《xpath》专题
-
像Xpath一样查询嵌套的python字典
问题内容: 有没有一种方法可以为嵌套的python字典定义XPath类型查询。 像这样: 我还需要选择嵌套列表;) 这可以通过@jellybean的解决方案轻松完成: [EDIT 2016]这个问题和公认的答案都是古老的。更新的答案可能比原始答案做得更好。但是,我没有测试它们,所以我不会更改已接受的答案。 问题答案: 并不完全漂亮,但是您可能会使用 当然,这不支持xpath之类的东西,例如索引……
-
如何在MySQL select中使用XPATH?
问题内容: 假设我有一个名为“ xml”的表,该表将XML文件存储在单列“数据”中。如何编写运行XPath并仅返回与该XPath匹配的行的MySQL查询? 问题答案: 但是,您应该注意,MySQL对XPath的支持存在局限性。 仅返回CDATA。 并非所有XPath构造都受支持。abatishchev的答案中提到的文档页面上“ XPath限制”标题下的详细信息。
-
Python3 xml.etree.ElementTree支持的XPath语法详解
本文向大家介绍Python3 xml.etree.ElementTree支持的XPath语法详解,包括了Python3 xml.etree.ElementTree支持的XPath语法详解的使用技巧和注意事项,需要的朋友参考一下 xml.etree.ElementTree可以通过支持的有限的XPath表达式来定位元素。 语法 ElementTree支持的语法如下: 语法 说明 tag 查找所有具有指
-
 python3 xpath和requests应用详解
python3 xpath和requests应用详解本文向大家介绍python3 xpath和requests应用详解,包括了python3 xpath和requests应用详解的使用技巧和注意事项,需要的朋友参考一下 根据一个爬取豆瓣电影排名的小应用,来简单使用etree和request库。 etree使用xpath语法。 程序运行结果: 补充知识:requests抓取以及Xpath解析 代码: 运行结果: 代码: 运行结果: 以上这篇pytho
-
关于python中的xpath解析定位
本文向大家介绍关于python中的xpath解析定位,包括了关于python中的xpath解析定位的使用技巧和注意事项,需要的朋友参考一下 爬取的网站:http://jbk.39.net/chancegz/ 这里只针对个别属性值: 补充其他: xpath基本语法 表达式 说明 article 选取所有article元素的所有子节点 /article 选取根元素article article/a 选
-
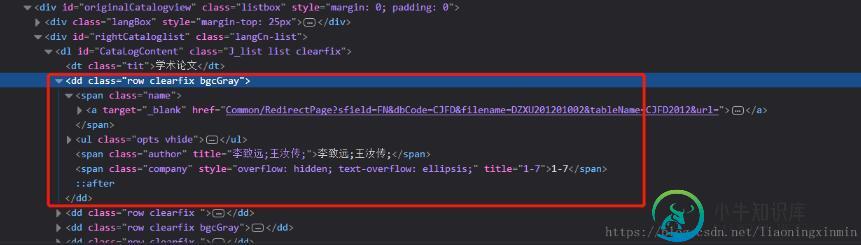 python-xpath获取html文档的部分内容
python-xpath获取html文档的部分内容本文向大家介绍python-xpath获取html文档的部分内容,包括了python-xpath获取html文档的部分内容的使用技巧和注意事项,需要的朋友参考一下 有些时候我在们需要的用正则提取出html中某一个部分的文字内容,如图: 获取dd部分的html文档,我们要通过它的一个属性去确定他的位置才可以拿到他这个部分我们可以看到他的这个属性class='row clearfix ',然后用xpa
-
php用xpath解析html的代码实例讲解
本文向大家介绍php用xpath解析html的代码实例讲解,包括了php用xpath解析html的代码实例讲解的使用技巧和注意事项,需要的朋友参考一下 实例1 实例2 以上就是相关的2个实例内容,以及相关的代码, 感谢大家对呐喊教程的支持。
-
在Ruby中处理XML和XSLT以及XPath的简单教程
本文向大家介绍在Ruby中处理XML和XSLT以及XPath的简单教程,包括了在Ruby中处理XML和XSLT以及XPath的简单教程的使用技巧和注意事项,需要的朋友参考一下 什么是 XML ? XML 指可扩展标记语言(eXtensible Markup Language)。 可扩展标记语言,标准通用标记语言的子集,一种用于标记电子文件使其具有结构性的标记语言。 它可以用来标记数据、定义数据类型
-
用XPath包络引用签名父节点的XML-Signature
也许here()函数([http://www.w3.org/tr/xmldsig-filter2/#function-here)可能会有帮助?我的建议是: 它从XPath-node开始(在链接中注意到),我沿着签名节点走到我的BBB-node,但这看起来很混乱。
-
WebDriver/PageObject/FindBy:如何使用动态值指定xpath?
我试图在Java中使用页面对象模式,并在@FindBy/XPath中遇到一些问题。 之前,我在Groovy中使用了以下构造: 现在,我想做同样的事情,但根据Java中的页面对象范式: 在我的测试中,我调用deleteSystem: 问题:如何链接为PlantSystemName和为deleteSystem指定的SystemName的@FindBy符号? 谢谢,浣熊
-
在Xpath中使用“AND”和“normalize space”时,在不同的浏览器中会出现不同的错误
我的网页上有以下简单的按钮- 作为类名有一个空格,所以我使用- 这是以正确的方式正常工作,但当我以这种方式使用时- 在中获取错误- 线程“main”组织中出现异常。openqa。硒。遥远的UnreachableBrowserException:与远程浏览器通信时出错。它可能已经死了。构建信息:版本:“未知”,版本:“1969d75”,时间:“2016-10-18 09:43:45-0700”系统信
-
如何通过lxml XPath从超文本标记语言中提取img src?
我试图使用python/lxml和命令提取图像URl,但在隔离url本身时遇到麻烦。 下面是我想要的围绕img的HTML: 具体来说,我想隔离<代码>https://photos.zillowstatic.com/p_h/IS2fordnekys6d1000000000.jpgurl。 我尝试了几种方法,但都没有成功,包括以下几种方法:
-
如何让Camel将Saxon用于xpath选择谓词?
在我用Talend 6.5构建的路由中,使用了Saxon 9.5 jar,因此所有XPath谓词都使用Saxon进行评估。 升级到Talend 7.1以使用较新的Camel版本后,现在使用的是saxon 9.8版本,我从中了解到(带有saxon的Apache Camel Xpath 2.0在RouteBuilder/Predicates中似乎不起作用),9.6不会自动使用。 理想情况下,我希望Ca
-
使用xpath比较两个DOM元素
现在我希望从基于id的XPath生成唯一的基于类的XPath。Firepath生成的类XPath可能指向多个元素,而不是唯一的。但是firepath生成的id XPath总是唯一的,即指向单个元素。 所以,我正在尽可能地生成两个之间的映射。但我需要测试以下内容: 以确保我创建的类xpath对应于所需的DOM元素。任何帮助都将得到高度赞赏。我希望生成的xpath示例是: 目标是减少xpath的深度,
-
python selenium xpath找不到元素
Selenium.Common.Exceptions.NosuChelementException:消息:没有这样的元素:找不到元素: