《flume》专题
-
使用Flume Avro的日志数据未正确存储在配置单元中
我使用Flume 1.5.0从应用程序服务器收集日志。假设我有三个应用服务器,应用程序A,应用程序B,应用程序C。一个运行hive的HDFS服务器。现在水槽代理正在所有3个应用服务器上运行,并将日志消息从应用服务器传递到Hdfs服务器,在那里另一个水槽代理正在运行,最终日志存储在hadoop文件系统中。现在我已经创建了一个外部Hive表来映射这些日志数据。但是除了hive无法正确解析日志数据并存储
-
无法在Flume-ng中创建类型为HDFS的接收器
我有一个写日志到HDFS的Flume-ng。 我在一个节点中做了一个代理。 但是它没有运行。 这是我的配置。 #示例2.conf:单节点水槽配置 #命名这个代理上的组件 agent1.sources=源1 agent1.sinks=sink1 agent1.channels=channel1 agent1.sources.source1.type=avro agent1.sources.sourc
-
通过HDFS接收器将flume事件写入S3确保事务
我们使用Flume和S3来存储我们的事件。我认识到,只有当HDFS接收器滚动到下一个文件或Flume优雅地关闭时,事件才会传输到S3。 在我看来,这可能会导致潜在的数据丢失。Flume文档写道: ...Flume使用事务性方法来保证事件的可靠传递。。。 此处是我的配置: 我想我只是做错了什么,有什么想法吗?
-
使用Flume将数据从kafka摄取到HDFS::ConfigurationException:必须指定引导服务器
我正在尝试使用flume将数据从Kafka源接收到hdfs。下面是我的flume配置文件。 我正在使用以下命令运行flume agent: 但我得到以下错误: 18/03/12 16:49:18 ERROR节点. AbstractConfigurationProvider: Source kafka-source-1已被删除,由于配置过程中的错误unnable.runConfigurationEx
-
找出flume从twitter下载的tweets的位置
我使用了一些关键字,并使用Flume从twitter下载了tweets。 {“filter_level”:“medium”,“contributors”:null,“text”:“梅西,厄齐尔,CR7&苏亚雷斯·伯腾格·迪兰博基尼T.co/skk8xnnjl7”,“geo”:null,“retweeted”:false,“in_reply_to_screen_name”:null,“possibl
-
通过Apache Flume将日志文件从本地文件系统移动到HDFS时出错
我的本地文件系统中有日志文件,需要通过Apache Flume传输到HDFS。我在主目录中将以下配置文件另存为net.conf 在主目录中运行命令后 我得到了以下输出:
-
我正在aws实例上运行flume代理,无法从aws实例上的avro接收器接收到本地计算机上的avro源的事件?
这是在我的aws实例的控制台上出现的错误。 2014-08-09 12:22:41,803(lifecycleSupervisor-1-2)[info-org.apache.flume.source.avrosource.start(avrosource.java:142)]从本地启动Avro源代码:{bindaddress:ec2-54-221-143-114.compute-1.amazona
-
Apache Flume花费的时间比创造性命令多
我在本地文件系统中有24GB文件夹。我的任务是将该文件夹移动到HDFS。我有两种方法。1)hdfs dfs-复制来自本地 /home/data/ /home/ 这大约需要 15 分钟才能完成。 2)使用水槽。 这是我的经纪人 这一步花了将近一个小时将数据推送到HDFS。 据我所知,Flume是分布式的,所以Flume加载数据的速度应该比copyFromLocal命令更快。
-
如何使用Apache Flume过滤多个源数据?
