《决策树》专题
-
使用java就餐simphony中的代理决策使用大量内存
我正在建立一个有许多自治代理的模型。他们决定在他们的直接环境或“邻里”中选择哪个目标。他们这样做是为了检索对象,将它们添加到列表中,根据首选项对列表进行排序,并在每次迭代中选择首选项。这个决定决定了他们的行动。 不幸的是,一旦特工人数过多,该计划就会大幅放缓。 我使用比较方法(下图),它相对较短,但使用大量内存来比较对象。我想知道你们是否知道任何其他方法可能在计算上更有效?
-
安全命名空间配置 - 默认的访问决策管理器
这一章节假设你有一些Spring Security中访问控制的底层架构的知识。如果没有,你可以跳过他,后面再来看,这部分针对那些真正需要进行一些定制而不是简单的基于角色的安全的用户。 当你使用命名空间配置时,一个AccessDecisionManager实例将会被自动创建并注册用来按照你在intercept-url和protect-pointcut(还有如果你使用了方法注解安全也包含在内)定义的访
-
 机械专业转算法岗位(百度Apollo决策规划面试)
机械专业转算法岗位(百度Apollo决策规划面试)Coding: 三道算法题。。。 这就是Apollo么 如何寻找二次曲线(离散的点连成的)的最小值 迷宫问题 二叉搜索树 技术面 我的项目是:使用PPO水了一篇文章;复现了IMPALA算法;熟悉一些强化学习算法 基本的强化学习算法:DQN系列,PPO,On-Policy Off-Policy等,问的很深 文章中的强化学习建模(状态、动作、奖励函数等),网络结构 对于A*的了解么?Hybrid A*
-
为什么带有一棵树的随机森林比决策树分类器好得多?
问题内容: 我通过图书馆学习机器学习。我使用以下代码将决策树分类器和随机森林分类器应用于我的数据: 为什么对于随机森林分类器来说结果要好得多(对于100次运行,随机采样2/3的数据进行训练,而1/3的数据进行测试)? 具有一个估计量的随机森林估计量不仅仅是决策树吗?我做错了什么或误解了这个概念吗? 感谢您的回复。 问题答案: 具有一个估计量的随机森林估计量不仅仅是决策树吗? 好吧,这是一个好问题,
-
4. 策略 - 4.3 常用的策略事件
OnStrategyStart – 在策略启动时调用,在第一笔行情到达之前 OnStrategyStop – 在策略结束时调用,在最后一笔行情之后 OnBarOpen – 在Bar行情最前沿调用(如,在日线数据开盘时买入) OnBar – 在所有行情的后沿调用(如,在日线数据收盘时买入) OnPositionOpened – 当一个新的交易开仓确认后调用 OnPositionChanged – 当
-
4. 策略 - 4.1 开始第一个策略
Solution:解决方案 Project:项目 一个解决方案下可以有多个项目,但是只有一个启动项 双击cs文件可以打开编辑代码 新建策略 在菜单栏File->New->Solution,新建一个解决方案 选择新建SmartQuant Instrument Strategy Solution模式的解决方案 Solution的类型 说明 SmartQuant Instrument Strategy
-
如何使用drools中的决策表实现小于和大于规则?
我想使用决策表实现基于流口水中较少和较大值的简单规则。 在drl中实现规则非常简单,例如: 但是我怎样才能把它翻译成流口水的决策表呢?到目前为止,我看到的所有例子都是在条件单元格中进行比较。甚至可以在值单元格中进行比较吗? 我看到的所有示例的格式如下: 但这只适用于1条规则,执行以下操作完全有不同的含义: 甚至可以执行以下操作吗? 实施这些规则的正确方式是什么?
