《flume》专题
-
超过内存事务容量后,Flume无法恢复
我正在创建一个 Flume 代理的概念验证,该代理将缓冲事件,并在接收器不可用时停止使用源中的事件。仅当接收器再次可用时,才应处理缓冲的事件,然后源重新启动消耗。 为此,我创建了一个简单的代理,它从SpoolDir读取并写入文件。为了模拟接收器服务关闭,我更改了文件权限,以便Flume无法写入。然后我启动Flume,一些事件被缓冲在内存通道中,当通道容量已满时,它将停止消耗事件,正如预期的那样。一
-
如何在FTP源Flume代理中保留文件的原始基名
我配置了一个flume代理,它从一个FTP服务器读取数据,并将文件发送到hdfs接收器。我最大的问题是,我想用它们的原始文件名在hdfs中存储文件。我试着用Spooldir source,它工作得很好,可以用它们的basename在hdfs中存储文件,但是flume agent crush: 1) 如果文件在放入假脱机目录后被写入,Flume将在其日志文件中打印错误并停止处理。 2) 如果稍后重用
-
Flume的身份验证错误Twitter4J
我想在CDH-5.3.2版本中使用水槽从twitter获取数据。我已经配置了flume.conf、hbase接收器和twitter源代码。 但是,当我启动代理时,我收到以下错误: flume.conf和hbase接收器代码与此博客相同:http://ahikmat.blogspot.com/2014/08/streaming-twitter-tweets-to-hbase-with.html 而且
-
Flume - 在 Linux 中将日志文件从 Windows 流式传输到 HDFS
如何将日志文件从Windows 7传输到Linux中的HDFS? Windows中的水槽出现错误 我已经在Windows 7(节点1)上安装了“flume-node-0.9.3”。“flumenode”服务正在运行,localhost:35862可以访问 在Windows中,日志文件位于“C:/logs/Weblogic”。log' CentOS Linux(节点2)中的Flume代理也在运行。
-
使用flume将twitter数据流传输到Hadoop时出错
我在Ubuntu 14.04上使用Hadoop-1.2.1 我正在尝试使用Flume-1.6.0将数据从twitter流式传输到HDFS。我已经下载了Flume-sources-1.0-SNAPSHOT。jar并将其包含在flume/lib文件夹中。我已经设置了flume-sources-1.0-SNAPSHOT的路径。jar在conf/FLUME环境中显示为FLUME_CLASSPATH。这是我
-
通过flume将事件数据写入HDFS时出错
我使用cdh3 update 4 tarball进行开发。我已经安装并运行了hadoop。现在,我还从cloudera viz 1.1.0下载了等效的flume tarball,并尝试使用hdfs-sink将日志文件的尾部写入hdfs。当我运行flume代理时,它开始正常,但当它试图将新的事件数据写入hdfs时,却以错误结束。我找不到比stackoverflow更好的小组来发布这个问题。这是我正在
-
使用本地文件系统作为Flume源
我刚刚开始学习大数据,目前,我正在研究Flume。我遇到的常见例子是使用一些Java处理推文(Cloudera的例子)。 仅仅为了测试和模拟的目的,我可以使用我的本地文件系统作为Flume源代码吗?特别是一些Excel或CSV文件?除了Flume配置文件,我还需要使用一些Java代码吗,就像在推特提取中一样? 这个源是事件驱动的还是可轮询的? 感谢您的意见。
-
使用 Apache Flume 收集 CPU 时间日志
我是Hadoop的新手,正在学习apache Flume。我在Virtualbox上安装了CDH 4.7。以下命令将输出顶部 cputime。如何使用 Apache flume 将以下命令的日志数据输出传输到我的 HDFS?如何创建水槽配置文件?
