《xpath》专题
-
硒中的xpath是什么?
本文向大家介绍硒中的xpath是什么?,包括了硒中的xpath是什么?的使用技巧和注意事项,需要的朋友参考一下 Xpath是Selenium中用于识别Web元素的最重要的定位器之一。它以以下方式工作- 它借助元素及其属性(用于标识)在文档对象模型(DOM)中导航。 尽管它有助于唯一地定位元素,但从其他定位器来看,它的速度较慢。 xpath用两种方式表示,即“ /”和“ //”。正斜杠表示绝对路径。
-
如何在变量中的JSP中使用XPath表达式的值?
本文向大家介绍如何在变量中的JSP中使用XPath表达式的值?,包括了如何在变量中的JSP中使用XPath表达式的值?的使用技巧和注意事项,需要的朋友参考一下 <X:集>标签集以XPath表达式的值的变量。 如果XPath表达式的结果为布尔值,则<x:set>标记将设置一个java.lang.Boolean对象;否则,该值为false。对于字符串,java.lang.String; 以及一个数字,
-
我们可以在JSP中测试XPath表达式吗?
本文向大家介绍我们可以在JSP中测试XPath表达式吗?,包括了我们可以在JSP中测试XPath表达式吗?的使用技巧和注意事项,需要的朋友参考一下 <X:如果>标签计算一个测试XPath表达式,并且如果它是真实的,它处理它的身体。如果测试条件为假,则忽略主体。 属性 <X:如果>标签具有以下属性- 属性 描述 需要 默认 选择 要评估的XPath表达式 是 没有 变种 用于存储条件结果的变量名称
-
我们可以在JSP中使用XPath表达式的switch语句吗?
本文向大家介绍我们可以在JSP中使用XPath表达式的switch语句吗?,包括了我们可以在JSP中使用XPath表达式的switch语句吗?的使用技巧和注意事项,需要的朋友参考一下 在<X:选择>标签的运作方式类似于Java的switch语句。有了这个,您可以在多种选择之间进行选择。如果switch语句具有case语句,则<x:choose>标记具有<x:when>标记。以类似的方式,switc
-
通过XPath解析HTML
问题内容: 在.Net中,我发现了一个很棒的库HtmlAgilityPack,它使您可以使用XPath轻松解析格式不正确的HTML。我已经在.Net站点中使用了几年,但是我不得不为我的Python,Ruby和其他项目选择更痛苦的库。有人知道其他语言的类似库吗? 问题答案: 在python中,ElementTidy解析标记汤并生成一个元素树,该树允许使用XPath进行查询:
-
在ElementTree中使用XPath通过文本查找元素
问题内容: 给定如下所示的XML: 如何使用ElementTree及其对XPath的支持将元素与内容A匹配?谢谢 问题答案: AFAIK ElementTree不支持XPath。它改变了吗? 无论如何,您可以使用lxml和以下XPath表达式: 结果将是:
-
Xpath:检查节点是否不存在
我从我的网络商店API调用中获取XML,其结构非常像下面的示例: 其中有更多的参数,数量取决于许多外部因素。我正在尝试获取用户名,当id“111”和id“112”的值是我要查找的值时 上述代码按预期返回“userOne”和“userTwo”。 问题是,Id“111”要么有值“Param 1 is on”要么什么都没有,如果没有值,它就不会显示在XML中。所以我需要一个表达式来检查id为“111”的
-
 Java Selenium-使用xpath搜索未找到搜索的元素
Java Selenium-使用xpath搜索未找到搜索的元素这里有两个代码段,我正在使用它们从具有“From Date”和“To Date”的日历中搜索日期。 错误消息显示:线程“main”组织中出现异常。openqa。硒。NoSuchElementException:没有这样的元素:无法定位元素:{“method”:“xpath”,“selector”:“//table/tbody/tr/a[包含(text(),'十月三十日')]”“}
