《flink》专题
-
Flink中的水印和触发器有什么区别?
我读到,“...排序运算符必须缓冲它收到的所有元素。然后,当它收到水印时,它可以对时间戳低于水印的所有元素进行排序,并按排序顺序发出它们。这是正确的,因为水印表明不会有更多的元素到达,这些元素会与排序的元素混合在一起......”-流中的https://cwiki.apache.org/confluence/display/FLINK/Time和顺序 因此,水印似乎可以作为信号发送给以下操作符,以
-
Apache Flink-timerService,onTimer获取整个事件
我需要一些关于Apache Flink中timerService的帮助。我的用例非常简单,但我没有找到任何明确的答案。 我的程序从源(在我的例子中是rabbitMQ)接收json格式的事件(映射到MyEvent,这里简化了MyEvent)。事件可以立即处理(1),也可以存储以供以后处理(2)。(2) 我认为TimerService是适当的解决方案。在onTimer方法中,我需要整个对象(MyEve
-
Apache flink-时间特性
我如何在Apache flink中使用摄取时间特征。我知道我们需要设置环境时间特征。但是我如何收集带有时间戳的数据,可以称为摄取时间。目前我使用它时,它是根据系统时钟时间处理窗口。我想根据数据进入flink环境的时间进行处理。 有助于清晰理解的少量代码摘录: 环境的时间特征: 窗口时间: 源中的集合: 如果数据采集在11:03开始,我想在11:08结束,即5分钟。但它会在11点05分停止(某种程度
-
Flink事件时间处理水印总是-9223372036854725808
我试图使用process函数对一组事件进行处理。我正在使用事件时间和键控流。我面临的问题是,水印值始终为9223372036854725808。我已经对print语句进行了调试,它显示如下: 时间戳------1583128014000提取时间戳1583128014000当前水印------9223372036854775808 时间戳------1583128048000提取时间戳1583128
-
Flink CEP模式与启动作业后的第一个事件不匹配,并且始终与之前设置的事件匹配
我想用以下代码匹配Flink 1.4.0 Streaming中的CEP模式: 只是一个POJO 从我的自定义源(Google PubSub)中提取。第一个过滤器FilterEmptyAndInvalidEvents()只过滤格式不正确的事件等,但在这种情况下不会发生这种情况。由于日志输出,我可以验证这一点。因此,每个事件都会通过MyKeySelector运行。getKey()方法。 仅从一个字段中
-
Flink CEP:FollowedBy模式:同一事件多次循环该模式
我是Flink CEP的新手,一直在玩弄这些模式,以便更好地理解它们。我有一个简单的“开始”的例子 Pattern match\u win=模式。开始(“第一”)。其中(new SimpleCondition(){ 我正在通过4,4,6 并行度设置为1。 StreamExecutionEnvironment env=StreamExecutionEnvironment。getExecutionEn
-
Flink CEP事件未触发
我已经在Flink中实现了CEP模式,它按预期工作连接到本地Kafka代理。但是当我连接到基于集群的云kafka设置时,Flink CEP不会触发。 我正在使用AscendingTimestampExtractor, 我也收到警告消息, AscendingTimestampExtractor:140-违反时间戳单调性:1594017872227 而且我也尝试过使用Assignerwith周期水印和
