
Jupyter notebook运行Spark+Scala教程

今天在intellij调试spark的时候感觉每次有新的一段代码,都要重新跑一遍,如果用spark-shell,感觉也不是特别方便,如果能像python那样,使用jupyter notebook进行编程就很方便了,同时也适合代码展示,网上查了一下,试了一下,碰到了很多坑,有些是旧的版本,还有些是版本不同导致错误,这里就记录下来安装的过程。
1.运行环境
硬件:Mac
事先装好:Jupyter notebook,spark2.1.0,scala 2.11.8 (这个版本很重要,关系到后面的安装)
2.安装
2.1.scala kernel
从github下载
git clone https://github.com/jupyter-scala/jupyter-scala.git
进入下载的jupyter-scala目录下,运行
bash jupyter-scala
然后查看
jupyter kernelspec list

表示scala已经嵌入到jupyter notebook
2.2.spark kernel
这个也比较好装,但是要注意版本问题,我们用的是toree来装的,首先要安装toree
网上的教程通常直接
pip install toree
但是这个下载的是0.1.0版本,该版本的话问题是,后面装spark kernel后,在jupyter运行spark的时候,默认选的是scala2.10.4版本,会有以下的错误
[I 03:15:16.677 NotebookApp] Kernel started: 94a63354-d294-4de7-a12c-2e05905e0c45
Starting Spark Kernel with SPARK_HOME=/usr/local/spark
16/11/20 03:15:18 [INFO] o.a.t.Main$$anon$1 - Kernel version: 0.1.0.dev8-incubating-SNAPSHOT
16/11/20 03:15:18 [INFO] o.a.t.Main$$anon$1 - Scala version: Some(2.10.4)
16/11/20 03:15:18 [INFO] o.a.t.Main$$anon$1 - ZeroMQ (JeroMQ) version: 3.2.2
16/11/20 03:15:18 [INFO] o.a.t.Main$$anon$1 - Initializing internal actor system
Exception in thread "main" java.lang.NoSuchMethodError: scala.collection.immutable.HashSet$.empty()Lscala/collection/immutable/HashSet;
at akka.actor.ActorCell$.<init>(ActorCell.scala:336)
at akka.actor.ActorCell$.<clinit>(ActorCell.scala)
at akka.actor.RootActorPath.$div(ActorPath.scala:185)
at akka.actor.LocalActorRefProvider.<init>(ActorRefProvider.scala:465)
at akka.actor.LocalActorRefProvider.<init>(ActorRefProvider.scala:453)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.html" target="_blank">java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at akka.actor.ReflectiveDynamicAccess$$anonfun$createInstanceFor$2.apply(DynamicAccess.scala:78)
at scala.util.Try$.apply(Try.scala:192)
at akka.actor.ReflectiveDynamicAccess.createInstanceFor(DynamicAccess.scala:73)
at akka.actor.ReflectiveDynamicAccess$$anonfun$createInstanceFor$3.apply(DynamicAccess.scala:84)
at akka.actor.ReflectiveDynamicAccess$$anonfun$createInstanceFor$3.apply(DynamicAccess.scala:84)
at scala.util.Success.flatMap(Try.scala:231)
at akka.actor.ReflectiveDynamicAccess.createInstanceFor(DynamicAccess.scala:84)
at akka.actor.ActorSystemImpl.liftedTree1$1(ActorSystem.scala:585)
at akka.actor.ActorSystemImpl.<init>(ActorSystem.scala:578)
at akka.actor.ActorSystem$.apply(ActorSystem.scala:142)
at akka.actor.ActorSystem$.apply(ActorSystem.scala:109)
at org.apache.toree.boot.layer.StandardBareInitialization$class.createActorSystem(BareInitialization.scala:71)
at org.apache.toree.Main$$anon$1.createActorSystem(Main.scala:35)
at org.apache.toree.boot.layer.StandardBareInitialization$class.initializeBare(BareInitialization.scala:60)
at org.apache.toree.Main$$anon$1.initializeBare(Main.scala:35)
at org.apache.toree.boot.KernelBootstrap.initialize(KernelBootstrap.scala:72)
at org.apache.toree.Main$delayedInit$body.apply(Main.scala:40)
at scala.Function0$class.apply$mcV$sp(Function0.scala:34)
at scala.runtime.AbstractFunction0.apply$mcV$sp(AbstractFunction0.scala:12)
at scala.App$$anonfun$main$1.apply(App.scala:76)
at scala.App$$anonfun$main$1.apply(App.scala:76)
at scala.collection.immutable.List.foreach(List.scala:381)
at scala.collection.generic.TraversableForwarder$class.foreach(TraversableForwarder.scala:35)
at scala.App$class.main(App.scala:76)
at org.apache.toree.Main$.main(Main.scala:24)
at org.apache.toree.Main.main(Main.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:736)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:185)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:210)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:124)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
[W 03:15:26.738 NotebookApp] Timeout waiting for kernel_info reply from 94a63354-d294-4de7-a12c-2e05905e0c45
这个错误太可怕了,就是版本不对,因为spark2.1.0对应的是scala2.11版本的
所以要用下面的方式下载0.2.0版本
pip install https://dist.apache.org/repos/dist/dev/incubator/toree/0.2.0/snapshots/dev1/toree-pip/toree-0.2.0.dev1.tar.gz
后面就可以安装spark kernel了
jupyter toree install --interpreters=Scala --spark_home=/usr/local/Cellar/apache-spark/2.1.0/libexec --user --kernel_name=apache_toree --interpreters=PySpark,SparkR,Scala,SQL
其中spark_home指的是你的spark的安装目录,记住这个安装目录必须到spark中有python之前,比如我的spark中的python(spark中的python文件夹,不是我们自己装的那个)在 /usr/local/Cellar/apache-spark/2.1.0/libexec
查看结果
jupyter kernelspec list