-
无法使用xpath在webDrive中查找元素
非常感谢您的帮助。 我想知道firebug复制xpath是否总是适用于webdriver。 我有一个带有列表的页面,我可以获得完整的xpath来查找前两个元素,但无法对3、4执行相同的操作。 对于第三个,它不起作用: 错误: org.openqa.selenium.NoSuchElementException:无法定位元素:{"method":"xpath","selector":"/html/b
-
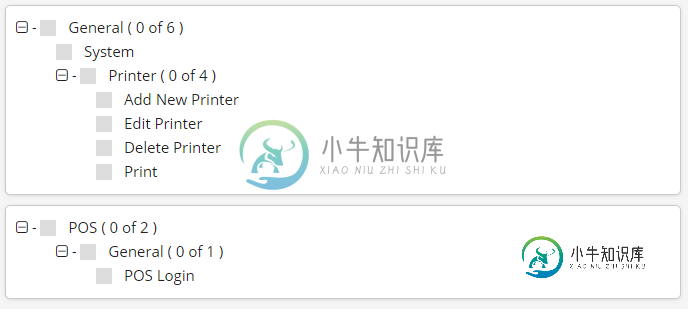 XPath索引选择器返回整个数组,而不是索引处的元素
XPath索引选择器返回整个数组,而不是索引处的元素出于某种原因,将索引放入XPath将返回整个对象数组,而不是索引处的对象数组 超文本标记语言 我正在研究的超文本标记语言如下所示: HTML的屏幕截图 我想做什么 我正试图根据复选框编写硒测试。选中叶复选框只应选中该叶复选框,选中父复选框还应选中子复选框。 我的XPath选择器 在该代码中,为了便于XPath选择器的编写,我在开发人员控制台中的一个字段上放置了一个ID。尤其是这个: 在包含所需内容
-
Selenium XPath-如何查找前一个元素
我在JavaSelenium中运行测试,在那里我找到一个元素,一旦找到就需要找到紧接在前的元素。代码需要是动态的,因为我不知道我开始的元素是5个中的第3个、10个中的第6个还是2个中的第1个。 问题是,使用xpath中的前置兄弟,我得到了找到的元素之前的所有元素,而不是紧接在它之前的元素。例如,这是我的xml: 假设我已经找到了作为WebElement的“Value 2”标签,那么我接下来要做的就
-
XPath'//div/跟随-兄弟::div'选择什么?
有一个xml,http://kquery.veryos.com/w3.xml 打开chrome开发工具,运行“文档”。控制台中的queryselectoral(“div ~ div”)'返回4292个元素。 但是使用XPath表达式等于css选择器“div ~ div”,不选择任何内容,不返回任何元素。 表达式“//div/后续同级::div”或“//div[之前同级::div]”有任何问题吗?
-
如何使用xpath获取以下文本名称?
我尝试使用以下xpath 但获取以下错误 “org.openqa.selenium.InvalidSelectorException:选择器无效:xpath表达式的结果”//div[包含(@class,'ReactTags\uu selected')]]//span[2]/text()“是:[对象文本]。它应该是元素。”
-
Selenium Webdriver-相对xpath
我是硒的初学者。我没有任何实践经验。上个月,我报名参加了硒初学者高级课程,在那里我几乎没有可以动手的活动。 我被困在某个地方。让我解释一下我的问题。 以下是活动描述: 相对论 URL:http://webapps.tekstac.com/Shopify/ 测试程序: 使用模板代码 不要在DriverSetup文件中进行任何更改 仅在建议的部分中,将代码添加到 使用DriverSetup()中定义的
-
Java(Eclipse)-Selenium-xpath-无法识别Web元素
我对硒很陌生。 我尝试构建一个测试来验证网页元素(小图标)是否显示在页面上。 因此,在我的类的顶部,我通过xpath定义了Web元素。 Xpath我在应用右键单击元素并单击检查后从检查中复制。 @通过(xpath=“//*[@id=”referrals“]/tbody/tr[2]/td[2]/div/img[2]”)私有WebElement链和twoarrowsicon查找; 然后在同一个类中,我