《决策树》专题
-
IAM策略变量
我对策略变量${aws: username}感到困惑,即它是我在AWS帐户中登录的IAM用户名,还是我在创建实例时手动输入的标记值。 实际上,我想实现ec2实例的唯一所有者应该是执行操作
-
Kafka保留政策
假设我有一个多代理(运行在同一主机上)的Kafka设置,其中有3个代理和50个主题,每个主题配置为有7个分区和3个复制因子。 我有50GB的内存要用于kafka,并确保kafka日志永远不会超过这个内存数量,因此我想配置我的保留策略以防止这种情况。 我已设置删除清理策略: 我应该如何配置上述参数,以便每7天删除一次数据,并确保如果需要,可以在较短的窗口中删除数据,这样我就不会耗尽内存?
-
7.3 同源策略
同源策略 上一节介绍 CSP 时,我们提到了浏览器的同源策略,同源策略是 Web 安全的基础,它对从一个源加载的资源如何与来自另一个源的资源进行交互做出了限制。这是一个用于隔离潜在恶意文件的关键安全机制,每个源均与其他网络保持隔离,从而为开发者提供一个可进行构建和操作的安全沙盒。 如果没有同源策略,Web 世界就变得非常不安全,拿浏览器中的 cookie 来说,当你登录 A 网站,同时打开 B 网
-
3.2.2 对齐策略
要实现完美的多分辨率适配效果,UI 元素按照设计分辨率中规定的位置呈现是不够的,当屏幕宽度和高度发生变化时,UI 元素要能够智能感知屏幕边界的位置,才能保证出现在屏幕可见范围内,并且分布在合适的位置。我们通过 Widget(对齐挂件) 来实现这种效果。 下面我们根据要对齐元素的类别来划分不同的对齐工作流: 需要贴边对齐的按钮和小元素 对于暂停菜单、游戏金币这一类面积较小的元素,通常只需要贴着屏幕边
-
用户ID策略
1. 用户ID模型 用户ID(即UID)非系统生成,而是由业务方通过调用分析云提供的“setuserid” 接口传入的用户标识码。通常会建议业务方将用户的登录账户名称等业务方自有账户体系的用户唯一标识码作为用户ID 上传。 相比于设备ID是对设备进行标识,用户ID更倾向于基于业务的账户体系对用户进行标识与管理。因此,用户ID模型更适用于当您关注同一个账户在不同设备甚至不同平台的数据分析时,且对于用
-
9.1. 三种策略
Hibernate 支持三种基本的继承映射策略: 每个类分层结构一张表(table per class hierarchy) table per subclass 每个具体类一张表(table per concrete class) 此外,Hibernate 还支持第四种稍有不同的多态映射策略: 隐式多态(implicit polymorphism) 对于同一个继承层次内的不同分支,可以采用不同的
-
10.2. 安全策略
在这个世界上没有绝对的安全,我们说这台服务器安全并不是说它绝对不会有安全风险,不会受到损害。只能说明该台服务器的安全可信度高,不易受到侵害。相反,如果我们说这台服务器不安全,即可信度低,则这台服务器可能是一些服务的配置有安全漏洞或没有做数据冗余。每种环境、每种应用的可信度要求是有不同的,不能一概而论,如作为企业中心数据库服务器的可信度要求就比内部WEB服务器的可信度要求高。需投入更多的资金和时间对
-
Pod安全策略
PodSecurityPolicy 类型的对象能够控制,是否可以向 Pod 发送请求,该 Pod 能够影响被应用到 Pod 和容器的 SecurityContext。 查看 Pod 安全策略建议 获取更多信息。 什么是 Pod 安全策略? Pod 安全策略 是集群级别的资源,它能够控制 Pod 运行的行为,以及它具有访问什么的能力。 PodSecurityPolicy对象定义了一组条件,指示 Po
-
3.10.4 对齐策略
要实现完美的多分辨率适配效果,UI 元素按照设计分辨率中规定的位置呈现是不够的,当屏幕宽度和高度发生变化时,UI 元素要能够智能感知屏幕边界的位置,才能保证出现在屏幕可见范围内,并且分布在合适的位置。我们通过 Widget(对齐挂件) 来实现这种效果。 下面我们根据要对齐元素的类别来划分不同的对齐工作流: 需要贴边对齐的按钮和小元素 对于暂停菜单、游戏金币这一类面积较小的元素,通常只需要贴着屏幕边
-
5. 策略模式
5.1. 模式动机 完成一项任务,往往可以有多种不同的方式,每一种方式称为一个策略,我们可以根据环境或者条件的不同选择不同的策略来完成该项任务。 在软件开发中也常常遇到类似的情况,实现某一个功能有多个途径,此时可以使用一种设计模式来使得系统可以灵活地选择解决途径,也能够方便地增加新的解决途径。 在软件系统中,有许多算法可以实现某一功能,如查找、排序等,一种常用的方法是硬编码(Hard Coding
-
Tea-用户策略
为了提高语言实用性,Tea将用户分为普通用户和高级用户。 普通用户主要开发业务功能,他们更关心代码的开发效率、易读性和稳定性。 高级用户主要开发底层框架,他们更关心代码的运行效率、可重用性和可扩展性。 Tea 语言提高了大量技术以支持底层开发,但普通用户仍然可以在不了解这些技术的情况下完成任务。 对于普通用户,需要学习的知识有: 变量和函数定义 逻辑语句和常用表达式 简单的面向对象能力。 对于高级
-
Spring批处理重试策略和跳过策略问题
我有以下步骤在批处理工作。 当某个异常抛出时,我在parseStepSkipListener中捕捉他并登录数据库。 我期待以下行为: 作业已启动 执行前面的步骤 开始执行解析步骤 阅读项目 进程项 写 哦,异常。 捕获异常,登录数据库,转到下一个块(读取、处理、写入)。 作业已启动 执行前面的步骤 开始执行解析步骤 阅读项目 进程项 写 哦,异常。 进程项 写入项 哦,异常。 捕获异常,登录数据库
-
AWS访问策略评估不允许放置bucket策略
我已将以下策略附加到IAM用户: 现在,有了附加了上述策略的IAM用户的访问凭据,我试图运行以下命令: 其中,文件policy.json的内容为: 我得到了一个 调用PutBucket策略操作时发生错误(AccessDended):拒绝访问 现在我想知道为什么? 用户的策略语句允许对资源执行: 这就是我试图用我的上述政策所做的。那么,为什么访问被拒绝?
-
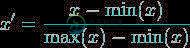 输入特征归一化有哪些方式,有什么好处。svm需不需要?决策树需不需要?
输入特征归一化有哪些方式,有什么好处。svm需不需要?决策树需不需要?本文向大家介绍输入特征归一化有哪些方式,有什么好处。svm需不需要?决策树需不需要?相关面试题,主要包含被问及输入特征归一化有哪些方式,有什么好处。svm需不需要?决策树需不需要?时的应答技巧和注意事项,需要的朋友参考一下 1.归一化可以加快梯度下降法求解最优解的速度。 当特征之间的数值变化范围相差太大时,会使得收敛路径呈Z字型,导致收敛太慢,或者根本收敛不到最优解的结果。 2.归一化可以提高计算
-
CPLEX Python API如何将决策变量与目标函数中的虚拟变量相乘?
我试图在目标函数中加入变量的乘法。我有一个整数x_t,还有一个二进制变量w_t_1。我想在目标函数中有-1200*w\u t\u 1*x\u t。我怎么做?我在IBM文档中找不到任何东西。