
如何强制Flume-NG在接收器失败后处理事件积压?

我正在尝试设置 Flume-NG 以从一堆服务器(主要运行 Tomcat 实例和 Apache Httpd)收集各种日志,并将它们转储到 5 节点 Hadoop 集群上的 HDFS 中。设置如下所示:
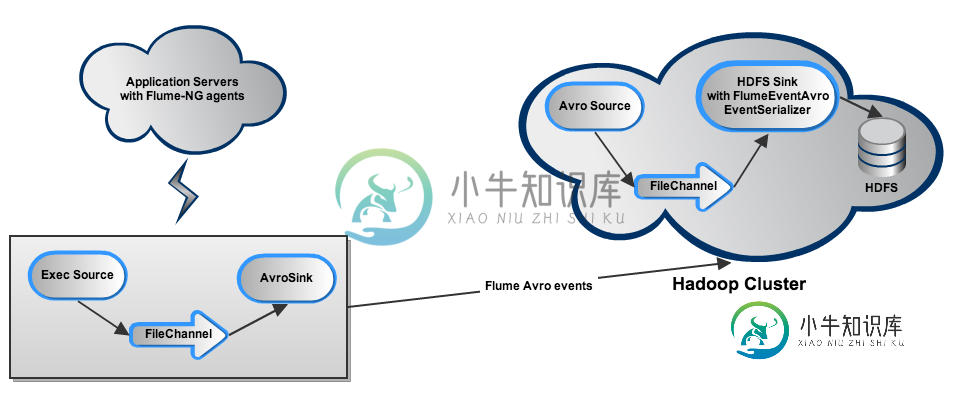
每个应用程序服务器将相关日志尾随到一个Exec源中(每个日志类型对应一个:java、htpd、syslog),该源通过FileChannel将它们输出到Avro接收器。在每台服务器上,不同的源、通道和接收器由一个代理管理。事件由驻留在Hadoop集群(该节点也托管了第二个名称节点和Jobtracker)上的AvroSource接收。对于每种日志类型,都有一个AvroSource侦听不同的端口。事件通过FileChannel进入HDFS接收器,HDFS接收器使用FlumeEventAvro EventSeriezer和Snappy压缩保存事件。
问题:Hadoop节点上管理HDFS接收器的代理(同样,每个日志类型一个)在几个小时后失败,因为我们没有更改JVM的堆大小。从那时起,许多事件被收集到该节点上的FileChannel中,之后也在应用程序服务器上的FileChannel上收集,因为Hadoop节点上的FileChannel达到了它的最大容量。当我修复问题时,我无法让 Hadoop 节点上的代理足够快地处理积压工作,以便它可以恢复正常操作。文件通道在沉没事件之前保存事件的 tmp 目录的大小一直在增长。此外,HDFS写入似乎真的很慢。有没有办法强制 Flume 在摄取新事件之前先处理积压工作?以下配置是否最佳?可能相关:写入HDFS的文件非常小,大约1 - 3 MB左右。对于HDFS默认的64MB块大小以及未来的MR操作来说,这肯定不是最佳的。我应该使用什么设置来收集足够大的文件中的事件,以适应 HDFS 块大小?我有一种感觉,Hadoop节点上的配置不正确,我怀疑BatchSize,RollCount和相关参数的值是关闭的,但我不确定最佳值应该是多少。
agent.sources=syslogtail httpdtail javatail
agent.channels=tmpfile-syslog tmpfile-httpd tmpfile-java
agent.sinks=avrosink-syslog avrosink-httpd avrosink-java
agent.sources.syslogtail.type=exec
agent.sources.syslogtail.command=tail -F /var/log/messages
agent.sources.syslogtail.interceptors=ts
agent.sources.syslogtail.interceptors.ts.type=timestamp
agent.sources.syslogtail.channels=tmpfile-syslog
agent.sources.syslogtail.batchSize=1
...
agent.channels.tmpfile-syslog.type=file
agent.channels.tmpfile-syslog.checkpointDir=/tmp/flume/syslog/checkpoint
agent.channels.tmpfile-syslog.dataDirs=/tmp/flume/syslog/data
...
agent.sinks.avrosink-syslog.type=avro
agent.sinks.avrosink-syslog.channel=tmpfile-syslog
agent.sinks.avrosink-syslog.hostname=somehost
agent.sinks.avrosink-syslog.port=XXXXX
agent.sinks.avrosink-syslog.batch-size=1
agent.sources=avrosource-httpd avrosource-syslog avrosource-java
agent.channels=tmpfile-httpd tmpfile-syslog tmpfile-java
agent.sinks=hdfssink-httpd hdfssink-syslog hdfssink-java
agent.sources.avrosource-java.type=avro
agent.sources.avrosource-java.channels=tmpfile-java
agent.sources.avrosource-java.bind=0.0.0.0
agent.sources.avrosource-java.port=XXXXX
...
