《scala》专题
-
从Java / Scala实例化Rhinoscript本机物件
问题内容: 我正在尝试提高 javascript代码段评估程序 的性能。这些脚本片段可以引用存在于类似json的对象图的字符串键映射中的任意数量的变量(IE:Json AST)。我正在使用JDK 1.6和嵌入式Rhinoscript引擎(v1.6R2)。 当前,处理采用以下形式: 分析代码段以发现引用变量的名称 从映射中检索变量并将其序列化为json字符串 在脚本开始时,将Json字符串分配给名称
-
Scala错误:在Scala IDE和Eclipse中都找不到或加载主类
问题内容: 这是我的问题,我知道类似问题有很多答案,但是在我尝试过之后,这些问题都没有解决。我同时使用Scala IDE 4.6和 eclipse Oxygen来运行代码,但均因该错误而失败。 从在线答案来看,我已经尝试在构建之前清理项目,还尝试了所有版本的JVM和Scala编译器,所有这些都无济于事。 该代码是直接从在线课程代码中导入的,因此我认为代码中不应有任何错误。 问题答案: 我认为这应该
-
为什么Scala列表没有size字段?
问题内容: 来自Java背景,我想知道为什么Scala中没有类似Java 的字段。毕竟,使用size字段,您将能够确定时间的列表大小,那么为什么size字段被删除了? (此问题涉及Scala 2.8及更高版本中的新集合类。此外,我指的是不可变的,而不是可变的。) 问题答案: 不能说size字段已被 删除 ,因为LISP自LISP以来已经存在了50年,这种列表无处不在,并且它们在ML和Haskell
-
如何使用scala.Java代码中没有一个[重复]
问题内容: 这个问题已经在这里有了答案 : 7年前关闭。 可能重复: 从Java访问scala.None 在Java中,您可以使用构造函数创建一个实例,即,但没有伙伴类。如何从Java 传递给Scala函数? 问题答案: 我认为这个丑陋的方法会起作用: 不需要新实例,因为一个实例与另一个实例一样好…
-
Maven:在一个项目中混合Java和Scala
问题内容: 今天,我一直在尝试寻找一个合适的解决方案来建立一个既包含Java代码又包含Scala代码(它们之间具有双向依赖性)的maven项目。 我发现的解决方案通常包括在该阶段调用scala-maven-plugin或maven-scala- plugin,以便它在默认的maven编译器插件之前运行(示例:http : //www.hascode.com/2012/03 /片段混合- 斯卡拉的J
-
您如何从Java调用Scala对象?
问题内容: Java代码: Scala代码: 命令行: 问题答案: 我将从使用java.util.Timer开始,而不是从javax.swing.Timer开始。除非您使用GUI运行应用程序,否则swing计时器将不起作用(即,如果您在没有特殊命令行参数的情况下通过控制台在Linux上运行它,则它将不起作用- 最好避免)。 放在一边: 请确保在尝试运行代码时,在类路径中包含scala-librar
-
如何在同一个Spark项目中同时使用Scala和Python?
问题内容: 可以将 Spark RDD 通过管道传输到Python吗? 因为我需要一个python库来对数据进行一些计算,但是我的主要Spark项目基于Scala。有没有办法将两者混合使用或让python访问相同的spark上下文? 问题答案: 实际上,您可以使用Scala和Spark以及常规Python脚本来传递到python脚本。 test.py 火花壳(scala) 输出量 你好约翰 你好林
-
spark,scala和jdbc-如何限制记录数
问题内容: 有没有一种方法可以限制使用spark sql 2.2.0从jdbc源获取的记录数? 我正在处理将一个大于200M的记录从一个MS Sql Server表移动(和转换)到另一个MS Sql表的任务: 在工作的同时,很明显,它首先要从数据库中加载所有200M条记录,首先要花18分钟的时间,然后将我希望用于测试和开发目的的有限数量的记录返回给我。 在take(…)和load()之间切换会产生