-
如何使用决策器终止Spring批次分割流中的步骤
我在Spring Batch中发现了以下设计缺陷。 步骤必须具有Next属性,除非它是拆分流的最后一步或最后一步。 决定器块必须处理决定器返回的所有情况。 因此,在分割流中,最后一步不会有下一个属性,如果有决策者保护它,那么它必须有下一个属性。所以它不应该有这个属性,但它也需要它。第22条。 示例: 这似乎是Spring的人会想到的,所以很好奇,实现这一点的正确、非黑客方式是什么。谢谢
-
已解决-从Java Spring写入Angular 9套接字-被CORS策略阻止
我遇到了一个问题,试图在Angular 9应用程序中打开SockJS套接字,并使用SimpMessageTemboard从Spring后端写入此套接字。此任务的主要目标是实时接收和显示传入数据,而不进行外轮询。 我的原始实现基于mouadelfakir完成的现有存储库,但实现使用了较旧版本的软件(Angular~1和Spring Boot~1.5)。当更新到新版本时,Angular 9更新没有改变
-
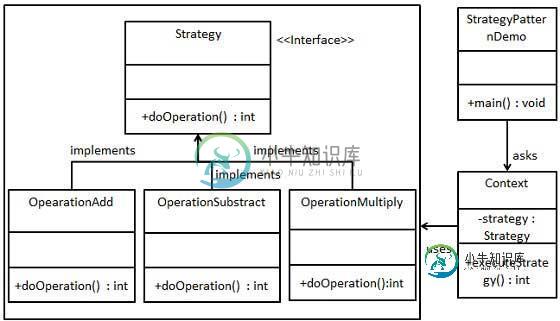 策略模式
策略模式主要内容:介绍,实现,Strategy.java,OperationAdd.java,OperationSubtract.java,OperationMultiply.java,Context.java,StrategyPatternDemo.java在策略模式(Strategy Pattern)中,一个类的行为或其算法可以在运行时更改。这种类型的设计模式属于行为型模式。 在策略模式中,我们创建表示各种策略的对象和一个行为随着策略对象改变而改变的 context 对象。策略对象改变 contex
-
隐私政策
引言 小牛知识库(以下或称“我们”)非常重视您的隐私保护,您在使用我们的业务平台(xnip.cn)的产品和服务时,我们可能会收集和使用您的相关信息。我们希望通过本《隐私政策》向您说明,我们如何收集、使用、存储及共享您的个人信息,以及您如何访问、更新、控制和保护您的个人信息。 本《隐私政策》与您使用我们的服务关系紧密,希望您仔细阅读并理解,做出您认为适当的选择。您使用或继续使用我们的服务,即意味着您
-
测试策略
Ansible Playbooks 的集成测试 很多时候, 人们问, “我怎样才能最好的将 Ansible playbooks 和测试结合在一起?” 这有很多选择. Ansible 的设计实际上是一个”fail-fast”有序系统, 因此它可以很容易地嵌入到 Ansible playbooks. 在这一章节, 我们将讨论基础设施的集成测试及合适的测试等级. Note 这是一个关于测试你部署应用程序
-
ElementTree Iterparse策略
问题内容: 我必须处理足够大(最大1GB)的xml文档,并使用python解析它们。我正在使用iterparse()函数(SAX样式解析)。 我关注的是以下内容,假设您有一个像这样的xml 问题是,当然知道我何时获得姓氏(如辛普森一家)以及何时获得该家庭成员之一的姓名(例如荷马) 到目前为止,我一直在使用“开关”,它会告诉我是否在“成员”标签中,代码看起来像这样 这很好,因为输出是 我担心的是,在
-
骆驼政策
我有一条小路线,我想使用自定义的重新传递策略来重复向endpoint发送消息,但这种行为非常奇怪。看起来,重新交付政策只是在重复一个错误。我试图将所有交换发送到路由的开头,但策略不起作用,因为每次都在创建: 我做错了什么?当错误发生时,我想以间隔重复我的请求。我的骆驼版本是2.6 日志:
-
SAML NameId政策
我是单点登录 (SSO) 概念的新手。我开始知道 SAML 请求和响应是实现 SSO 过程的最佳方式。然后我开始阅读有关SAML2.0的内容。我在 saml2.0 中发现了一个术语 NameIdPolicy,这在 saml1.0 中是不存在的。 定义说这是我们从IdP请求的NameID的格式,我想知道该格式是什么?我的意思是来自IDP的哪些数据应该以NameIDPolicy指定的格式出现?任何人都