
使用Selenium/XPath/Python抓取文本

我想从约翰·霍普金斯大学的新冠病毒仪表盘中找出死亡总人数。我想使用Selenium、Python和Selenium的chrome驱动程序来实现这一点。死亡人数可在路径/*[@id=“ember1915”]/svg/g[2]/svg/text下找到。
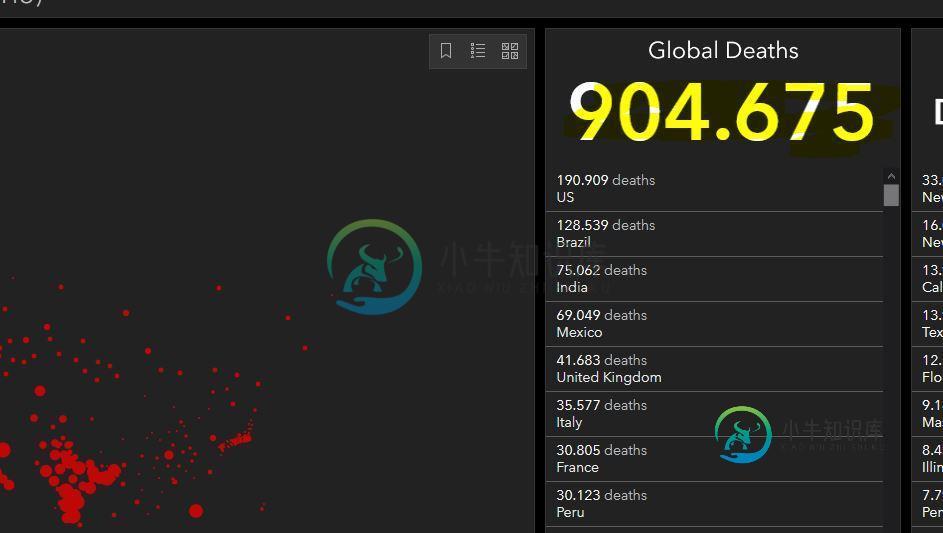
这是我的剧本:
from selenium.webdriver import Chrome
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
with Chrome() as driver:
driver.get('https://coronavirus.jhu.edu/map.html')
driver.implicitly_wait(20) # Waits for 20 s for the entire page to loads.
diplayElement = driver.find_element_by_xpath('//*[@id="ember1915"]/svg/g[2]/svg/text')
它失败,错误为“无此类元素:
Unable to locate element: {"method":"xpath","selector":"//*[@id="ember1915"]/svg/g[2]/svg/text"}”.
这种情况也发生在其他我正在努力抓取的网站上。
我怎样才能解决这个问题?这个错误的原因是什么?
共有1个答案

约翰·霍普金斯新冠病毒仪表盘中的死亡总数元素(即905181)在
>
诱导WebDriver等待visibility_of_element_located(),您可以使用以下定位器策略之一:
>
driver.get('https://coronavirus.jhu.edu/map.html')
WebDriverWait(driver, 20).until(EC.frame_to_be_available_and_switch_to_it((By.XPATH,"//iframe[@title='Coronavirus COVID-19 Global Cases by Johns Hopkins CSSE']")))
print(WebDriverWait(driver, 60).until(EC.visibility_of_element_located((By.XPATH, "//*[name()='svg']/*[name()='text' and text()='Global Deaths']//following::div[1]/*[name()='svg' and @class='responsive-text-group']//*[name()='g' and @class='responsive-text-label']/*[name()='svg']/*[name()='text']"))).get_attribute("innerHTML"))
使用XPATH和文本属性:
driver.get('https://coronavirus.jhu.edu/map.html')
WebDriverWait(driver, 20).until(EC.frame_to_be_available_and_switch_to_it((By.XPATH,"//iframe[@title='Coronavirus COVID-19 Global Cases by Johns Hopkins CSSE']")))
print(WebDriverWait(driver, 60).until(EC.visibility_of_element_located((By.XPATH, "//*[name()='svg']/*[name()='text' and text()='Global Deaths']//following::div[1]/*[name()='svg']//*[name()='g']/*[name()='svg']/*[name()='text']"))).text)
控制台输出:
905,181
注意:您必须添加以下导入:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
您可以找到有关如何使用Selenium-Python检索WebElement文本的相关讨论
您可以在以下网站找到一些相关讨论:
iframe下#文档的处理方法- 通过Selenium和python切换到iframe
- iframe下#文档的处理方法
- 通过Selenium和python切换到iframe
-
我尝试使用 在此输入图像描述 如果我打印出来,我会得到: 我想:“荷兰人在中国的问题。”
-
问题内容: 在网站上,有在标顶部的几个环节,,,和。如果按下以数字标记的链接,它将动态地将一些数据加载到content中。如果被按下,它会用标签页,,,和第4页中的数据显示。 我想从按下的所有链接的内容中抓取数据(我不知道有多少,一次只显示3个,然后) 请举一个例子。例如,考虑网站www.cnet.com。 请指导我下载使用selenium的一系列页面,并自行解析它们以处理漂亮的汤。 问题答案:
-
我在Firefox中使用Firebug为没有分配ID的链接获取xpath。该链接是一个带有图像作为实际按钮的javascript链接。我希望能够单击此链接,但它不起作用。 实际的xpath是'/html/body/div[2]/div/div/div[3]/div/div/table/tbody/tr[1]/td[2]/form/table/tbody/tr[1]/td/div[1]/div/ta
-
正如标题所示,我正在尝试使用Selenium从网站(示例)中获取一些数据,但是我在从Pro结果表中获取隐藏在每一行中的数据时遇到了问题,即单击Show Details按钮()时显示的数据。 这是我的代码: 正如您所看到的,我可以很容易地获取表中的行,但是当我试图获取隐藏数据时,我就是找不到获取它的方法。 我对Selenium也不是很熟悉,所以欢迎提供任何指导。
-
问题内容: 我正在使用selenium通过xpath在网页上获取一些文本。 页面标签结构如下- 如果我使用以下代码- 我得到结果= 但我想避免阅读标签内的文本并获得结果 请让我知道我可以使用哪个xpath表达式来获得所需的结果。 问题答案: 我不知道在Selenium中执行此操作的任何方法,因此有我的JS解决方案。想法是获取元素的所有子级(包括文本节点),然后仅选择文本节点。您可能需要添加一些(或
-
我尝试获取标题中包含一些单词的链接,但不包含一些单词,我使用以下代码,但它表示这不是有效的XPath表达式。 请在此处找到我的代码: 任何帮助将不胜感激!