? 注意:我不是直接将批次与RDD进行比较,而是将Spark内部处理的批次进行比较。
-
Android Dagger2组件处理器无法处理
我正在尝试使用制作多模块项目。您可以通过链接查看我的代码。在分支是工作解决方案,其中所有匕首类都在模块中。 现在,我正在尝试为DI根创建单独的< code>app模块。您可以在< code>develop分支中看到最新的尝试。它不起作用。我想在< code>app模块中创建我的根< code > application component 组件,并从其他模块添加< code > presentat
-
Java8中流的笛卡尔积作为流(仅使用流)
例如,对于{A,B}和{X,Y}这两个流,我希望它生成值流{AX,AY,BX,BY}(简单的串联用于聚合字符串)。到目前为止,我已经想出了这段代码: 这是我想要的用例: 预期结果:。 溪流消耗在哪里?按平面地图?很容易修好吗?
-
Spring Cloud数据流自定义Scala处理器无法从Starter Apps(SCDF 2.5.1)发送/接收数据
我一直在为Spring云数据流在Scala中创建一个简单的自定义处理器,并且在向starter应用程序发送/接收数据时遇到了问题。我无法看到任何消息在流中传播。流的定义是时间触发器。时间单位=秒|传递日志|日志其中传递日志是我的自定义处理器。 我使用的是Spring Cloud Data Flow 2.5.1和Spring Boot 2.2.6。 这是处理器使用的代码-我使用的是功能模型。 应用y
-
为什么在默认Spring云流配置中更改Spring集成消息方法处理行为
我有一个已经使用Spring集成(5.1.6最新)的应用程序。配置如下流: 和 一切正常。 如果我试图在初始化的上下文中找到bean,我会看到下一个转换器: 之后,我添加到我的pom依赖项Spring Cloud Stream 2.1.2依赖项和Kinesis Binder 1.2.0。默认情况下配置绑定。 应用程序启动,但当我试图处理现有流时,它失败了,原因如下: EL1004E:方法调用:在p
-
连续触发器不适用于具有有效接收器的 Spark 结构化流式处理
我正在尝试将连续触发器与 Spark 结构化流式处理查询结合使用。我得到的错误是,火花消费者在处理数据时找不到适当的偏移量。如果没有此触发器,查询将正常运行(如预期)。 我的工作: 从Kafka主题读取数据: 将数据写入Kafka主题: 所以我基本上没有做什么特别的事情——只是将输入数据传输到输出主题,而没有任何转换或无效操作。 我得到了什么: 在executor日志中,我看到很多这样的消息: 尽
-
如何使一个以kstream(Kafka stream)为基础的Spring云流处理器函数及时工作?
所以我有一个场景,我的云流处理器函数从一个Kafka topic-1读取消息,并将消息生成到另一个Kafka Topic-2。但是这个过程必须及时运行,比如函数应该等待5分钟,然后它应该启动(消耗n生产)1分钟,然后1分钟后再次等待5分钟。有人能帮我做这件事吗?
-
在GCP数据流使用apache beam完成作业后,是否有任何方法进行处理?
GCP数据流状态完成/完成后,是否有任何方式进行后处理。我有一个过程,数据流从GCP存储中批量读取一个文件,并执行一些外部api调用以进行转换,然后写回另一个文件。在所有批次转换/处理后,我需要做一些额外的处理。有办法吗?我正在使用ApacheBeam和模板来运行GCPDatatflow。
-
从一个长的流创建流
我想根据的内容将单个拆分为的。生成的应该包含原始流数据的一部分。 我的实际应用程序更复杂(它是对时间间隔列表中的日志行进行分组),但我的问题是如何处理流,因此这里我询问一个简化的示例。 我希望能够拆分
-
Spring Cloud数据流:版本化流
我正在用Spring Cloud数据流实现一个流管道。 我的问题是,我手动配置了服务器中的管道(例如),如果我重置该服务器,它将丢失(以Amazon EC2实例为例,该实例可以硬重置)。
-
基于数据流的流类型?
长话短说:java.io包中有多少种基于数据流的流?它们是字节流和字符流还是二进制流和字符流? 完整问题: https://youtu.be/v1_ATyL4CNQ?t=20m5s昨天看了本教程后跳到20:05,我的印象是基于数据流有两种类型的流:BinaryStreams和CharacterStreams。今天,在了解了更多关于这个主题的知识之后,我的新发现似乎与旧发现相矛盾。 互联网上的大多数
-
流量中的流数据计算
-
汇流控制中心不截流
我已经将Postgres连接器映射到Kafka Connect中(通过Compose中的),并且在创建新的源连接器时可以在CCC中看到它。 当我创建源连接器时,我可以看到日志消息,指示此连接器的主题已创建。我在CCC的Connect专区也看到了这个话题。我还可以看到Connect能够通过该连接器对Postgres进行身份验证。 当我对连接器中指定的表进行更改时,我看到Kafka(我有一个3的集群)
-
第7章 IO流 - 序列化流
1. 什么是java序列化,如何实现java序列化? 我们有时候将一个java对象变成字节流的形式传出去或者从一个字节流中恢复成一个java对象,例如,要将java对象存储到硬盘或者传送给网络上的其他计算机,这个过程我们可以自己写代码去把一个java对象变成某个格式的字节流再传输,但是,JRE本身就提供了这种支持,我们可以调用OutputStream的writeObject()方法来做,如果要让j