《opencv》专题
-
在python OpenCV中未打开图像[重复]
我尝试在python(3.6)OpenCV2最新版本中运行简单的代码。但是当我想使用cv2.imshow()显示图像时,图像没有打开。并显示一个空窗口。 这是输出。为了简单起见,我将图像与代码放在同一个文件夹中,但它不起作用。而且也没有错误。我正在使用“Spyder”ide编写代码。代码如下,
-
 Android-OpenCV错误:无法加载OpenCV的信息库
Android-OpenCV错误:无法加载OpenCV的信息库我已经在Android Studio(https://www.learn2crack.com/2016/03/setup-opencv-sdk-android-studio.html)中安装了OpenCV SDK,但似乎我收到了这种错误消息。 我已经将包含到文件夹中。
-
OpenCV示例项目中作为参数传递图像文件
-
使用opencv生成全景的图像拼接
现在,我正在用opencv做实验,将几张图像拼接到一个全景图中,但是这些照片是在不同的角度拍摄的。现在我想做的是将所有图像投影到圆柱形表面上,然后使用SIFT匹配特征以获得变换矩阵。我应该怎么做?opencv有什么界面可以做到这一点(将所有图像投影到圆柱形表面上,我不知道相机的任何参数)?
-
面向OpenCV的groupRectangles的Mex
我使用的是matlab中的mexopencv,但是我注意到groupRectangles matlab包装器只支持3个输入参数,而源代码有3个不同的版本。 我不懂C++,但我试图遵循指导方针和编写的代码,但我无法编译它;它给出了一个奇怪的错误。 我们想要得到分组矩形的分数,文档中的groupRectangles变体对我们没有帮助。我们必须使用第三个,将rejectLevels设置为零:vector
-
unsatisfiedLinkError opencv TESS-两个库?
我已经下载了这个项目:https://github.com/jhansireddy/androidscannerdemo它使用OpenCV并且工作非常好,它所做的是扫描一张用手机摄像头(或者从图库中)拍摄的照片并扫描它。我的目的是OCR,所以我把tess-two作为一个模块,添加了依赖项并构建了项目,在这一点上我没有得到一个错误。但当我运行它时,logcat显示如下: 在搜索的过程中,我发现这个问
-
与MATLAB相比,OpenCV从视频文件中提取的帧数更少
我有一个AVI视频,我需要处理在C++使用OpenCV。问题是OpenCV检测到的FrameRate为30,而在Matlab中,视频阅读器对相同的视频文件检测到的FrameRate为60。因此,与Matlab相比,C++只能提取一半的帧。 我尝试在C++中使用CV::VideoCapture::Set(CV::CAP_PROP_FPS)将FPS设置为60,但这并不影响它。我读到它也与视频捕获后端有
-
 如何使用python和OpenCV从。yuv视频文件(YUV420)中提取帧?
如何使用python和OpenCV从。yuv视频文件(YUV420)中提取帧?我需要读取一个yuv视频文件,从中提取单个帧,将其转换为灰度,然后计算相邻帧之间的卢卡斯·卡纳德光流。我最初使用的是mp4视频,这是我提取单个帧的代码: 现在有些事情改变了,我不得不使用yuv视频文件的数据集。但是当我给VideoCapture()一个yuv文件时,我会得到如下错误: [IMGUTILS@00000078A4Bee5C0]图片大小0x0无效[错误:0]全局C:\projects\o
-
如何使用openCV python改变现有视频的帧率FPS
我试图改变帧率,即使用Python中的openCV库现有视频的FPS。下面是我试图执行的代码。即使使用设置了FPS属性,视频在方法中的播放速度也不会更快。即使在设置了FPS属性之后,getter也会返回旧的FPS值。那么我如何将FPS值设置得更高,让视频播放得更快呢? 使用版本:python=3.7.4和opencv-python-4.1.0.25
-
如何在Android中使用OpenCv+Tesseract进行准确的文本识别?
我试图使用OpenCV(Android)处理使用相机拍摄的图像,然后将其传递给Tesseract进行文本(数字)识别,但在图像非常(几乎没有噪声)罚款之前,我没有得到很好的结果。目前我正在对拍摄的图像执行以下处理:1。应用高斯模糊。2.自适应阈值:对图像进行二值化。3.倒置颜色使背景变黑。然后将处理后的图像传递给Tesseract。 但我没有得到好的结果。
-
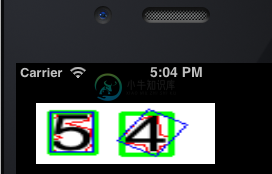 iOS+Tesseract Ocr+OpenCV
iOS+Tesseract Ocr+OpenCV我为iOS写了一个数字OCR。我有一个测试图像png与两位数5和4。我找到轮廓了。我如何在Tesseract转乘等高线? 初始化tesseract: 用于检测轮廓的函数: GitHub项目链接:https://github.com/maxpatsy/iorc
-
 做OCR前的预处理(tesseract,OpenCV)
做OCR前的预处理(tesseract,OpenCV)为了用OCR库tesseract获得更好的结果,我会做一些预处理,但还不知道什么步骤可以帮助我。 我试图用15因子调整图像的大小,并应用了一个适应的阈值(见图像),但这导致了“波浪”字符,这无法用tesseract OCR库检测到。在底部,你可以通过Dropbox找到我的图像链接。原始图像大小为115x18px,字符高度为10px。 我想从背景中提取人物。什么步骤可以导致更好的结果?对于OCR部分
-
基于OpenCV的车牌识别
问题是,当我在另一个系统(Ubuntu12.04,32位)中设置相同的工作代码时,在配置OpenCV和Tesseract后,它在制作项目时产生了以下错误 错误是
-
视频中的OCR?openCV还是OCR图像处理?
我必须写一个程序,从一个从屏幕上拍摄的视频在司机面前的汽车,所以它只对数字进行OCR。我正在努力寻找实现它的方法。我在考虑使用openCV,但作为替代方案,我在考虑使用一个OCR程序,从视频中提取帧并找到数字。但是许多OCR程序不能正确地识别数字(也许OCR需要训练?)。所以我想用计算机视觉库来完成这项工作。 你认为实施这个简单程序的最佳方法是什么? 我想使用计算机视觉库和匹配的模板会很好,但也可
-
OpenCv/FFMPEG图像捕获问题
我正试图从IP摄像机实时捕捉图像。该流在VLC中工作得非常好,但是OpenCV的似乎混淆并损坏了传入的图像,以至于无法识别。 同样,从文件捕获工作很好,但不是实时流。如果它有不同,我使用rtsp连接URL;我也尝试了两个不同型号的相机(不同品牌),问题仍然存在。 此外,(我假设)编解码器正在输出以下几种错误:和。 我能做什么?