安装成功
3.打开jupyter notebook查看效果
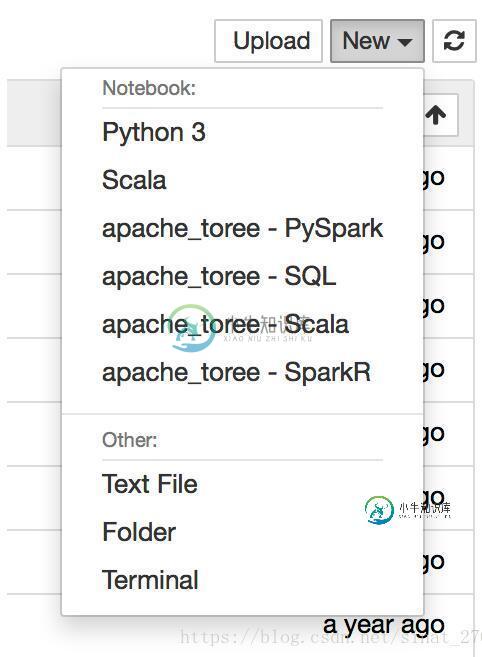
有这么多选项,可以快乐的用jupyter notebook进行spark了
以上这篇Jupyter notebook运行Spark+Scala教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
输入DF: 我试图找到运行时间戳的差异就main_id 输出DF: 已尝试的代码: 我得到的差异函数的错误,有一种方法来实现这一点。任何建议请。
-
我在网上搜索并找到了以下资源,我尝试了这些资源(请参见pom),但无法工作: 1)Spark用户邮件列表:http://apache-spark-user-list.1001560.n3.nabble.com/packaging-a-spark-job-using-maven-td5615.html 2)如何打包spark scala应用程序 我有一个简单的例子来演示这个问题,一个简单的1类项目(
-
我有一个以下数据(alldata),它有SQL查询和视图名称。 我已经拆分并正确地将其分配给诱惑(alldata) 当我尝试执行查询并从中注册tempview或表时,它显示空指针错误。但是当我注释掉spark时,PRINTLN显示了表中的所有值。sql语句。 但是当我用spark.sql执行它时,它会显示以下错误,请帮助我出错的地方。 19/12/09 02:43:12错误执行器:在阶段4.0任务
-
主要内容:谁适合阅读本教程?,学习本教程前你需要了解,第一个 Scala 程序:Hello World,实例(HelloWorld.scala),相关文档推荐Scala 是一门多范式(multi-paradigm)的编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性。 Scala 运行在 Java 虚拟机上,并兼容现有的 Java 程序。 Scala 源代码被编译成 Java 字节码,所以它可以运行于 JVM 之上,并可以调用现有的 Java 类库。 谁适合阅读本教程? 本教程适合想从
-
Scala 是一门多范式(multi-paradigm)的编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性。 Scala 运行在Java虚拟机上,并兼容现有的Java程序。 Scala 源代码被编译成Java字节码,所以它可以运行于JVM之上,并可以调用现有的Java类库。 谁适合阅读本教程? 本教程适合想从零开始学习 Scala 编程语言的开发人员。当然本教程也会对一些模块进行深入,
-
大家好,堆栈溢出。今天,我想问一些非常不同的问题。 我目前是一名数据科学家,我在JupyterLab/笔记本上做了很多工作。我的几个同事用笔记本电脑代替了JupyterLab。看起来这两者之间并没有太大区别(我真的很喜欢JupyterLab以不同的颜色呈现代码的方式)。我在网上搜索过,上面写着 "JupyterLab是下一代的Jupyter笔记本" 然而,一些特写,如情节人物,在JupyterLa