《决策树》专题
-
SSD上的基准MySQL:工具和策略
问题内容: 我目前正在将服务器从硬盘驱动器上的MyISAM切换到SSD上的InnoDB。 我有一个 3,800,000行(16GB)的 表作为基准表。 我的服务器设置: Ubuntu 64 + Nginx + MySQL 5.5 + … 我有两件事要测试,请牢记: 从硬盘驱动器切换到SSD将如何影响并发性 从MyISAM切换到InnoDB将如何影响并发性 我对工具和策略都有疑问: 由于我对并发性最
-
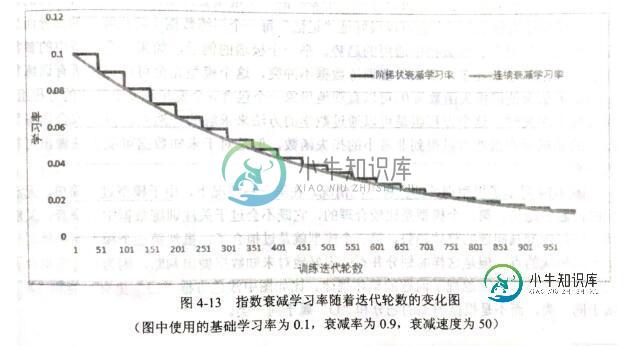 TensorFlow神经网络优化策略学习
TensorFlow神经网络优化策略学习本文向大家介绍TensorFlow神经网络优化策略学习,包括了TensorFlow神经网络优化策略学习的使用技巧和注意事项,需要的朋友参考一下 在神经网络模型优化的过程中,会遇到许多问题,比如如何设置学习率的问题,我们可通过指数衰减的方式让模型在训练初期快速接近较优解,在训练后期稳定进入最优解区域;针对过拟合问题,通过正则化的方法加以应对;滑动平均模型可以让最终得到的模型在未知数据上表现的更加健壮
-
Yii2的XSS攻击防范策略分析
本文向大家介绍Yii2的XSS攻击防范策略分析,包括了Yii2的XSS攻击防范策略分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Yii2的XSS攻击防范策略。分享给大家供大家参考,具体如下: XSS 漏洞修复 原则: 不相信客户输入的数据 注意: 攻击代码不一定在<script></script>中 ① 将重要的cookie标记为http only, 这样的话Javascript 中
-
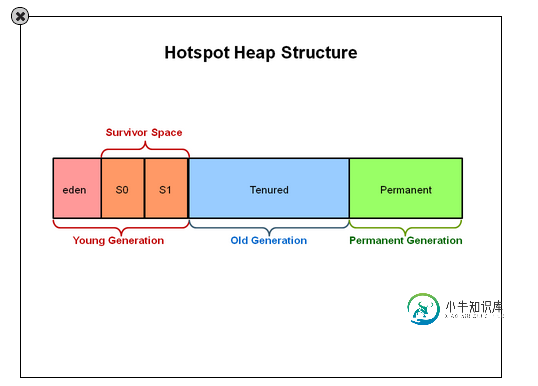 浅谈jvm中的垃圾回收策略
浅谈jvm中的垃圾回收策略本文向大家介绍浅谈jvm中的垃圾回收策略,包括了浅谈jvm中的垃圾回收策略的使用技巧和注意事项,需要的朋友参考一下 java和C#中的内存的分配和释放都是由虚拟机自动管理的,此前我已经介绍了CLR中GC的对象回收方式,是基于代的内存回收策略,其实在java中,JVM的对象回收策略也是基于分代的思想。这样做的目的就是为了提高垃圾 回收的性能,避免对堆中的所有对象进行检查时所带来的程序的响应的延迟,因
-
Apollo Client React中的错误策略无效
我在测试Apollo时遇到了问题。当我尝试使用apollo和graph ql进行查询时,我想要响应返回错误和部分数据,所以我设置了属性errorPolicy:“all”。但它不起作用。我不知道为什么?请帮助!这是我的代码: 查询{动物{姓名年龄},学校{姓名数字}}` const{加载,数据,错误}=使用查询(GET\u DASHBOARD\u data,{错误策略:'all',未完成:(res)
-
无法解释id生成器策略:x.y.z.CustomIDGenerator
我遇到了Hibernate映射问题:无法解释ID生成器策略:堆栈跟踪: 我的Custome ID生成器类如下所示: 我在谷歌上搜索过,但找不到解决方案。请让我知道,如果我做了任何错误或有解决办法。谢谢
-
 C#策略模式(Strategy Pattern)实例教程
C#策略模式(Strategy Pattern)实例教程本文向大家介绍C#策略模式(Strategy Pattern)实例教程,包括了C#策略模式(Strategy Pattern)实例教程的使用技巧和注意事项,需要的朋友参考一下 本文以一个简单的实例来说明C#策略模式的实现方法,分享给大家供大家参考。具体实现方法如下: 一般来说,当一个动作有多种实现方法,在实际使用时,需要根据不同情况选择某个方法执行动作,就可以考虑使用策略模式。 把动作抽象成接口,
