《流处理》专题
-
如何处理http响应异常并继续流,直到在Spring集成中聚合
我在我的项目中使用Spring集成,使用的模式是分散收集。这里正在执行三个并行过程。流2是一个出站网关方法,如果该服务关闭,那么我想处理Httpstatus异常并希望发送null。实际上,如果该服务关闭,那么整个流程就会停止。但我想处理那个异常并发送null,然后想继续使用聚合方法并结束流程。 以下是代码-- //配置文件 网关 我可以使用类似于?但是我该怎么用呢? 我正在做这样的事情,但得到如下
-
由于窗口对象或内部处理而丢弃大量事件的数据流
最近开发了一个数据流消费者,它从PubSub订阅中读取数据,并将分组在同一窗口中的所有对象的组合输出到拼花文件。 当我在没有巨大负载的情况下进行测试时,一切似乎都很好。 然而,在执行了一些繁重的测试后,我可以看到,从发送到PubSub队列的1.000.000个事件中,只有1000个事件成功到达Parket! 根据不同阶段的多个墙时间,在应用窗口之前解析事件的墙时间似乎持续58分钟。写入拼花文件的最
-
在Cadence/Temporal工作流程中处理信号的最佳方式/模式是什么?
当使用像文档建议的那样的信号时: 我可能会遇到以下问题: 我想保证一次处理一个FIFO 我想处理signalWithStart的“赛车状态”,其中信号方法调用得太早 我想安全地重置工作流。重置后,可以在历史早期重新应用信号 我想确保工作流不会在信号处理之前提前完成
-
使用Spring批处理将文件解密到流中,转换并加密为文件
目的-解密一个.PGP加密的文件,读取数据作为流,执行转换到供应商的要求,加密作为流和写入一个文件。 逻辑-自定义读取器、写入器和任务程序,将解密/加密的数据存储到ExecutionContext并传递到不同的步骤。 适用于-小文件(~1MB) 面临问题-尝试使用(~10MB-10K记录)-读取步骤成功,但当开始将数据作为加密文件写入时-内存问题-Java.lang.OutOfMemoryErro
-
微软认知服务:有可能在流式URL上使用视频处理api吗?
我看到microsoft认知服务视频api在下载的视频上提供视频处理。我需要在流式url上测试视频运动检测,那么在流式视频上可以这样做吗?如果是这样,我们如何实现这一目标?
-
Spring云数据流定制应用程序处于部署状态
我创建了一个定制的Spring云流处理器应用程序,并将其部署为源|处理器|汇流中的处理器步骤。一切似乎都很好,但我的自定义应用程序在数据流UI中显示“部署”。如果这会影响任何事情,我会将其部署为mavenLocal的快照。我是否遗漏了一些让SCDF知道部署成功的信息?
-
如何检测处于僵尸状态的Kafka流应用程序
我们的一个Kafka Streams应用程序的StreamThread使用者在生成以下日志消息后进入了僵尸状态: [Consumer Clientid=Notification-Processor-DB9AA8A3-6C3B-453B-B8C8-106BF2FA257D-StreamThread-1-Consumer,GroupID=Notification-Processor]成员notific
-
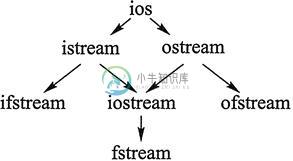 什么是流,C++输入流和输出流
什么是流,C++输入流和输出流主要内容:C++输入流和输出流本教程一开始就提到,C++ 又可以称为“带类的 C”,即可以理解为 C++ 是 C 语言的基础上增加了面向对象(类和对象)。在此基础上,学过 C 语言的读者应该知道,它有一整套完成数据读写(I/O)的解决方案: 使用 scanf()、gets() 等函数从键盘读取数据,使用 printf()、puts() 等函数向屏幕上输出数据; 使用 fscanf()、fgets() 等函数读取文件中的数据,使
-
字节流和字符流
问题内容: 请解释什么是字节流和字符流。这些到底是什么意思?Microsoft Word文档是面向字节还是面向字符? 谢谢 问题答案: 流是顺序访问文件的一种方式。字节流逐字节访问文件。字节流适用于任何类型的文件,但不适用于文本文件。例如,如果文件使用unicode编码,并且一个字符用两个字节表示,则字节流将分别处理这些字节,您需要自己进行转换。 字符流将逐字符读取文件。必须为字符流提供文件的编码
-
规则流在流口水
我不太会流口水和咕噜。 我有一个关于规则流的基本问题。 我在guvnor插件上使用引导编辑器创建了3条规则。现在我想根据第一条规则的结果调用第二条或第三条规则。 e、 g.如果患者年龄小于18岁,则进行第二条规则的小检查,否则请调用第三条规则由高级医生进行检查。 那么,这可以通过使用规则流来实现吗?如果是,如何?是否有任何示例链接和文档来演示它?非常感谢您的帮助。 谢啦
-
流程/工作流引擎
我正在研究一个需要工作流/流程引擎的解决方案。我的工作流包含一些基于Java的进程(类)和一些Linux Shell脚本。流程不会是静态的,每个流程的执行取决于前一个流程的状态/结果,将有多条路径,路径将由前一个流程的状态确定。 我尝试查看jBPM,但没有找到合适的支持来调用shell脚本。请根据我的要求为我推荐一个合适的替代方案。 非常感谢。
-
Spark流与结构化流
在过去的几个月里,我已经使用了相当多的结构化流来实现流作业(在大量使用Kafka之后)。在阅读了《Stream Processing with Apache Spark》一书之后,我有这样一个问题:有没有什么观点或用例可以让我使用Spark Streaming而不是Structured Streaming?如果我投入一些时间来研究它,或者由于im已经使用了Spark结构化流,我应该坚持使用它,而之
-
发出流的Java 8流
继续由标记。(换行、加字符、空格作为三个字符串。)连续可以是任意行数,包括0。 我想要以下输出(每个输出都是用)打印的一行): 我只想使用Java流来进行转换,最好是使用Collect。有没有一种方法可以优雅地做到这一点?
-
Java 8流内流并行
我有一个相当复杂的过程,需要几个层次的嵌套for循环。 只针对一组特定的条件执行操作。换句话说:
-
Kafka将KTable流到流INVALID_TOPIC_EXCEPTION
我的流服务执行的操作很少: 在进行测试时,我发现我的服务在调用函数后中断了,该函数将把我的数据写入由Kafka Streams将KTable转换为Kafka Streams创建的新主题。 我检查了KStreams创建的主题,主题就在那里: 我发现有三个输入,即,我不知道第三个输入是什么: 为了确保所有内容都被覆盖,这里是我的配置: 我的问题是,我们的部署正在工作,突然所有的东西都开始出现这个错误: