
并行处理Flink CEP中的多种模式

我有以下情况
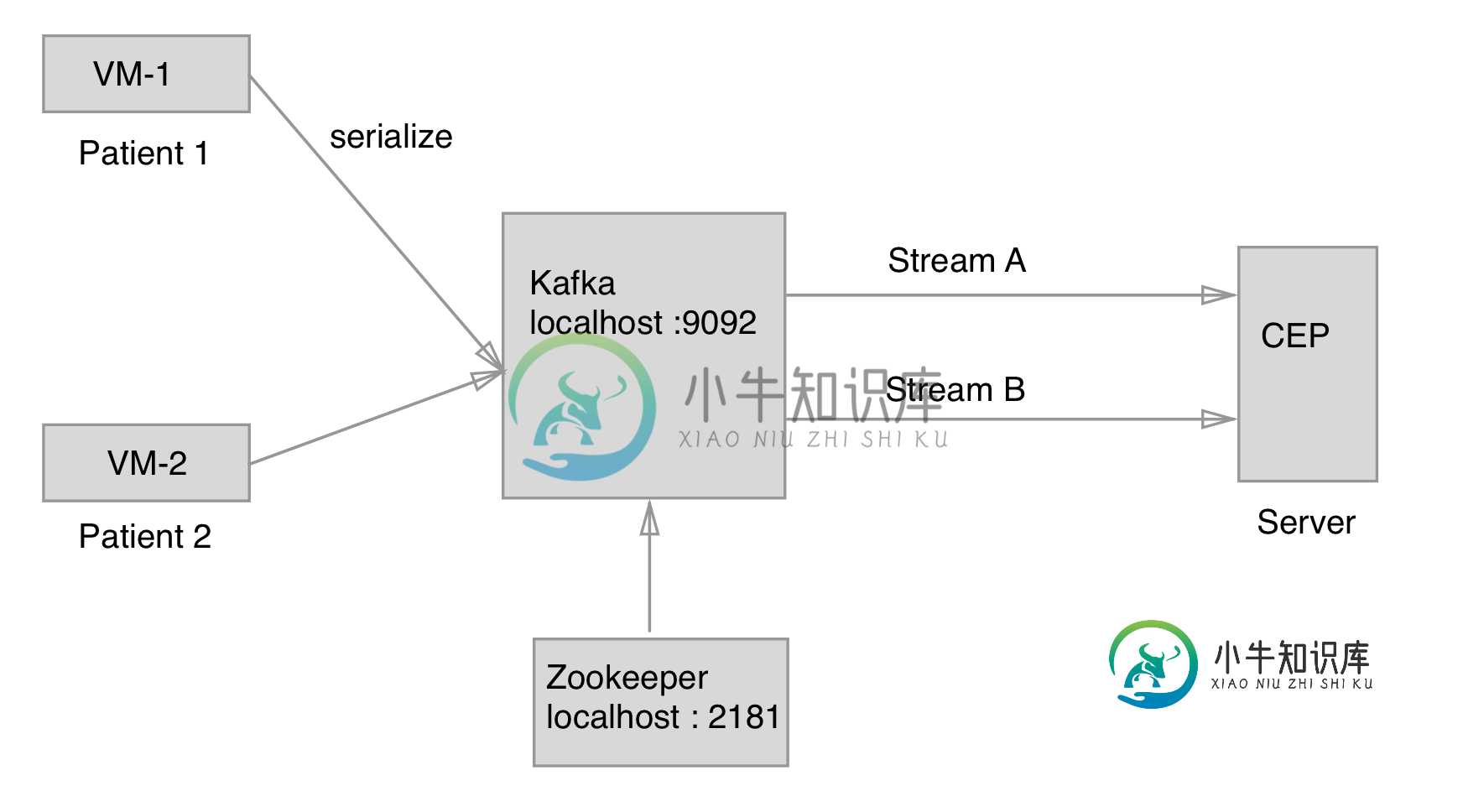
有2个虚拟机正在向Kafka发送流,CEP引擎正在接收这些流,当单个流满足特定条件时,会生成警告。
目前,CEP正在检查两条流上的相同情况(当心率
// detecting pattern
Pattern<joinEvent, ? > pattern = Pattern.<joinEvent>begin("start")
.subtype(joinEvent.class).where(new FilterFunction<joinEvent>() {
@Override
public boolean filter(joinEvent joinEvent) throws Exception {
return joinEvent.getHeartRate() > 65 ;
}
})
.subtype(joinEvent.class)
.where(new FilterFunction<joinEvent>() {
@Override
public boolean filter(joinEvent joinEvent) throws Exception {
return joinEvent.getRespirationRate() > 68;
}
}).within(Time.milliseconds(100));
但我想对这两个流使用不同的条件。例如,如果
For patient A : if heart rate > 65 and Respiration Rate > 68
For patient B : if heart rate > 75 and Respiration Rate > 78
如何实现这一点?我需要在同一环境中创建多个流环境或多个模式吗?
共有1个答案

根据您的需求,如果需要,您可以创建两种不同的模式来进行清晰的分离。
如果您想以相同的模式执行此操作,那么它也是可能的。为此,请在一个kafka源中阅读所有kafka主题:
FlinkKafkaConsumer010<JoinEvent> kafkaSource = new FlinkKafkaConsumer010<>(
Arrays.asList("topic1", "topic2"),
new StringSerializerToEvent(),
props);
在这里,我假设两个主题的事件结构是相同的,并且您有患者姓名以及事件的一部分。
一旦这样做了,就变得很容易了,因为您只需要创建一个带有“或”的模式,如下所示:
Pattern.<JoinEvent>begin("first")
.where(new SimpleCondition<JoinEvent>() {
@Override
public boolean filter(JoinEvent event) throws Exception {
return event.getPatientName().equals("A") && event.getHeartRate() > 65 && joinEvent.getRespirationRate() > 68;
}
})
.or(new SimpleCondition<JoinEvent>() {
@Override
public boolean filter(JoinEvent event) throws Exception {
return event.getPatientName().equals("B") && event.getHeartRate() > 75 && joinEvent.getRespirationRate() > 78;
}
});
这将在您的条件匹配时产生匹配。尽管如此,我并不确定在您的示例中“.within(Time.millises(100))”实现了什么。
-
问题内容: 给出以下代码: 我可以假设’dowork’函数将并行执行吗? 这是实现并行性的正确方法,还是对每个goroutine使用通道并将单独的“ workwork”工人分开更好? 问题答案: 关于GOMAXPROCS,您可以在Go 1.5的发行文档中找到: 默认情况下,Go程序在将GOMAXPROCS设置为可用内核数的情况下运行;在以前的版本中,它默认为1。 关于防止main功能立即退出,您可
-
问题内容: 什么是在python 2.7中进行并行处理的简单代码?我在网上找到的所有示例都是令人费解的,其中包括不必要的代码。 我如何做一个简单的蛮力整数分解程序,在其中我可以在每个核(4)上分解一个整数?我的真实程序可能只需要2个内核,并且需要共享信息。 我知道并存python和其他库,但是我想将使用的库数保持最少,因此我想使用和/或库,因为它们是python附带的 问题答案: 从python中
-
我是Spring批处理的新手,我只想问如何从多行结果集中检索数据。我有以下场景: > 有两个不同的表说员工 使用时,我只能创建一个工资单子级,但该表可能有多个子级。请帮助...
-
问题内容: 我有一个程序处理大量文件,其中每个文件都需要做两件事:首先,读取并处理一部分文件,然后存储结果。第一部分可以并行化,第二部分不能并行化。 顺序执行所有操作非常慢,因为CPU必须等待磁盘,然后工作一点,然后发出另一个请求,然后再次等待… 我做了以下 这很有帮助。但是,我想改善两点: 在获取一个固定的顺序,而不是处理任何结果,请首先执行。我该如何更改? 有成千上万的文件要处理,启动成千上万
-
我有一个处理大量文件的程序,其中每个文件需要做两件事:首先,读取并处理文件的一部分,然后存储生成的MyFileData。第一部分可以并行,第二部分不能并行。 按顺序做每件事都非常慢,因为CPU必须等待磁盘,然后工作一点,然后发出另一个请求,然后再次等待。。。 我做了以下事情 这很有帮助。然而,我想改进两件事: > 以固定顺序执行,而不是首先处理任何可用的结果。如何更改它? 有数千个文件需要处理,启
-
当我使用Spring批处理管理运行长时间运行的批处理作业的多个实例时,它会在达到jobLauncher线程池任务执行程序池大小后阻止其他作业运行。但是从cron中提取多个工作似乎效果不错。下面是作业启动器配置。 Spring批处理管理员Restful API是否使用不同于xml配置中指定的作业启动器?