《apache》专题
-
Apache Spark2.1中缺少LinearSVC?Spark2.2中的非线性核?
能否请你证实(或反驳)以下两种说法? null
-
Apache Spark:核心与执行器
Apache Spark:核心数与执行器数 由于每个案例都不一样,我又问了一个类似的问题。 我正在运行一个cpu密集型的应用程序,具有相同数量的核心和不同的执行器。以下是观察结果。 更新 案例3:执行器-12个,每个执行器的核心数-1个,执行器内存-3个,数据处理量-10 GB,分区-36个,作业持续时间:81分钟
-
如何使用Apache Spark kmeans对SIFT描述符进行集群(是否通过pickle)
酸洗是传输描述符数据的最佳方式 如何从一组pickle文件到一个集群就绪的数据集,以及应该注意哪些陷阱(Sark、pickling、SIFT) 我感兴趣的是假设描述符生成代码和集群环境之间有一些公共存储,python 2代码的序列会是什么样子
-
Apache Spark k-均值聚类-RDD用于输入
该向量包含X、Y坐标,即成对的双打。我想为每个用户ID标识坐标集群,所以我在RDD上进行映射,并尝试为每个组运行k-means: 但是当我运行这个时,我从一行中得到了一个NPE: 问题是,我必须将coords转换为RDD来进行K-Means操作。
-
如何在ApacheFlink中为会话窗口分配id?
如何在ApacheFlink中为会话窗口分配id? 最后,我希望在会话窗口打开时,使用会话窗口id逐个充实事件(我不希望等到窗口关闭后再发出充实事件)。 我尝试使用AggregateFunction来实现这一点,但是我认为merge()并没有像我所期望的那样工作。它似乎是用于合并窗口而不是窗格(触发触发)。在我的管道中似乎从未调用过它。因此,触发器之间似乎没有共享状态! 会话窗口ID将是落入窗口的
-
Apache flink从后期窗口访问键控状态
我正在编写一个Flink应用程序,它使用kafka主题中的时间序列数据。时间序列数据包含度量名称、标记键值对、时间戳和值等组件。我已经创建了一个滚动窗口来根据度量键(度量名称、键值对和时间戳的组合)聚合数据。这里是主流看起来像 我还想检查是否有任何指标在上面的窗口外迟到。我想检查有多少指标延迟到达,并计算延迟指标与原始指标相比的百分比。我正在考虑使用flink的“允许延迟”功能将延迟指标发送到不同
-
ApacheFlink-基于事件时间计算最后一个窗口
我的工作是做以下事情: 根据事件时间使用Kafka主题中的事件 计算7天的窗口大小,以1天的幻灯片显示 将结果放入Redis 我有几个问题: 如果它从最近的记录中消耗Kafka事件,在作业存活1天后,作业关闭窗口并计算7天窗口。问题是作业只有1天的数据,因此结果是错误的。 如果我尝试让它从7天前的时间戳中消耗Kafka事件,当作业开始时,它从第一天开始计算整个窗口,并且花费了很多时间。另外,我只想
-
ApacheFlink-如何将AssignerWithPeriodicWatermark和AssignerWithPeriodicWatermark结合起来?
Usecase:使用EventTime并从Kafka的记录中提取时间戳。 我想要的是:Flink提取时间戳并在初始间隔(例如20秒)内为每条记录发出水印,然后它可以周期性地发出水印(例如每10秒)。 原因:如果我使用PeriodicWatermark,开始时Flink只会在一段时间间隔后发出水印,并且我的第一个窗口(5分钟)中的计数是错误的-比后续窗口中的计数大得多。我有一个解决办法,将自动水印间
-
Apache Flink:状态反序列化/序列化的频率是多少?
Flink去/序列化操作员状态的频率是多少?每次获取/更新或基于检查点?状态后端有什么不同吗? 我怀疑,对于具有不同键(数百万)和每个键每秒数千个事件的键控流,去/序列化可能是一个大问题。我说得对吗?
-
ApacheFlink:窗口函数和时间的开始
在中,元素被分配给一个或多个实例。在滑动事件时间窗口的情况下,这发生在1中。 如果窗口的和,则将时间戳为0的元素分配到以下窗口: 窗口(开始=0,结束=5) 窗口(开始=-1,结束=4) 窗口(开始=-2,结束=3) 窗口(开始=-3,结束=2) 窗口(开始=-4,结束=1) 在一幅图片中: 有没有办法告诉Flink时间有开始,而在那之前,没有窗户?如果没有,从哪里开始寻求改变?在上述情况下,Fl
-
Apache对水印空闲的模糊理解及其与有限持续时间和窗口持续时间的关系
我有一个配置了Kafka连接器的Flink管道。 我已使用以下方法将水印生成频率设置为2秒: 现在,对于流窗口,我的翻滚窗口是60秒,我们在其中进行一些聚合,并且基于一个数据字段的时间戳进行基于事件时间的处理。 我没有为我的水印策略或我的流配置允许延迟。 Q.1根据我所读到的,我的时间0-60的窗口将在90秒后计算,30-90在120秒后计算,以此类推。然而,因为我们在做翻转窗口,即没有重叠,我猜
-
窗口操作符行为澄清后的Apache Flink KeyedStream
我要求澄清Apache Flink(1.6.0)在事件通过窗口发送并应用了一些运算符(如减少()或过程())后,如何处理来自KeyedStreams的事件。 假设一个单节点集群,在执行键控窗口流上的一个操作符后,剩下的是正好1个数据流还是正好k个数据流(其中k是键的唯一值的数量)? 为了澄清,考虑需要从某个源读取事件,通过一些K键,将键事件发送到一些窗口流,减少,然后做几乎任何其他事情。下面两个图
-
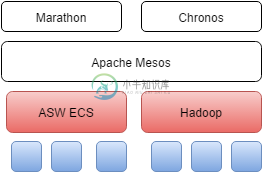 EC2容器服务vs Apache Mesos
EC2容器服务vs Apache Mesos我们希望使用Docker容器在集群环境中运行我们的批处理作业。我们正在评估使用AWS ECS容器服务/Chronos/Mesos。据我所知,Apache Mesos与EC2有一些重叠的特性/用途,比如集群管理。Chronos是一个分布式调度程序。 我有dificult关联所有这些技术来创建一个架构! EC2服务取代Mesos?调度器呢? 目前,我们还没有运行分布式作业,比如hadoop作业或spa
-
Apache Mesos、Mesosphere和DCOS有什么区别?
DCOS是Mesosphere的免费版本,就像RedHat vs RedHat Enterprise?
-
Apache Mesos的持久存储
最近我发现了一个像Apache Mesos这样的东西。 在所有演示和示例中,这一切看起来都令人惊讶。我可以很容易地想象一个人将如何竞选无状态的工作--这自然符合整个想法。 3-请告诉我的方法在哲学方面是否是错误的(数据服务器的DFS和Mesos顶部的postgres之类的服务器的某种切换) 问题主要是从Apache Mesos的持久存储中复制的,由程序员堆栈交换上的zerkms提出。