-
Scala解析Json字符串的实例详解
本文向大家介绍Scala解析Json字符串的实例详解,包括了Scala解析Json字符串的实例详解的使用技巧和注意事项,需要的朋友参考一下 Scala解析Json字符串的实例详解 1. 添加相应依赖 Json解析工具使用的 json-smart,曾经对比过Java的fastjson、gson。Scala的json4s、lift-json。其中 json-smart 解析速度是最快的。
-
 Jupyter notebook运行Spark+Scala教程
Jupyter notebook运行Spark+Scala教程本文向大家介绍Jupyter notebook运行Spark+Scala教程,包括了Jupyter notebook运行Spark+Scala教程的使用技巧和注意事项,需要的朋友参考一下 今天在intellij调试spark的时候感觉每次有新的一段代码,都要重新跑一遍,如果用spark-shell,感觉也不是特别方便,如果能像python那样,使用jupyter notebook进行编程就很方便了
-
浅谈Scala模式匹配
本文向大家介绍浅谈Scala模式匹配,包括了浅谈Scala模式匹配的使用技巧和注意事项,需要的朋友参考一下 一.scala模式匹配(pattern matching) pattern matching可以说是scala中十分强大的一个语言特性,当然这不是scala独有的,但这不妨碍它成为scala的语言的一大利器。 scala的pattern matching是类似这样的, 其中,变量e后面接一个
-
Scala函数式编程专题--scala集合和函数
本文向大家介绍Scala函数式编程专题--scala集合和函数,包括了Scala函数式编程专题--scala集合和函数的使用技巧和注意事项,需要的朋友参考一下 前情提要: Scala函数式编程专题—— 函数式思想介绍 scala函数式编程专题——scala基础语法介绍 前面已经稍微介绍了scala的常用语法以及面向对象的一些简要知识,这次是补充上一章的,主要会介绍集合和函数。 注意噢,函数和方法是
-
Spark Streaming Kafka with Java11 scala代码问题
我在JDK 11中使用scalaSpark Streaming Kafka。但是我得到了下面的错误。 线程“main”java中出现异常。lang.NoSuchMethodError:scala。Predef美元。refArrayOps([Ljava/lang/Object;)Lscala/collection/mutable/ArrayOps; 下面是我正在使用的代码。 下面是我的pom。xml
-
如何在Eclipse中将Scala库打包到可运行的jar中
我在使用Scala在Eclipse中创建一个可运行的jar文件时遇到了一些麻烦。 在Eclipse中,我有一个Scala项目,我希望将其变成一个可运行的jar文件。当我运行jar文件时,它找不到Scala标准库。 IDE-我正在使用Scala IDE扩展Eclipse以适应Scala的使用。 Setup-要导出,右键单击我的项目并向下导航export>Runnable Jar文件。我选择运行配置并
-
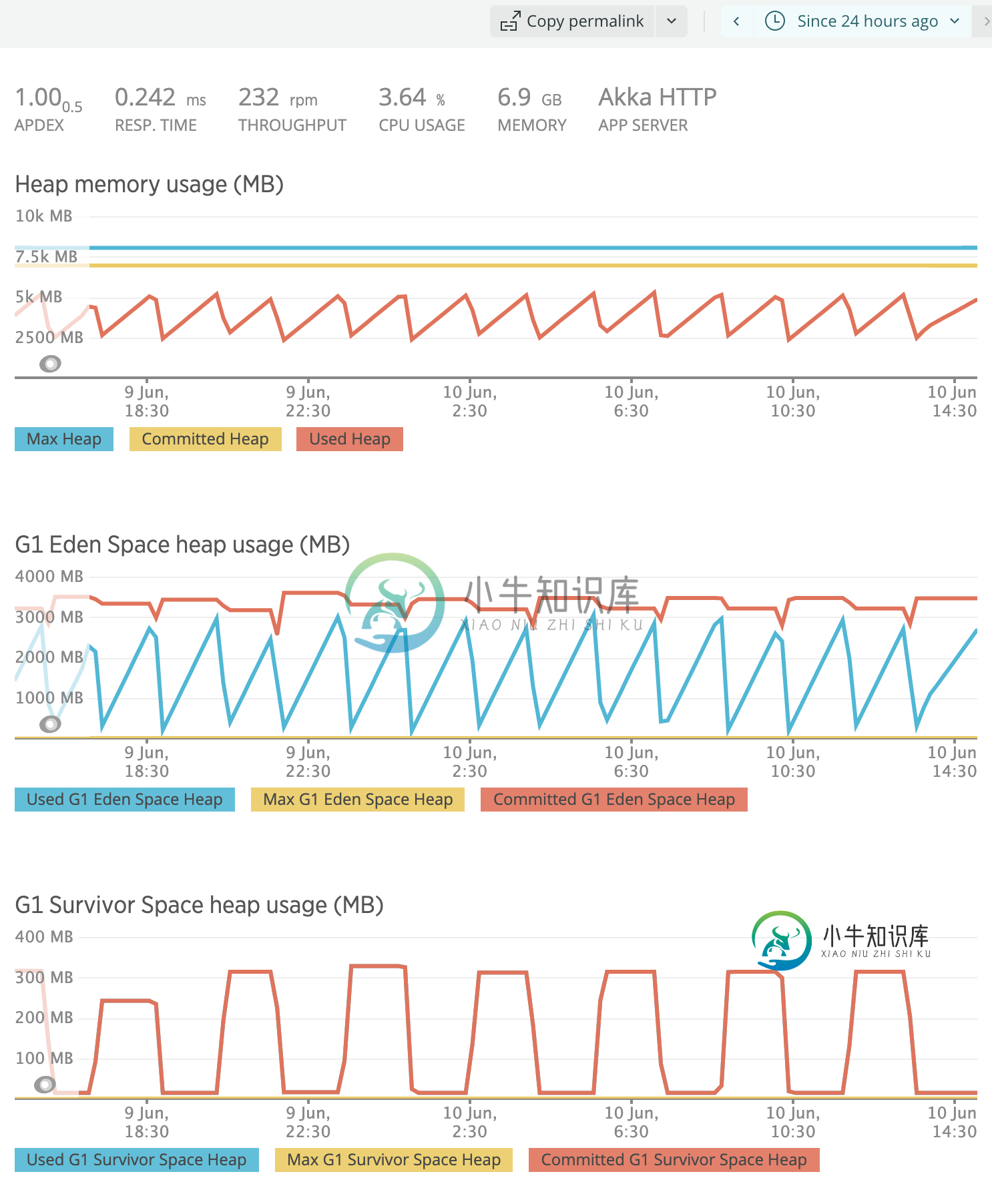 Akka http scala服务中的Zig-zag堆内存模式
Akka http scala服务中的Zig-zag堆内存模式我有一个基于AKKA-HTTP的服务,它是用Scala编写的。此服务用作API调用的代理。它使用https://doc.akka.io/docs/akka-http/current/client-side/host-level.html创建一个用于调用API的主机连接池 我想了解这种“之”字形模式的原因,即使服务上没有流量,并且主机池中的连接由于空闲超时而终止。 此外,我还想知道,是否只有在达到一