《xpath》专题
-
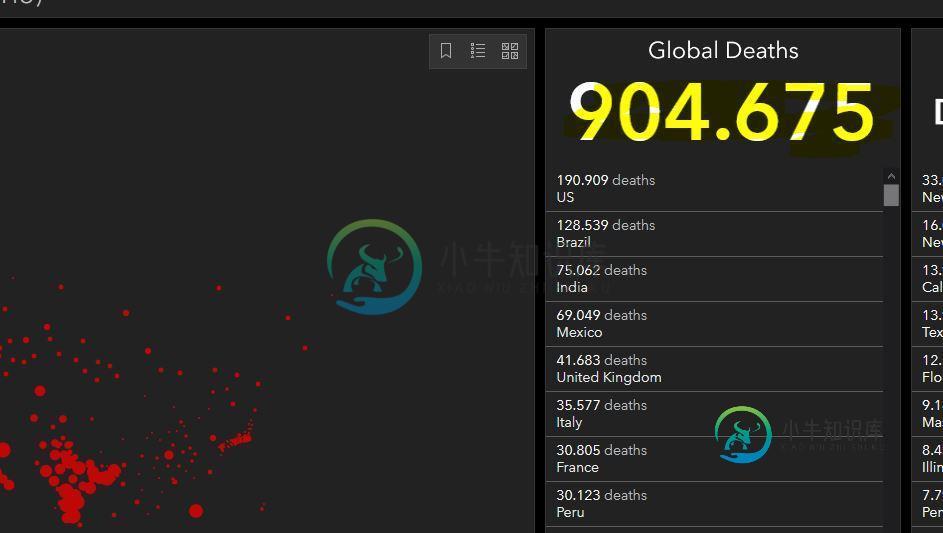 使用Selenium/XPath/Python抓取文本
使用Selenium/XPath/Python抓取文本我想从约翰·霍普金斯大学的新冠病毒仪表盘中找出死亡总人数。我想使用Selenium、Python和Selenium的chrome驱动程序来实现这一点。死亡人数可在路径下找到。 这是我的剧本: 它失败,错误为“无此类元素: 这种情况也发生在其他我正在努力抓取的网站上。 我怎样才能解决这个问题?这个错误的原因是什么?
-
流式XPath评估
问题内容: 是否有任何针对生产的准备就绪的库,用于针对提供的xml文档流XPath表达式评估?我的调查表明,大多数现有解决方案都在评估xpath表达式之前将整个DOM树加载到内存中。 问题答案: 鉴于XPath语法允许:对于完整的XPath实现,这是否可行? 和 这意味着提前要求?也就是说,无论如何,从特定节点开始,您都将不得不加载文档的其余部分。 Nux库(特别是StreamingPathFil
-
我正在使用哪个版本的XPATH和XSLT?
问题内容: 如何知道我正在使用哪个版本的XPATH和XSLT? 假设我已经安装了JDK 1.7,那么我具有哪个版本的XPATH和XSLT。 问题答案: 在XSLT中,调用。它将返回1.0或2.0,具体取决于您使用的是1.0还是2.0处理器。 在XPath中,没有直接的等效项。但是快速测试是不带任何参数的调用。如果成功,则您有2.0处理器,如果失败,则您有1.0处理器。 除非您采取措施在类路径或认可
-
在Java中使用SAXON Xpath引擎
问题内容: 这是我的代码: 我得到这个: 这意味着当我通过明确创建工厂时,Java正在使用类。 (实际上,我只需要在xpaths中放置一些…因此,如果知道不涉及Saxon的任何解决方案,请考虑达到了我的需要)。 我究竟做错了什么 ? 问题答案: 从撒克逊人的例子: 工作良好。
-
如何使用包含Java中名称空间的XPath检索XML数据?
