
python-xpath获取html文档的部分内容

有些时候我在们需要的用正则提取出html中某一个部分的文字内容,如图:
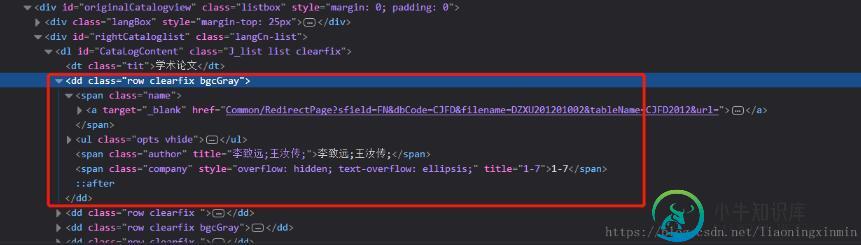
获取dd部分的html文档,我们要通过它的一个属性去确定他的位置才可以拿到他这个部分我们可以看到他的这个属性class='row clearfix ',然后用xpath去获取到这部分:
name = tree.xpath("//dd[@class='row clearfix ']")
from lxml import html
import requests
url = 'http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pageIdx=0&pcode=CJFD'
res = requests.get(url)
tree = html.fromstring(res.text)
name = tree.xpath("//dd[@class='row clearfix ']")
print(name)
如果直接打印他是不能够出来的,

我们需要对Element进行处理,用到name1 = html.tostring(name[0]),代码如下:
from lxml import html
import requests
url = 'http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pageIdx=0&pcode=CJFD'
res = requests.get(url)
tree = html.fromstring(res.text)
name = tree.xpath("//dd[@class='row clearfix ']")
name1 = html.tostring(name[0])
print(name1)
打印截图:

但是大家可以看到里面的等内容并不是中文,原因是我们使用tostring方法输出的是修正后的HTML代码,但是结果是bytes类型,在python中bytes类型是不可以进行编码的,需要转换成字符串,使用代码name1.decode(),此时我们将bytes类型转换为str(字符串)类型。
那么此时我们关键是如何将$#26080;此类的符号转换成汉字!!!那么首先要搞清楚这是什么编码?这类符号是HTML、XML 等 SGML 类语言的转义序列。它们不是”编码“,也就是说我们不能使用utf-8、gbk等编码进行处理,需要使用HTMLParse进行处理,完整代码如下:
from lxml import html
import requests
from html.parser import HTMLParser #导入html解析库
url = 'http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pageIdx=0&pcode=CJFD'
res = requests.get(url)
tree = html.fromstring(res.text)
name = tree.xpath("//dd[@class='row clearfix ']")
name1 = html.tostring(name[0])
name2 = HTMLParser().unescape(name1.decode())
print(name2)
此时运行结果如下:

那么此时就已经大功告成了!!!
以上这篇python-xpath获取html文档的部分内容就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
问题内容: 我想对返回HTML的页面进行AJAX调用,提取HTML的一部分(使用jQuery选择器),然后在基于jQuery的JavaScript中使用该部分。 在AJAX检索是非常简单的。这使我在回调函数的“数据”参数中获得了整个HTML文档。 我不明白的是如何以一种有用的方式处理这些数据。我想将其包装在新的jQuery对象中,然后使用选择器(通过我相信的find())来获取我想要的部分。有了这
-
本文向大家介绍python的xpath获取div标签内html内容,实现innerhtml功能的方法,包括了python的xpath获取div标签内html内容,实现innerhtml功能的方法的使用技巧和注意事项,需要的朋友参考一下 python的xpath没有获取div标签内html内容的功能,也就是获取div或a标签中的innerhtml,写了个小程序实现一下: 源代码 运行代码 以上这篇p
-
问题内容: 我正在尝试学习一些漂亮的汤,并从一些iFrame中获取一些html数据-但到目前为止,我还没有取得很大的成功。 因此,解析iFrame本身似乎不是BS4的问题,但是我似乎并没有从中获得嵌入的内容-不管我做什么。 例如,考虑下面的iFrame(这是我在chrome开发人员工具上看到的): 我要提取的内容在哪里。 但是,当我使用以下BS4代码时: 我得到: 换句话说,我得到的iFrame中
-
我是XPath的新手,如果这是一个愚蠢的问题,我很抱歉。我只需要从第一个span class=“price”中提取一个没有“$”的价格。 我附带的Xpath是
-
在我的Spring Boot/Spring Data MongoDB项目中,我有以下POJO: 其中: 是一个复合对象数组,例如: 我做错了什么?如何调整代码,以便在包含数据的情况下,通过正确查找文档。 更新 这是一个示例文档,我将使用它作为键(在UI上选择的每个用户每次该文档中的信息都不同):
-
问题内容: 我目前从Python开始,我有很强的PHP背景,在PHP中,我习惯于用作文档模板。 我想知道它是否在Python文档中占有一席之地。 这里有哪些既定的公约和/或官方指南? 例如,类似这样的内容太复杂而无法适应Python的思维方式,还是我应该尽量简洁一些? 而且,如果我有点过于详尽,我应该改用类似的东西(大多数文档都无法通过该方法打印)吗? 问题答案: 看一下reStructuredT