《xpath》专题
-
使用前后XPath选择器时返回null元素
我试图找到前面的元素(输入)使用Selenium驱动程序与Xpath选择器的帮助(我可以访问标签),它可以很好地使用Chrome开发工具-F12选项,但使用下面的代码行返回空。 我的实际HTML看起来像 有人能帮我吗?
-
如何使用Xpath for JavascriptExecitor(Selenium)编写webelement路径
正在尝试在Selenium WebDriver上编写自动测试。具有带有CSS定位器的页面上Webelement: 此外,还应采用以下工作方法聚焦该元素: 问题是如何做到这一点,但要使用xpath定位器。元素的xpath是//textarea[@id='FeedbackMessage']。 琐碎的用法 不工作
-
WebDriver忽略以下Xpath内容:
这是我的xpath: Selenium WebDriver代码忽略了上述xpath中::之后的所有内容。 下面是当我在上面使用xpath作为定位器来标识页面中的元素时,在selenium中遇到的错误。 关于如何让webdriver接受上面的整个xpath,有什么想法或建议吗? 下面是HTML代码: 以下是WebDriverJava代码: 元素是一个复选框,我试图通过应用方法来检查它。单击()。 下
-
需要使用xpath定位器标识值“SivaKumar”的web元素并返回它。使用相同的web元素,获取文本并返回它
我是硒的初学者。我在这方面没有任何实际经验。上个月,我注册了一门硒初学者到高级课程,在那里我几乎没有可以动手的活动。 我被困在某个地方。让我解释一下我的问题。 以下是活动描述: 相对定位符 URL:http://webapps.tekstac.com/Shopify/ 试验程序: 使用模板代码。不要在DriverSetup文件中进行任何更改。仅在建议的部分中添加代码,使用DriverSetup()
-
所有HTML节点到XPATH
我正在尝试将所有超文本标记语言节点转换为XPATH这是一个示例输入。基于超文本标记语言,我正在寻找所有子节点的所有XPATH 我想要的输出 我目前拥有的 代码 如果你们能给我指出正确的方向,任何帮助都会很好 我确实研究了Lxml bs4和硒,但不幸的是没有运气
-
无法通过xpath访问具有多个命名空间的xhtml文档中的节点
好的,我正在尝试用curl和xpath解析一个xhtml站点。 该网站有多个命名空间: 我试图从网站的分页中获取所有的网址,如下所示: 这不管用。(不带x名称空间的分页的xpath应该是正确的)。我应该注册所有名称空间并在xpath查询中以某种方式使用它们吗? 向你问好,AB //问题更新// 这是我试图解析的页面部分:(我想要href) doctype是: html PUBLIC“-//W3C/
-
尽管看起来相同的字符串,但Selenium网络驱动程序找不到XPATH
这个问题与我之前的两个问题有关:诱导WebDriver等待特定元素和刮擦中的不一致性 我正在把所有的Air Jordan运动鞋从鞋底上刮掉https://www.grailed.com/.feed是一个无限滚动的运动鞋列表,我正在使用seleniumwebdriver来抓取数据。我的问题是,鞋的图像似乎需要一段时间才能加载,因此它会抛出很多错误。我在图像的xpath中找到了模式。第一个图像的xpa
-
使用xpath中的start with和end函数查找selenium元素
我试图提取所有这些标签,其类名符合正则表达式模式frag-0-0,frag-1-0等,从这个输入链接描述在这里 我正在尝试以下代码 这是我的回溯: 回溯(最近一次调用):文件“/home/ubuntu/workspace/vroniplag/vroni.py”,第116行,在op('Aaf')文件“/home/ubuntu/workspace/vroniplag/vroni.py”中,第101行,