我正在使用 flume 来处理多个源数据并存储在 HDFS 中,但我无法理解如何在存储在 HDFS 中之前过滤数据。
-
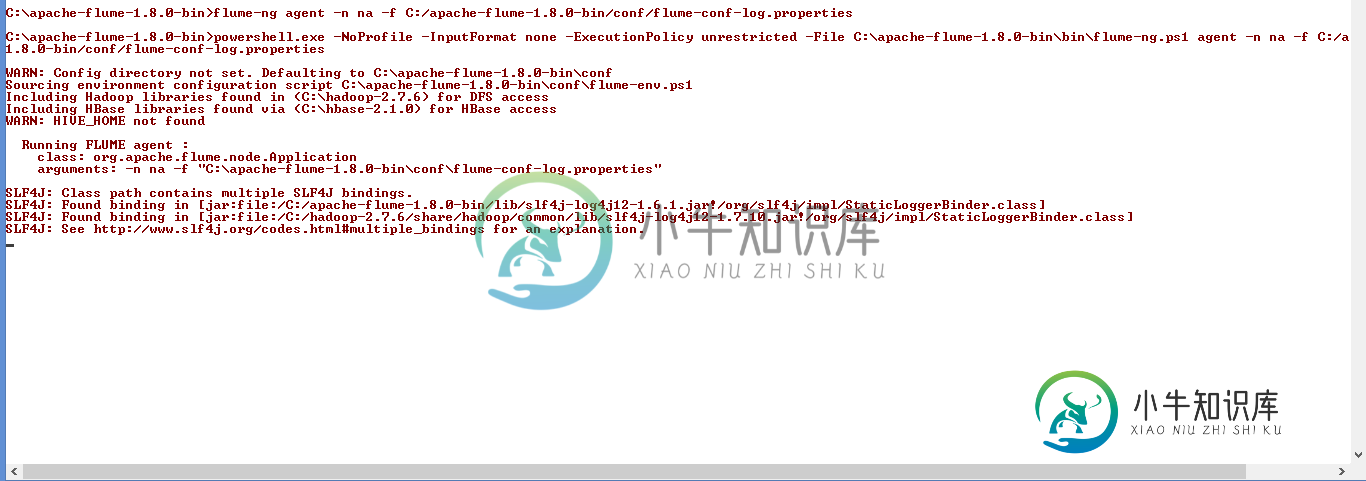 Apache Flume在我第一次在Windows上安装时没有卡住
Apache Flume在我第一次在Windows上安装时没有卡住我已经下载了最新版本的Apache Flume“apache-flume-1.8.0-bin”,并在第一次启动时更改了配置,如下所示。我正在Windows 8.1中设置apache flume 保存此配置后,我尝试使用以下命令启动水槽代理 之后,它陷入了水槽代理的启动,如下所示, 我附上了错误截图供参考。我需要处理服务器日志来捕捉错误消息,为此我需要使用Flume将日志流至HDFS。 启动时水槽卡
-
Apache Flume/var/log/Flume-ng/Flume . log(权限被拒绝)
我正在尝试从/home/cloudera/Documents/flume/读取日志文件,并使用apache-flume将其写入hdfs。我使用以下命令在hdfs中创建flumeLogTest文件夹: 我的配置文件是: 我通过以下命令启动水槽代理: 其中Documents/flume是/home/cloudera/中的一个文件夹,该文件夹包含以下文件 flume-conf.properties。模板
-
格式化Apache Flume HDFS串行器
我刚刚开始使用水槽,需要插入一些标题到hdfs水槽。 尽管格式错误并且无法控制列,但我仍然可以正常工作。 使用此配置: 写入HDFS的日志除了串行化的方面外,主要是正常的: 如何格式化日志,使其看起来像这样: 时间戳首先是主机名,然后是系统日志 msg 正文。
-
执行水槽后Apache Flume卡住了
我需要帮助。 我已经下载了Apache Flume并安装在Hadoop之外,只是想尝试通过控制台进行netcat日志记录。我使用1.6.0版本。 这是我的confhttps://gist.github.com/ans-4175/297e2b4fc0a67d826b4b 这是我是如何开始的 但是仅在打印这些输出后就卡住了 对于简单的启动和安装有什么建议吗? 谢谢
-
Apache Flume HDFS接收文件写有什么保证?
如果Flume代理在HDFS文件写入过程中被杀死(比如使用Avro格式),有人能解释一下会发生什么吗?文件会被破坏,所有事件都会丢失吗? 我了解Flume数据链的不同元素之间存在交易(来源-
-
使用拦截器过滤Flume中的日志文件
我有一个超文本传输协议服务器写入日志文件,然后使用Flume将其加载到HDFS。首先,我想根据标头或正文中的数据过滤数据。我读到我可以使用正则表达式的拦截器来做到这一点,有人能解释一下我需要做什么吗?我需要编写Java代码来覆盖Flume代码吗? 我还想获取数据并根据标头将其发送到不同的接收器(即 source=1 转到 sink1,source=2 转到 sink2)这是如何完成的? 谢谢 希蒙