问题内容: 我知道此页面中有很多此主题,但可悲的是,我仍然无法解决我的问题。 这是我的xml代码: 这是我在Java中的代码: 是的,像往常一样,我无法获得输出,因为它仅显示: 仅当我删除ns:1时,才会显示输出,xml的代码将如下所示: 问题是,我在网上发现的所有建议似乎都没有用: 例如,我已经尝试过 等2 .. 我能得到的唯一最好的输出是,它将显示: 谁能给我正确的代码给我解决我的问题? 提前
-
XPath为带有defaultNamespace的xml返回null
问题内容: 我相信它在某个时候可以工作,但是现在xpath返回null。有人可以帮助我在以下代码中找到我的愚蠢错误吗? 还是即使在setNamespaceAware(false)之后也必须提供NamespaceContext? XML文档在这里: 问题答案: 三个选择是显而易见的。按照我的观点,最简单的顺序是: 将XPath从更改为。有点笨拙,但它将忽略名称空间。如果仍然为您提供零,则说明问题不在
-
XPath,XML命名空间和Java
问题内容: 我花了整整一天的时间尝试从以下文档中提取一个XML节点,并且无法掌握XML命名空间的细微差别以使其正常工作。 XML文件总的来说很大,所以这是与我有关的部分: 该文档继续进行,并且从头到尾都井井有条。我正在尝试从“ documentnbr”标签(底部的三个)中提取“ number”属性。 我用于执行此操作的代码如下所示: 其中QUERY_FORM_NUMBER是我的XPath表达式,而
-
Java XPath:使用默认名称空间xmlns的查询
问题内容: 我要对此文件执行XPath查询(显示的摘录): 这是我正在使用的代码的摘要: 我面临的问题是,在XPath查询中引用默认名称空间时,不会调用getNamespaceURI方法来解决它。例如,此查询不提取任何内容: 现在,我尝试通过用假前缀替换来“诱骗”解析器,然后相应地编写方法(以便在遇到问题时返回)。在这种情况下,将调用,但是XPath表达式求值的结果始终是一个空字符串。 如果我从文
-
JAVA-如何在硒中使用xpath
问题内容: 我有这个HTML代码: 而且我必须选择带有text 的标签所标识的WebElement 。我尝试一些解决方案,例如: 但是每个人都给我: 正确的语法是什么?有人能帮我吗? 问题答案: 您没有正确的XPath语法。您需要在要匹配的文本属性值周围加上引号。尝试:
-
等待页面元素(xpath)在Selenium Webdriver中显示的最有效方法是什么?
问题内容: 我正在使用Java和Selenium Webdriver来测试单页Web应用程序的功能。 因此,很明显,元素是动态注入和从DOM中删除的。 我知道我可以使用使用WebDriverWait的类似代码等待元素出现在DOM中(我写的非常整洁的模板稍微改变了GitHub): 我想知道的是,这是否也是使用xpath获得此类结果的更有效方法。 感谢您的时间和帮助。 问题答案: 您需要考虑以下两个事
-
从XPath表达式填充XML模板文件?
问题内容: 从XPath表达式的映射填充(或生成)XML模板文件的最佳方法是什么? 要求是我们需要从模板开始(因为它可能包含XPath表达式中未捕获的信息)。 例如,起始模板可能是: 然后提供给我们,类似于: 然后,我们应该生成: 我是用Java实现的,尽管如果可能的话,我会首选基于XSLT的解决方案。 问题答案: 此转换从“表达式”创建具有所需结果结构的XML文档-仍需将其转换为最终结果: 当此
-
如何从一组XPath表达式生成XML文件?
问题内容: 给定一组XPath映射,我希望能够生成一个完整的XML文件。 输入可以在两个映射中指定:(1)列出XPath表达式和值的映射;(2)另一个定义了适当的名称空间。 对于命名空间: 还要注意,同样重要的是,我还必须处理XPath Attributes 表达式。例如:我也应该能够处理属性,例如: 最终输出应如下所示: PS:这是对先前提出的问题的更详细的问题,尽管由于一系列进一步的要求和说明
-
python使用xpath中遇到:到底是什么?
本文向大家介绍python使用xpath中遇到: 到底是什么?,包括了python使用xpath中遇到: 到底是什么?的使用技巧和注意事项,需要的朋友参考一下 前言 大家在学习python爬虫的过程中,会发现一个问题,语法我看完了,说的也很详细,我也认真看了,爬虫还是不会写,或者没有思路,所以我的所有文章都会从实例的角度来解析一些常见的问题和报错。下面话不多说了,来一起看看详细的介绍吧。 Elem
-
 Python自动化xpath实现自动抢票抢货
Python自动化xpath实现自动抢票抢货本文向大家介绍Python自动化xpath实现自动抢票抢货,包括了Python自动化xpath实现自动抢票抢货的使用技巧和注意事项,需要的朋友参考一下 小伙伴们,这次推文讲的是‘xpath‘,掌握起来不难的哦。而且,熟悉了这套路,别说pubmed,任何你能在浏览器实现的操作,都基本能通过selenium自动化进行。 总代码: 代码1 for i in range(1,50+1): printg('
-
Python:在本地/在特定元素上使用xpath
问题内容: 我正在尝试从具有xpath的页面获取链接。问题是我只希望表内的链接,但是如果我在整个页面上应用xpath表达式,则会捕获不需要的链接。 例如: 问题是将表达式应用于整个文档。我找到了想要的元素,例如: 但这似乎也在整个文档中执行查询,因为我仍在捕获表外的链接。该页面说:“在元素上使用xpath()时,将根据元素(如果是相对的)或根树(如果是绝对的)来评估XPath表达式:”。因此,我使