-
在运行脚本的页面上查找XPath
我想用selenium来刮一个网页。检查页面并右键单击所建议的XPath属于不稳定类型(/html/body/table[2]/tbody/tr[1]/td/form/table/tbody/tr[2])。因此,我尝试了以下解决方案: 甚至 不要返回任何结果。但是,在本页的前面部分,我可以获得: 似乎在: 我再也无法到达任何元素。如何确定正确的XPath?建议脚本中的部分不可能解析。然而,我所追求
-
确认是否使用xpath编写注释
你能用这个网站做个例子吗?我想忽略有评论的帖子,只点击没有评论的帖子。 我试过了,但有一个错误。 我想点击一个还没有任何评论的帖子。我想跳过有评论的帖子。我还是个初学者。救救我。
-
如何在xpath中使用contains查找aria标签元素
我试图获取锚标记中的信息,但不是。我想从易趣上的几个卖家那里提取评级分数。在以下超文本标记语言代码中,您可以看到评级分数的位置。有没有一种方法可以不使用,因为从卖方更改为卖方而获得关于"BewerTungspunkteski"(德语的评级分数)的信息?这个例子中的评分是32。因为文本“BewerTungspunkteski”只在这一行,我想可以让它搜索这段文本,并提取带有这段文本的咏叹调标签。 这
-
Selenium的预期条件-等待xpath可用-我不知道如何在我的代码中键入它[duplicate]
我是Scott,对python还是有点陌生,仍在试图弄清楚它是如何工作的。。。英雄联盟 我有一个脚本,可以登录到一个网站进行工作,在几个对象上进行一些单击,然后根据单击的设置提取一个报告 我遇到的问题是,有时服务器很忙,所以出现问题需要不同的时间。。。在激活下拉菜单之前,某些项目无法单击。。。所以我需要脚本来等待每个对象的xpath变得可用 我不明白显式等待的用法 目前代码是UGLY与我的time
-
将值传递到Xpath表达式中
我目前正在写一个针对电子商务网站的测试。当用户搜索特定产品时,将返回项目列表。我希望做的是将一个特定的值(例如数字2)传递到我的测试场景中,在这一点上可以传递到我的XPath表达式(第n个子项),从而能够选择该项。 XPath不正确,不确定如何修复。如果有人能帮忙,我将不胜感激。 结果消息:给定的选择器//@class='itemContainer: nth-child(3)'无效或不会导致Web
-
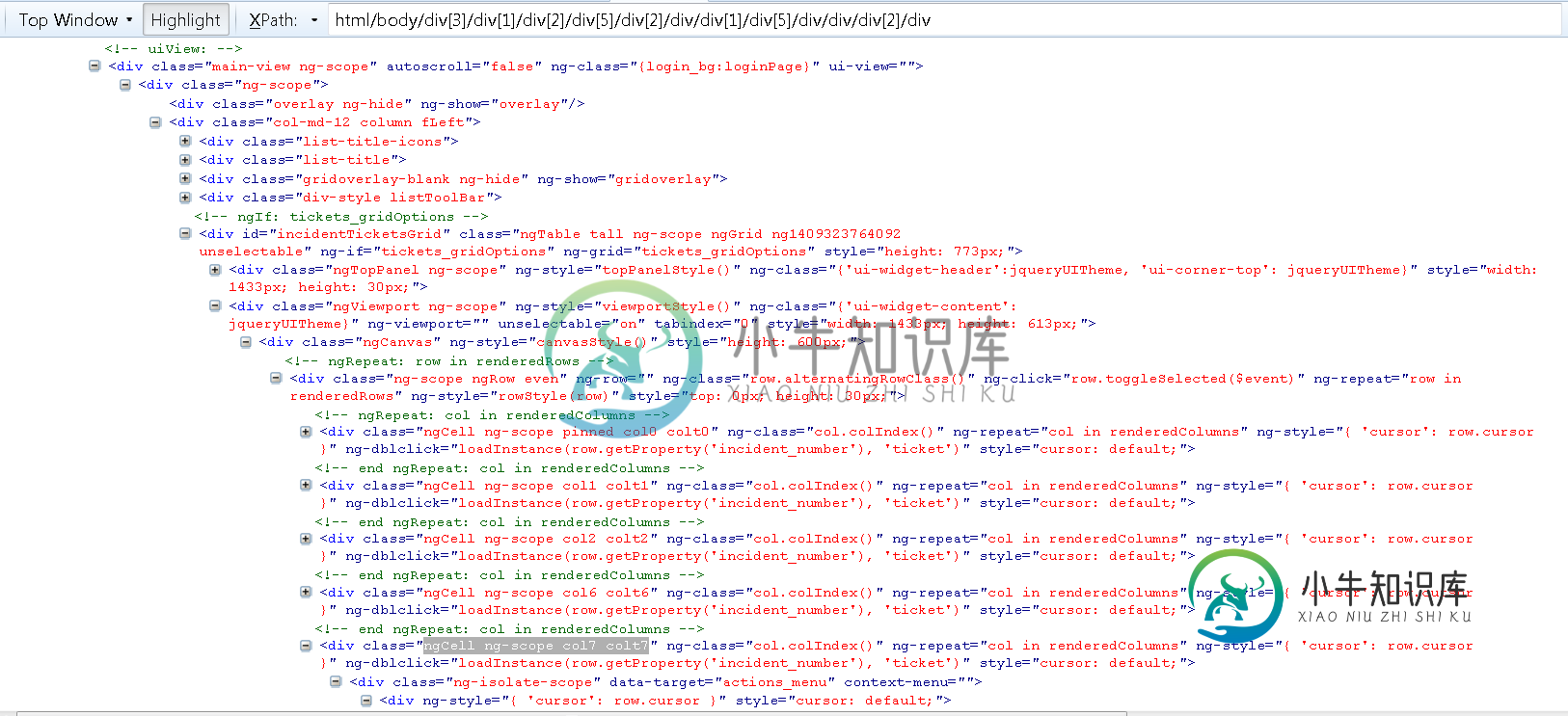 通过xpath获取webelement的文本
通过xpath获取webelement的文本我使用了以下代码, 这会引发错误“表达式不是合法表达式”。“代码:“12”nsresult:“0x805b0033(SyntaxError)”位置:”“]”。 当我缩小搜索范围到 它工作正常,我得到了特定行中的所有文本。然而,当我将其扩展到特定于第1个代码中所示的列时,我得到了错误。 html代码段,
-
Xpath使用匹配项和正则表达式在Xpath测试器中工作,但在代码抛出中InvalidSelectorException未能在“文档”上执行“评估”
超文本标记语言 要搜索的字符串 Xpath表达式 例外 组织。openqa。硒。InvalidSelectorException:选择器无效:无法找到xpath表达式为//b[匹配(text(),“[0-9]{10},[A-Za-z]”的元素,因为出现以下错误:语法错误:未能对“文档”执行“evaluate”:字符串“//b[匹配(text(),“[0-9]{10},[A-Za-z]”)不是有效的