《flume》专题
-
为什么syslogudp的Flume中会丢失数据包?
使用Flume源syslogudp,我看到大约25%的数据丢失。 这是我的配置 a1.sources = r1 a1.sinks=k1 a1 .通道= c1 a1.sources.r1.type = syslogudp a1.sources.r1.bind = 172.24.1.78 a1.sources.r1.port = 65535 a1.sinks.k1.type=文件滚动 水槽。水槽。目录
-
flume、spark、storm能循环阅读Kafka的作品吗?
我有3个分区:0、1、2。因此,这些消息可以分为0、1、2。 eg: 1消息在分区0:0 分区1中的3条消息:111 分区2中的2条消息:22 如何使消费者以012x12x1x的顺序使用消息(x表示当时没有消息)。已消费消息的顺序如下所示:012121。我想在C和Python中都这样做。从现有的客户端来看,消息可以以循环方式生成,但不能以循环方式消费。 任何想法? Kafka消费者配置(http:
-
未找到Spark Scala Flumeutill
我得到以下错误: https://spark.apache.org/docs/1.4.1/streaming-flume-integration.html
-
Apache flume twitter代理不流数据
我试图将twitter提要流到hdfs,然后使用Hive。但是第一部分,流数据和加载到hdfs不起作用,并给出空指针异常。 这是我尝试过的。 4.我将flume-sources-1.0-snapshot.jar添加到/user/lib/flume/lib。 5.启动Hadoop并执行以下操作 6.我在/user/lib/flume中运行以下内容
-
3.1.26 Flume监控
在数据采集一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。 Flume的数据采集可以通过脚本flume-monitor来做。 工作原理 flume-monitor.py是一个采集脚本,只需要放到falcon-agent的plugin目录,在portal中将对应的plugin绑定
-
Flume 监控
在数据采集一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。 Flume的数据采集可以通过脚本flume-monitor来做。 工作原理 flume-monitor.py是一个采集脚本,只需要放到falcon-agent的plugin目录,在portal中将对应的plugin绑定
-
5.3.3.3-基于-Spark-Streaming、Kafka、Flume--日志流处理系统搭建
1.1 配置依赖 <!-- log4j --> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.
-
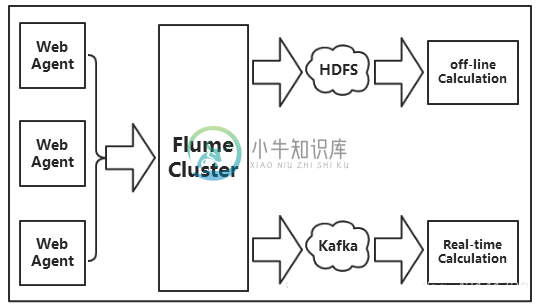 Flume传输数据给kafka
Flume传输数据给kafka主要内容:相关知识,2.系统环境,3.任务内容,4.任务步骤1.相关知识 Flume是一个海量日志采集、聚合和传输的日志收集系统。 Kafka是一个可持久化的分布式的消息队列。 由于采集和处理数据的速度不一定同步,所以使用Kafka这个消息中间件来缓冲,如果你收集了日志后,想输出到多个业务方也可结合Kafka,Kafka支持多个业务来读取数据。 上图中Kafka生产的数据,是由Flume提供的,这里我们需要用到Flume集群,通过Flume集群将Agent
-
Flume-channel/Sink/Source
主要内容:Channel一个Source可以对多个Channel 一个Channel对一个Sink 一个Sink对一个Channel 一个Channel对一个Source Source相当于原点,接收方Cannel相当于临时队列,速率比较快,Sink相当于发送方。 Channel 临时队列 Flume中提供的Channel实现主要有三个: Memory Channel event保存在Java Heap中。如果允许数据小
-
 Flume
Flume主要内容:1.为什么用Flume,2.Flume可靠性,3.Flume版本,4.Flume OG,5.Flume NG,5.总结1.为什么用Flume 1.海量日志采集,聚合和传输的系统 2.支持在日志系统中定制各类数据发送方,用于收集数据 3.提供对数据进行简单处理,可写到各种数据接收方。 比如将AAA开头的数据放在一个目录中 将BBB开投的放在一个目录中 2.Flume可靠性 提供了3中可靠性模式 End-to-end Store on failure Best effort 3.Flume
-
Apache Flume
Flume 是一个分布式、可靠和高可用的服务,用于收集、聚合以及移动大量日志数据,使用一个简单灵活的架构,就流数据模型。这是一个可靠、容错的服务。
-
flume-append-file-sink
flume追加内容到文件末尾的sink。 仅适合1g以内的日志,再大估计会有压力,没具体测试。 依赖 Flume-NG >= 1.7 Linux MacOS 构建 $ mvn clean package jar文件下载 flume-append-file-sink-1.0.jar 配置参数 Property Name Default Description sink.fileName - 文件名
-
flume-canal-source
相信很多人对阿里开源的 canal 和 apache flume 都不陌生。 flume-canal-source 是对 flume 的 source 扩展。从 canal 获取数据到 flume channel 。 进而可以实现 binlog 数据到 kafka/hdfs/hive/elasticsearch 等等。 如何使用 部署 canal、flume 这里忽略。 配置 flume 配置 s
-
scc-flume-plugin
本插件是对 Flume 现有插件的扩充,主要是: 1、kafka-source,相对 flume 自带插件,升级了 kafka 依赖版本,支持更高版本的 kafka 集群,并支持自动扫描特定 topic ,无需在配置文件指定,并且自动匹配出 timestamp、level、topic、message 等常用字段; 2、kafka-channel,相对 flume 自带插件,升级了