-
Flume Twitter流媒体问题
我正在使用Flume 1.6.0-cdh5.9.1使用Twitter源流式传输推文。 配置文件如下所示: 对于Cloudera. jar依赖项,我使用Maven使用以下依赖项构建了: 现在,当我运行Flume Agent时,它成功启动,连接到Twitter,但在最后一行(接收状态流)后停止: 在最后一行之后什么都没有发生。它不会终止,不会流式传输任何东西。我看了一下HDFS位置,那里没有创建任何东
-
Flume不接受Twitter流的关键字
Hadoop新手,使用本教程:https://acadgild.com/blog/streaming-twitter-data-using-flume/捕捉推文。这是我的水槽。conf文件: 它流式传输推特很好,它正确地保存到我想要的目录中,但它似乎在流式传输所有内容,而没有对我的关键字进行过滤。我收到了来自世界各地的推特,除了有那个标签。 可能是什么问题?
-
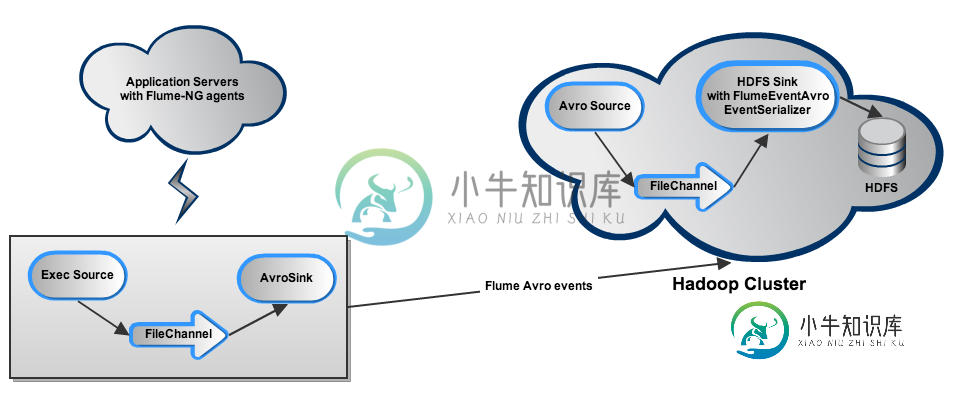 如何强制Flume-NG在接收器失败后处理事件积压?
如何强制Flume-NG在接收器失败后处理事件积压?我正在尝试设置 Flume-NG 以从一堆服务器(主要运行 Tomcat 实例和 Apache Httpd)收集各种日志,并将它们转储到 5 节点 Hadoop 集群上的 HDFS 中。设置如下所示: 每个应用程序服务器将相关日志尾随到一个Exec源中(每个日志类型对应一个:java、htpd、syslog),该源通过FileChannel将它们输出到Avro接收器。在每台服务器上,不同的源、通道
-
是否可以将WebHDFS与Flume一起使用?
我想让flume代理位于hadoop集群之外,并想知道是否有可能使用flume通过WebHDFS向hadoop集群发送消息。 如果没有,是否有使用WebHDFS的替代方案?使用多层水槽层仍然需要我在hadoop集群中运行水槽代理。
-
带有Flume的HDFS IO错误(hadoop 2.8)
当我尝试通过Flume将流数据输入hadoop时,我收到以下错误。 我已经在flume/lib中创建了指向< code >的链接。hadoop/share/hadoop/中的jar文件 我仔细检查了URL,我认为它们都是正确的。想发帖子来获得更多的关注和反馈。 这是水槽水槽配置 核心网站. xml - Hadoop 2.8
-
Apache Flume Hdfs水槽
我们可以为HDFS Sink添加分隔符吗?写入文件时,我们如何添加记录分隔符? 以下是配置:-
-
在flume中,您是否应该对spool目录源中的文件重命名授予写权限
我有一个水槽代理,它从假脱机目录源读取,并在一些转换后写入 hdfs。由于 flume 尝试将处理后的文件重命名为“.已完成“,我在假脱机目录中写入时遇到权限被拒绝异常。 我想知道向敏感数据授予写入权限的安全性如何。 是否有一轮关于水槽的解决方案来识别假脱机目录中已处理的文件