agent.channels.tmpfile-java.type=file
agent.channels.tmpfile-java.checkpointDir=/tmp/flume/java/checkpoint
agent.channels.tmpfile-java.dataDirs=/tmp/flume/java/data
agent.channels.tmpfile-java.write-timeout=10
agent.channels.tmpfile-java.keepalive=5
agent.channels.tmpfile-java.capacity=2000000
...
agent.sinks.hdfssink-java.type=hdfs
agent.sinks.hdfssink-java.channel=tmpfile-java
agent.sinks.hdfssink-java.hdfs.path=/logs/java/avro/%Y%m%d/%H
agent.sinks.hdfssink-java.hdfs.filePrefix=java-
agent.sinks.hdfssink-java.hdfs.fileType=DataStream
agent.sinks.hdfssink-java.hdfs.rollInterval=300
agent.sinks.hdfssink-java.hdfs.rollSize=0
agent.sinks.hdfssink-java.hdfs.rollCount=40000
agent.sinks.hdfssink-java.hdfs.batchSize=20000
agent.sinks.hdfssink-java.hdfs.txnEventMax=20000
agent.sinks.hdfssink-java.hdfs.threadsPoolSize=100
agent.sinks.hdfssink-java.hdfs.rollTimerPoolSize=10
共有1个答案

我在您的配置中看到的几件事可能会导致问题:
>
您的第一个代理似乎有一个批量大小为1的avro接收器。您应该将其增加到至少100个或更多。这是因为第二个代理上的avro源将提交到批大小为1的通道。每次提交都会导致fsync,从而导致文件通道性能不佳。exec源上的批大小也是1,这导致该通道也很慢。您可以增加批量大小(或使用后台目录源-稍后详细介绍)。
您可以让多个 HDFS 接收器从同一通道读取以提高性能。你应该确保每个接收器写入不同的目录或具有不同的“hdfs.filePrefix”,以便多个 HDFS 接收器不会尝试写入相同的文件。
HDFS接收器的批大小为20000,这相当高,callTimeout默认为10秒。如果要保持如此大的批大小,应该增加“hdfs.callTimeout”。我建议将批量大小减少到1000左右,超时时间大约为15-20秒。(请注意,在当前的批处理大小下,每个文件只能容纳2个批处理-因此请减小批处理大小,增加rollInterval和timeOut)
如果您使用的是 tail -F,我建议您尝试新的假脱机目录源。若要使用此源,请将日志文件轮换到假脱机目录源处理的目录。此源将仅处理不可变的文件,因此您需要轮换日志文件。将尾巴 -F 与 exec 源一起使用存在问题,如 Flume 用户指南中所述。
-
某些HDFS接收器文件未关闭 有人说,如果接收器进程因超时条件等问题而失败,它不会再次尝试关闭文件。 我已经查看了水槽日志文件,但没有错误。然而,日志文件显示,每个周期,flume生成两个tmp文件,只关闭一个tmp。。。 对于配置的任何建议将不胜感激!谢谢!
-
我们使用Flume和S3来存储我们的事件。我认识到,只有当HDFS接收器滚动到下一个文件或Flume优雅地关闭时,事件才会传输到S3。 在我看来,这可能会导致潜在的数据丢失。Flume文档写道: ...Flume使用事务性方法来保证事件的可靠传递。。。 此处是我的配置: 我想我只是做错了什么,有什么想法吗?
-
我有一个写日志到HDFS的Flume-ng。 我在一个节点中做了一个代理。 但是它没有运行。 这是我的配置。 #示例2.conf:单节点水槽配置 #命名这个代理上的组件 agent1.sources=源1 agent1.sinks=sink1 agent1.channels=channel1 agent1.sources.source1.type=avro agent1.sources.sourc
-
水槽新手。 假设我有一个代理,它有一个 avero 源、一个 hdfs 接收器和一个文件通道。 假设在某个时候接收器无法写入hdfs。源是否会继续接受事件,直到通道填满? 或者即使文件通道未满,源也会停止接受事件吗?
-
我看到了几个与此相关的问题,但不太明白我在寻找什么。我使用的是Flume 1.8.0,在Flume代理被强制终止后,我看到了.tmp文件。这些不会在水槽药剂重新启动时清理干净。有没有任何方法可以配置Flume代理来执行清理,或者这是我需要自己处理的事情(在Flume之外)? 这是我测试的水槽 conf 文件: 使用上面的conf文件启动Flume代理。在它向HDFS写入了几个文件后,使用杀-9杀死
-
我面临一个奇怪的问题。我正在寻找从水槽到HDFS的大量信息。我应用了推荐的配置,以避免过多的小文件,但它不起作用。这是我的配置文件。 这个配置有效,我看到了我的文件。但文件的平均重量为1.5kb。水槽控制台输出提供了此类信息。 有人知道这个问题吗? 以下是有关水槽行为的一些信息。 该命令是flumengagent-na1-c/path/to/flume/conf-conf文件示例flume。con