-
解释了CSRF、令牌和同源策略
所以我知道有很多关于CSRF的问题(因为我读过其中一些),但有一点我仍然不明白。让我们设想以下情况: > 我(使用cookies)登录到我的服务器,其中有一个带有“删除我的帐户”按钮的页面。我不想逼你。 我访问黑客的服务器: A.我的浏览器请求bad.html,其中包含JS,并定义了回调函数。它还有一个脚本,比如:(从而避免了同源政策问题) B.脚本"附加"浏览器将加载页面,然后调用hackerC
-
同源政策和CORS-有什么意义?
我很难理解同源策略和“解决”它的不同方法。 很明显,同源策略是作为一种安全措施存在的,因此来自服务器/域的脚本不能访问来自另一服务器/域的数据。 也很明显,有时打破这一规则是很有用的,例如mashup应用程序访问来自不同服务器的信息以构建所需的结果。做到这一点的方法之一是CORS。 1)如果我没有错的话,CORS允许目标服务器通过在响应中添加一些标题来对浏览器说“您可以从自己那里获取数据/代码”。
-
同源政策与跨源资源共享
来自维基百科: 要发起跨源请求,浏览器发送带有源HTTP标头的请求。这个标题的值是为页面服务的站点。例如,假设http://www.example-social-network.com上的一个页面试图访问online-personal-calendar.com中的用户数据。如果用户的浏览器实现了CORS,则将发送以下请求头: 来源:http://www.example-social-network
-
kafka 有几种数据保留的策略?
本文向大家介绍kafka 有几种数据保留的策略?相关面试题,主要包含被问及kafka 有几种数据保留的策略?时的应答技巧和注意事项,需要的朋友参考一下 kafka 有两种数据保存策略:按照过期时间保留和按照存储的消息大小保留。
-
在PassportJS中使用多种本地策略
问题内容: 我正在尝试对PassportJS使用多种本地策略。我不尝试使用本地,facebook和gmail等。我将两组用户存储在单独的对象中,并且我想使用本地策略对两者进行身份验证。就目前而言,我不能对两者使用相同的本地策略,因为它们具有不同的对象属性,这使我查询不同的对象。有什么办法吗?或对此的任何建议将不胜感激。 问题答案: 我认为这是不可能的,因为据我所知,您需要一种在第一个策略失败时将请
-
log4j2中基于时间的触发策略
我正在尝试创建每小时的新日志文件。我正在RollingFileAppender中使用lo4j2的TimeBasedTriggerringPolicy。下面是我从log4j2官方站点获取的示例xml配置代码。 在interval属性中,我设置了1表示1小时。但我的文件并不是每隔1小时滚动一次。
-
Volley框架的更改重定向策略
我在一个项目中使用Volley框架,我总是需要自己处理重定向以处理标头。 如何处理重定向现在取决于方法和传输层。我希望使用默认的截取(自动选择传输层),而不更改任何截取代码。 一个有效的解决方案是始终使用OkHttp作为传输层(如Volley的问题和贡献中所述),但我想知道是否有一种方法不需要额外的框架。 因此,我正在寻找一种“干净”的方法来禁用自动重定向处理。 编辑: 我更喜欢使用OkHttp,
-
如何添加内容安全策略(CSP)
我想使用javascript访问一个网站。但我在控制台中遇到以下错误。 拒绝连接到'https://example.com'因为它违反了以下内容安全策略指令:“default src'self'”。请注意,未显式设置“connect src”,因此使用“default src”作为回退。 我在index.html中添加了以下meta标记, 元超文本传输协议-Equiv="内容-安全-策略"内容="