-
如果在Apache flink中5秒内5次发现相同数据,则生成CEP事件
如果我们发现字符串消息在5秒内连续以字符“a”开头5次,我需要生成CEP事件。 为此,我编写了一个类CEPCharEventPublisher。java,将字符串消息(如下发布的消息)发布到kafka主题“charEvent” 已发布消息: 现在我有一个消费者CEPCharEventConsumer.java它将读取来自Kafka主题charEvent的消息并过滤以字符“a”开头的消息。 然后,我
-
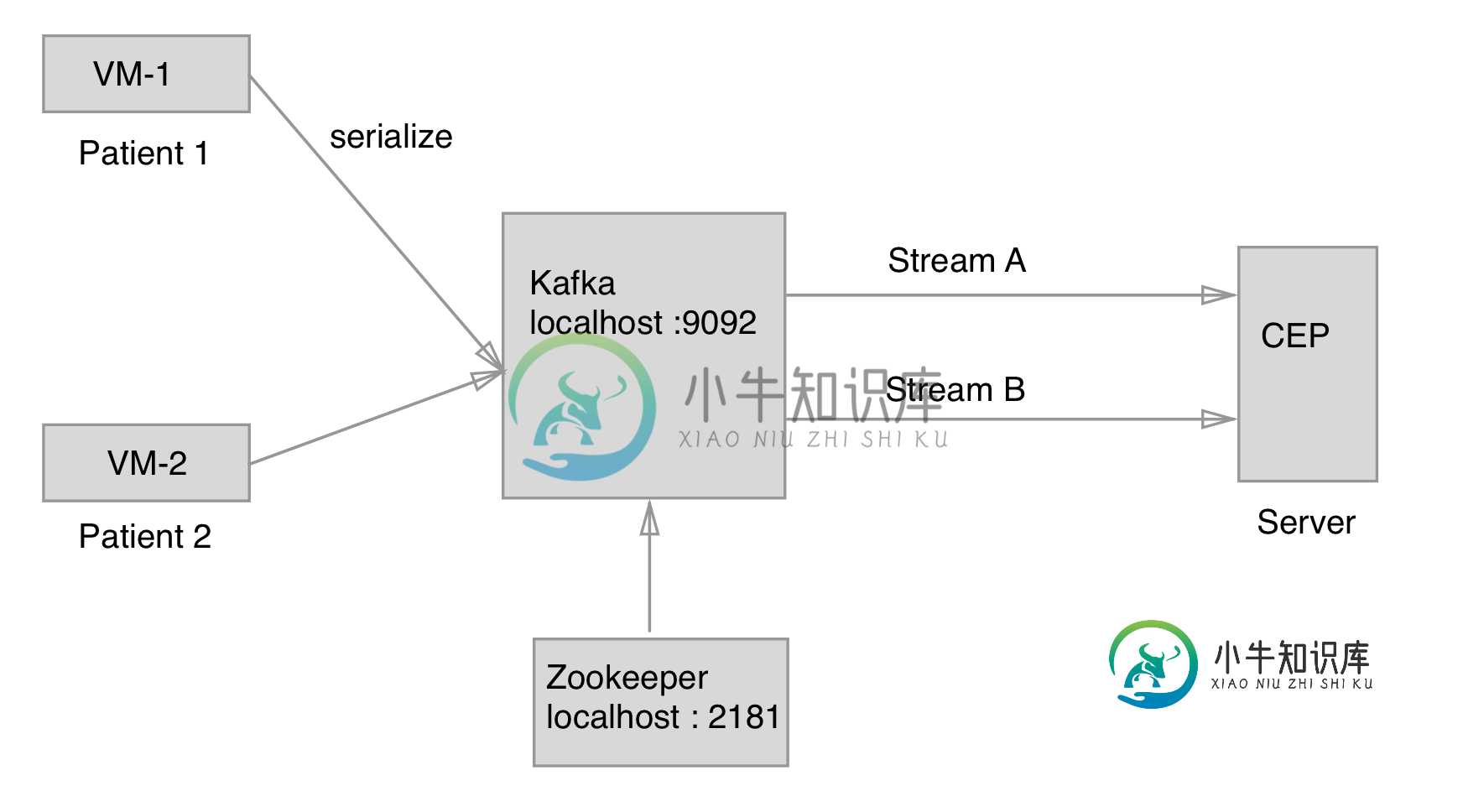 并行处理Flink CEP中的多种模式
并行处理Flink CEP中的多种模式我有以下情况 有2个虚拟机正在向Kafka发送流,CEP引擎正在接收这些流,当单个流满足特定条件时,会生成警告。 目前,CEP正在检查两条流上的相同情况(当心率 但我想对这两个流使用不同的条件。例如,如果 如何实现这一点?我需要在同一环境中创建多个流环境或多个模式吗?
-
Flink精确一次消息处理
我已经设置了一个Flink 1.2独立集群,其中包含2个JobManager和3个TaskManager,我正在使用JMeter通过生成Kafka消息/事件对其进行负载测试,然后处理这些消息/事件。处理作业在TaskManager上运行,通常需要大约15K个事件/秒。 作业已设置EXACTLY_ONCE检查点,并将状态和检查点持久化到Amazon S3。如果我关闭运行作业的TaskManager需
-
Apach Flink CEP“至少”条件
我正在尝试创建一个与“至少”事件匹配的CEP模式。修改示例代码: 成 不解决我的问题,因为条件将不断失败,永远无法贡献计数。 我在中找到https://ci.apache.org/projects/flink/flink-docs-release-1.3/dev/libs/cep.html确实有 有start.at存在吗?
-
如何调试Apache Flink?
我一直致力于扩展Apache Flink Python API,以更好地匹配Java API,但我在处理的数据类型方面遇到了奇怪的错误。是否有一种方法可以附加Java调试器(例如Intellij IDEA)来调试Flink本身?
-
当Flink中的Kafka数据有新的Avro模式时,如何更新表模式?
我们正在使用Flink表API在Flink应用程序中使用一个Kafka主题。 当我们第一次提交应用程序时,我们首先从我们的自定义注册表中读取最新的模式。然后使用Avro模式创建一个Kafka数据流和表。我的数据序列化器的实现与汇合模式注册表的工作方式类似,方法是检查模式ID,然后使用注册表。因此我们可以在运行时应用正确的模式。
-
 Apache Flink-如何实现自定义反序列化器实现DeserializationSchema
Apache Flink-如何实现自定义反序列化器实现DeserializationSchema我用的是Flink我用的是Kafka连接器。我从flink收到的消息是一个逗号分隔的项目列表。“'a','b','c',1,0.1...'12:01:00.000'”其中一个包含事件时间,我想将此事件时间用于每个分区的水印(在kafka源代码中),然后将此事件时间用于会话窗口化。我的情况与通常情况有点不同,因为根据我的理解,人们通常使用“Kafka时间戳”和SimpleStringSchema()
-
如何定义具有行时间属性的apache flink表